As CEO of Cribl, one of my greatest privileges is to spend time on the road and on calls with our customers hearing about their needs and challenges. Cribl is a focused company. We build software for observability and security. With this lens, it becomes clear the industry is neglecting to address the unique needs of our users. There are many reasons, most of which are simply that vendors tend to come at a user’s problem through the lens of their existing technology. A better approach is to ask, from first principles, can we invent fundamentally new approaches using the latest in technology and architecture to go after those problems in a unique way?
There is a consistent pain amongst nearly everyone I talk to: Data is everywhere. That data comes in many forms. For IT, SRE, DevOps, and Security teams, investigating a problem involves a lot of different types of data. The traditional three pillars of observability are metrics, logs, and traces. But that’s just the surface. There is also configuration data, wire data, deployment artifacts, source code, wikis and knowledge bases, etc. Much of this data simply won’t fit into the traditional data processing view of the world. It’s too big. It’s too hard to move. It doesn’t neatly fit into rows and columns. It changes rapidly.
The workflow of an investigation looks much different than answering a business question. At Cribl, we are big users of our cloud data warehouse. When I want to understand my sales pipeline, I have a basis from which to start my questions. I want to look at sales data. I know that data is going to have a certain structure. In fact, in the early days, we used to solve this with a simple spreadsheet using pivot tables. But investigations are different. I often start with questions like “Where is this error message coming from?”, “What is this IP address talking to?”, or “What is this user’s experience?”. The data to answer those questions comes in many shapes, and I don’t know in advance if this will be log data, wire data, trace data, or metric data. It’s difficult to articulate investigation questions if I have to start with what table the data is stored in.
As the industry began to work to solve these problems more than a decade ago, we followed familiar patterns. We found traditional RDBMS technology didn’t scale to work for observability and security, so we invented new, fit-for-purpose data stores. For those data stores to work, we needed to move data to that data store and store data in proprietary formats so we can provide fast queries and fast searches. Copying data ensured that we had a copy of the data elsewhere if an endpoint died. This has worked very well for the last 10 to 15 years. Current observability and security technology are revolutionary compared to logging into systems and grepping logs. We can store millions of time series cost-effectively. We can find an end user’s individual log or trace message in milliseconds.
However, this comes with a huge cost. Centralizing copies of terabytes to petabytes of data is expensive. Indexing data and replicating it at the application tier results in massive storage and infrastructure costs. Enterprises spend millions of dollars a year on infrastructure alone to store and query this data. Moving this data isn’t free either, and cloud providers are making huge amounts of money off customers simply moving the data to other places for query. Storing data in fit-for-purpose data stores requires users to context switch, aka “swivel chair,” between different experiences to answer investigation questions.
Meanwhile, since we first started solving these problems, the world around us has changed. Cloud architecture is different than what most of this technology was built for: racks of servers sitting in data centers. Centralized storage technologies for observability and security were first designed to store data cheaply rather than putting data on expensive storage area networks. In today’s world, object storage provides these primitives, yet no technology provides a search-like experience on top of object storage without having a copy stored at an application tier in block storage. Meanwhile, data at the edge is no longer at risk. We no longer need to move data off of spinning rust drives on physical servers, which might crash because application servers are nearly all backed by durable block storage in the cloud. Additionally, we have a glut of underutilized infrastructure already being paid for.
What got us here won’t get us to where we need to go, and this is what I’ve been hearing from our customers and prospects. Data is growing at a 25% CAGR. Enterprises will have 2.5x the amount of data in 5 years they have today. Existing solutions are already too expensive.
Enterprises are demanding that we solve the data accessibility problem:
How do we get to data at the edge that it doesn’t make sense to centralize?
How do we give users the ability to access data in any data store?
How do we get to data that doesn’t fit into traditional data processing tools?
How do we make use of our observability lakes without moving data to other tools?
