
Measure twice, cut once – understanding the requirements.
This is the first of a series of posts where we’ll talk about architecture and implementation principles we’ve followed when building Cribl Stream to be able to scale to processes 10s of Petabytes per day and at sub-millisecond latency. First, in this post, we’ll discuss one of the most important aspects of designing any system: getting the requirements right. Many projects and products start first from the wrong requirements and end up at the wrong destination. At Cribl, we endeavor to deeply understand the requirements of our customers and build a product which meets them. The follow on posts will dive deeper into our scale up and scale out architecture and implementation decisions.
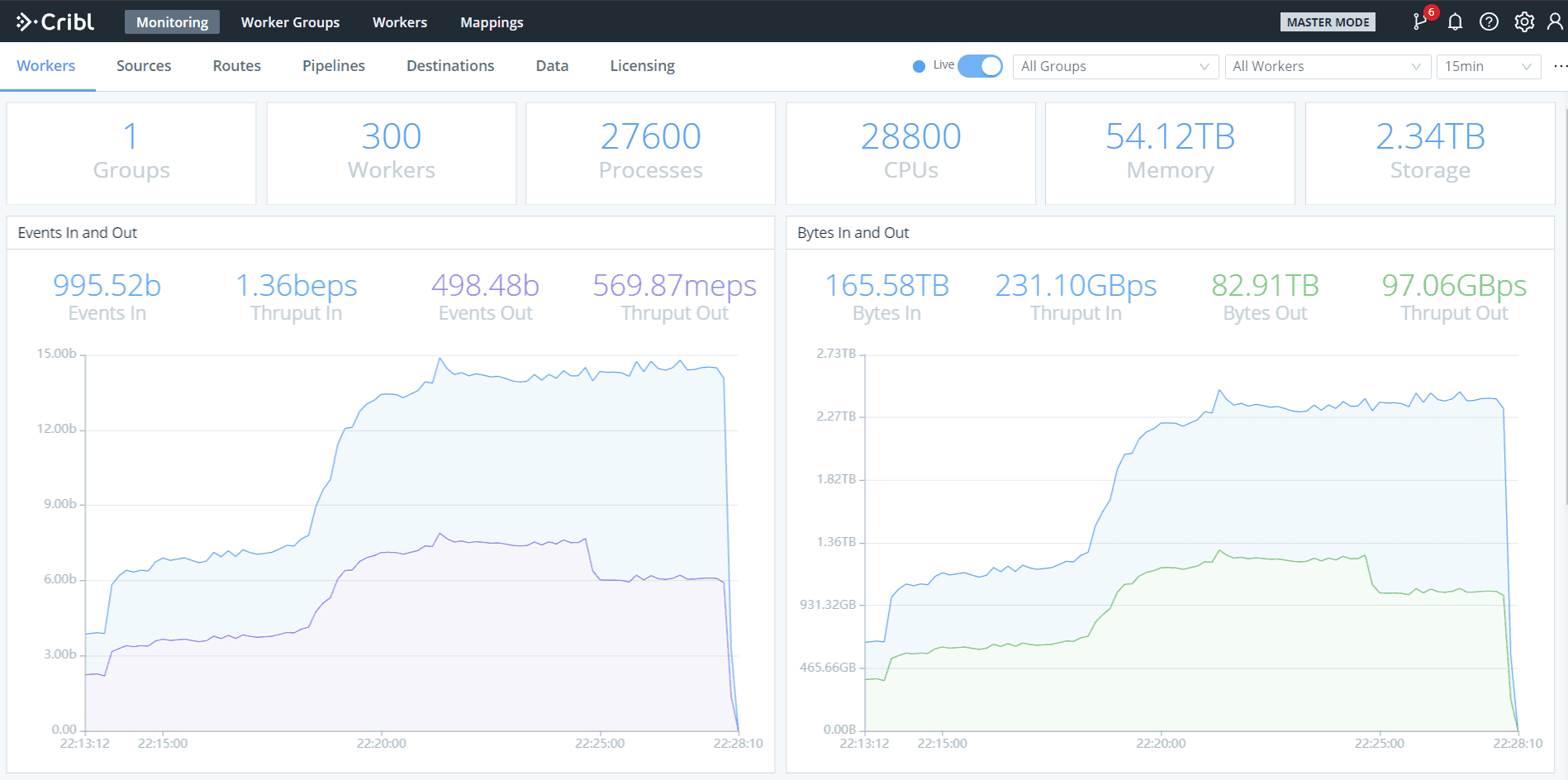
The screenshot below is from our out of the box monitoring and shows a 300 node Cribl Stream deployment processing data at a rate of 117 trillion events per day, or about 20PB per day. The bumps in throughput around 22:14 and 22:18 are due to the cluster scaling out from 100 to 150 to 300 nodes.
Why does Petabyte scale and sub-millisecond latency matter?
Cribl Stream is the first streams processing engine built for logs and metrics. The growth trajectory of these types of data has been exponential for quite some time. The rise in popularity of microservices architectures as well as the number of devices coming online has caused a dramatic increase in the number of endpoints emitting logs, metrics and traces (aka machine data). We are working with customers and prospects who are already at multi-Petabyte/day scale, and we believe customers are only prospecting a small fraction of the potentially valuable raw data.
For a machine data streams processing engine being able to scale to process Petabytes of data per day is simply table stakes. Handling such volumes of data is only economically feasible if done in an efficient manner: thus the need to be able to process 10-100s of thousands of events per second per CPU core, which we can also state as sub-millisecond per event latency.
Seamless experience
In order to process data volumes at such scale, reliability and resiliency the system must be distributed. However, there’s also a requirement for the system to be able to scale way down. The first time users experience our product is likely to be on their laptop or in dev/test environment. This way users can easily try out the system and gain confidence and expertise before moving on to production.
We believe that a system’s usability and scale are orthogonal problems: users shouldn’t have to care that a system is distributed. From an engineering point of view this means the UX for single instance and distributed mode must be as similar as possible. Let’s look at scaling as it covers some terminology and fundamental concepts used to solve this problem, which we’ll cover in more details in the next post.
Scaling and manageability
There are two scaling dimensions to consider when designing a system for high resource efficiency:
Scale out – ability to add more hosts/nodes/instances to handle increased load
Scale up – ability to consume all the resources inside a host to handle increased load
Scale out generally receives most of the attention because of the theoretical ability to scale a system to infinity. However, as the number of nodes in a distributed system increases, so does the complexity of the control/management plane. We view scale up just as important, because it has the unique potential to reduce the size of a distributed system by one to two orders of magnitude, a non-trivial reduction! We designed LogStream to scale in both dimensions, with users being able to specify a resource cap per instance/node (consume N cores, or consume all but N cores).
Any distributed system must provide a control plane which users utilize to configure, manage and monitor the deployment, all of which are tightly dependent on the distributed architecture. We made a number of key design decisions when scaling out:
We chose one of the simplest and most resilient distributed architectures: shared nothing distributed architecture with a centralized master instance. The architecture can be described simply as: each worker node in the deployment acting completely independently and without knowledge of the existence of any nodes other than the master node.
All configuration settings and user changes be backed by version control, git in our case, with support for an optional remote repo where changes are pushed to.
The master node is out of the data path and is responsible for holding the master copy of the configuration and gathering of monitoring information, which can also be sent to other systems from the worker nodes. Losing the master node only affects the configurability of the system while worker nodes continue to process data with the last known config settings until the master comes back online. Recoverability of a master node is trivial when using a remote git repo for (2).
Workers can be grouped into logical management units, all accessed through the same master instance. This is necessary for large organizations with global presence that have different requirements and regulations for parts of their data pipeline.
Must not sacrifice UX for scale. Management and usability of a distributed version of our system should be as similar as possible to the single instance version. We’ve managed to achieve this by giving users the exact UX that is available for a single instance – ie the experience is the same as if they were interacting directly with one worker node. (more on how we achieved on the next blog post)
Coming Up Next
In this post we discussed why machine data streams processing engines should scale to processing petabytes of raw data per day with maximal resource efficiency and scale all the way down to work on a commodity laptop. Scaling is not a single dimension problem and we believe providing users a seamless experience independent of system’s scale is crucial for adoption.
In the next posts we dive deeper into scale discussing scale up and scale out, including many technical decisions and implementation details we made to achieve the requirements we discussed here. Read part 2 here.
One more thing, we’re hiring! If the problems above excite you, drop us a line at hello@cribl.io or better yet talk to us live by joining our Cribl Community.