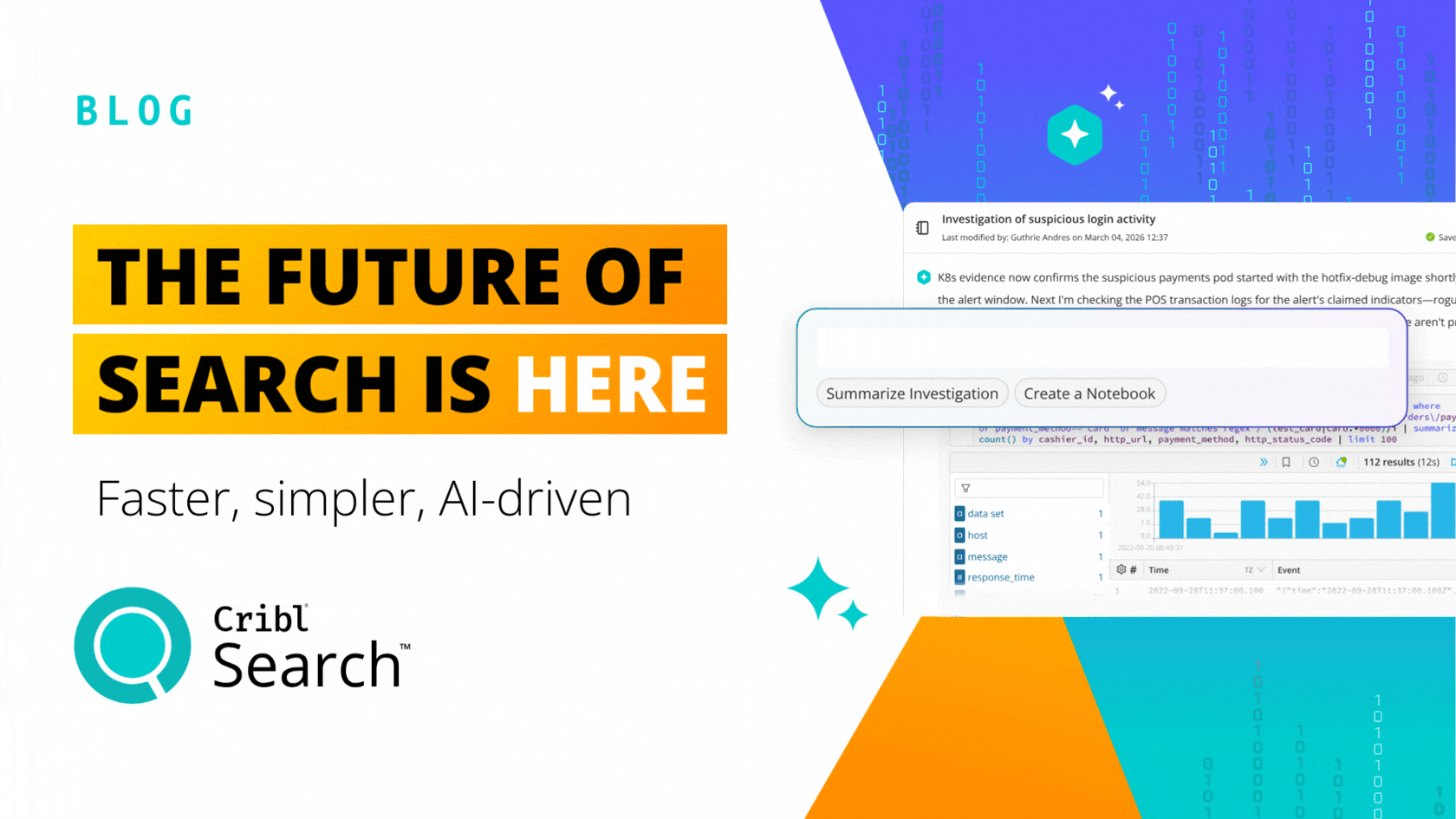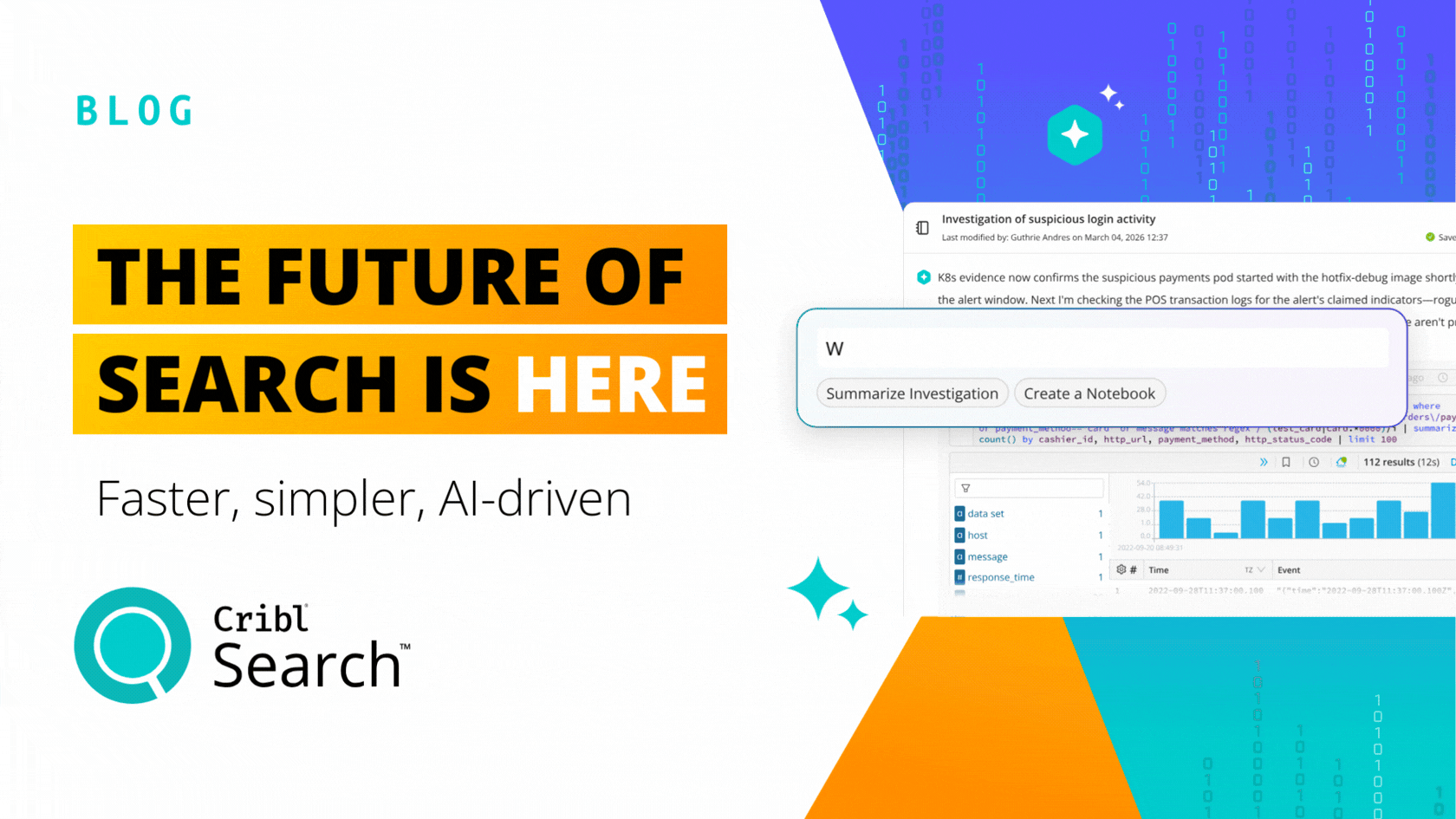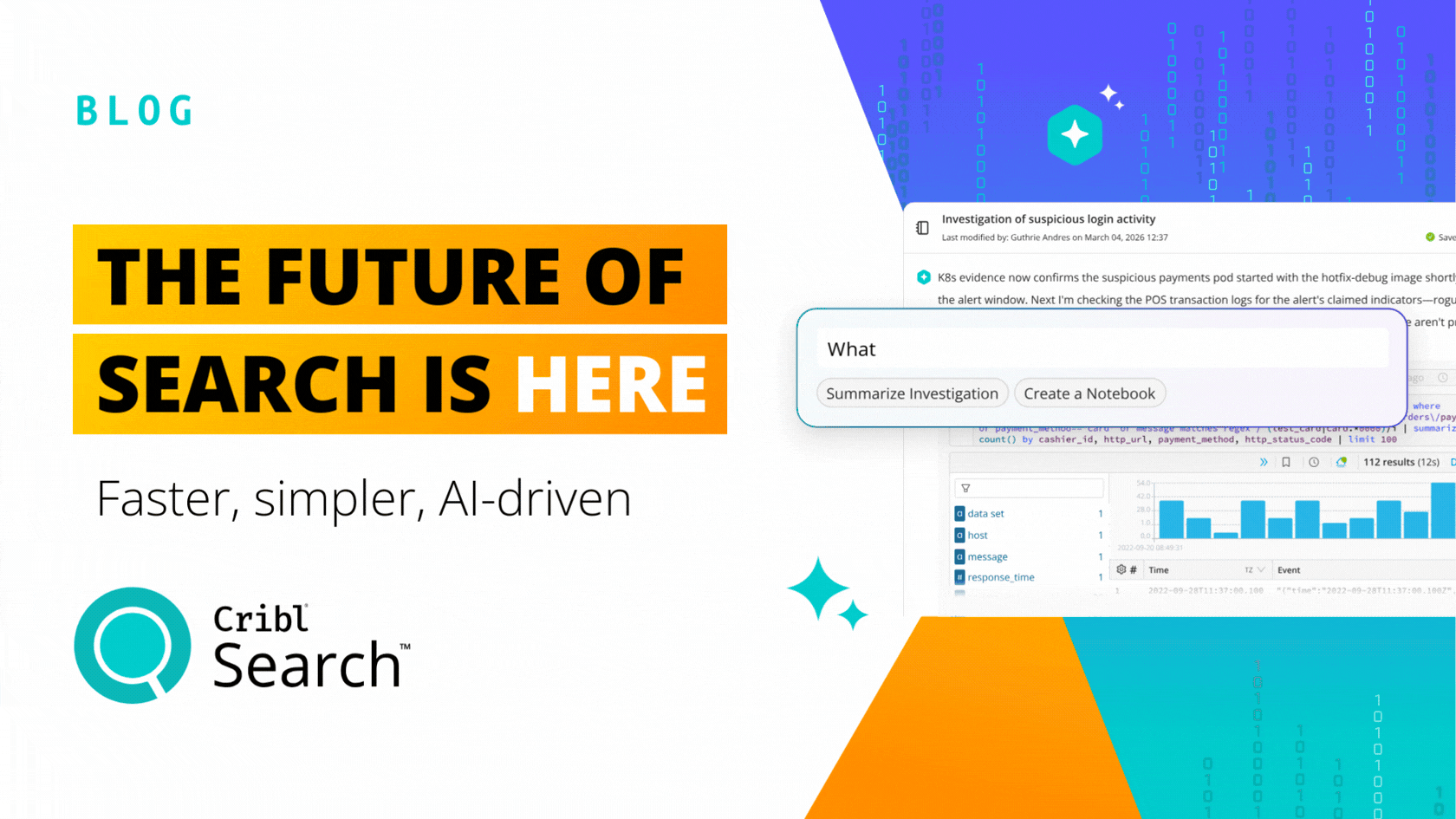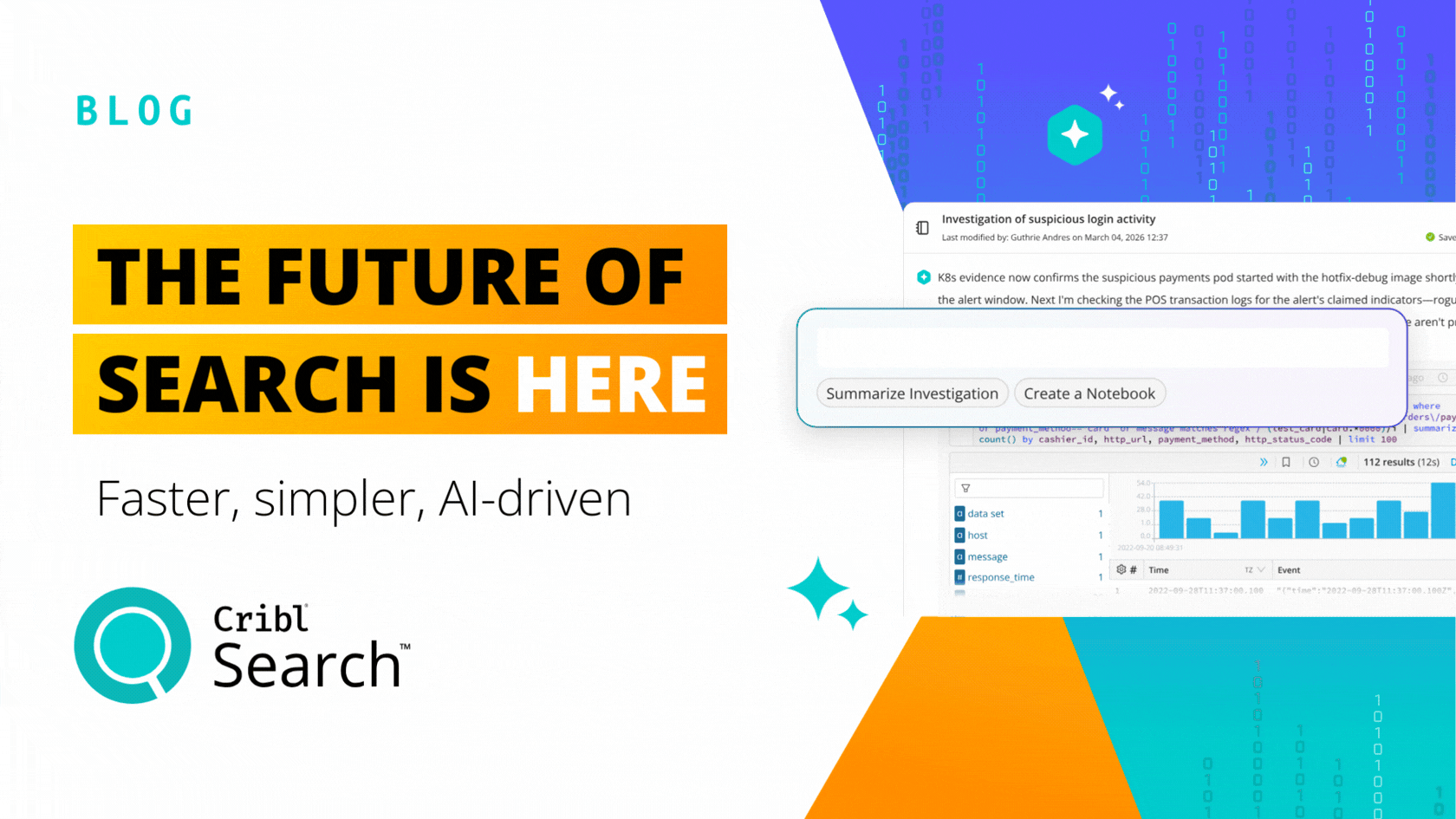
Enter Cribl Search
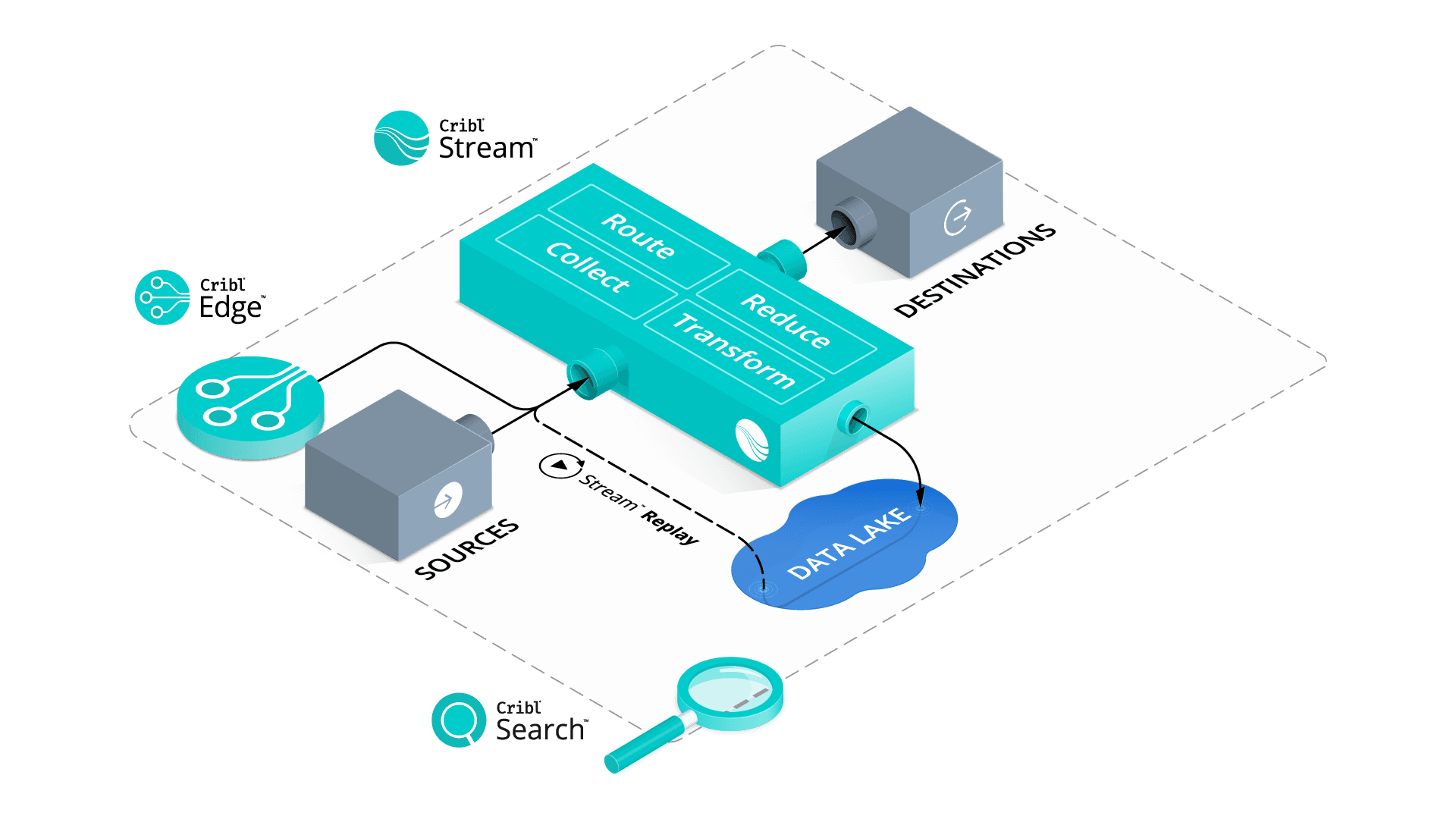
Cribl Search fundamentally changes how we think about data processing in observability and security. Search offers a new search-in-place approach with federated, centralized query, and decentralized data storage. Search allows you to put data in the right place for that data, offering the best advantages of existing data storage while also giving you the ability to query raw data at the edge, in the stream, or in your data lake. Search complements all of your existing investments in data technology while providing a familiar search experience that feels comfortable to users of existing investigation tools. Search is cloud native. It’s elastically scalable, and the infrastructure is only running while queries are processed.
Cribl Search is a new first principles approach to giving users back control over their observability and security data. It recognizes the reality of customers’ environments. Data is everywhere, and users are already trained in how to query data in existing stores. There is little incentive to rip and replace data stores. Yet, the problem remains of how to query across them or how to get at the data that does not fit or does not make sense cost-wise to centralize. Cribl Search solves these problems using the latest in technology that simply made this approach infeasible 5 to 10 years ago.
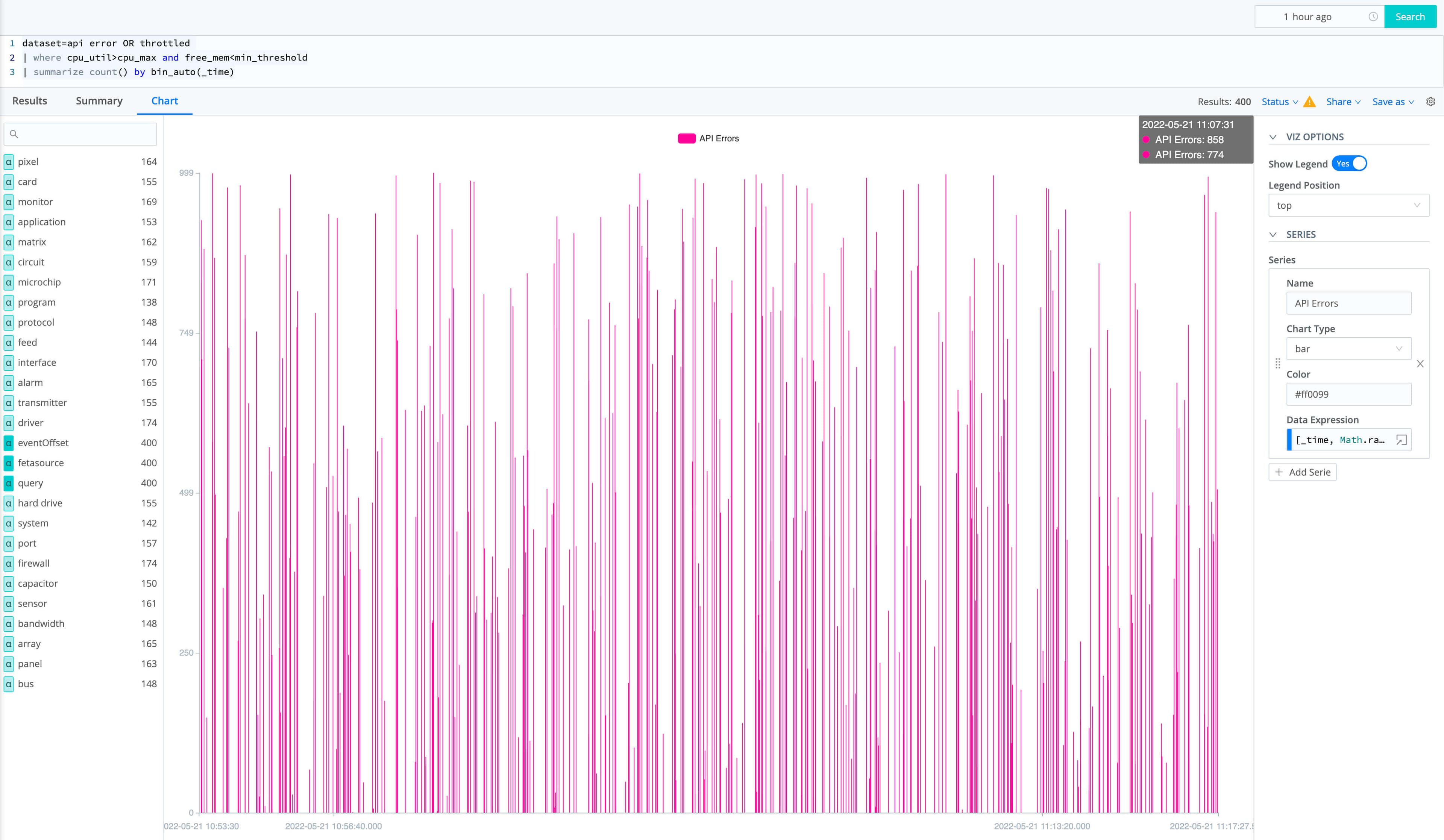
Search is in early preview. We are looking for development partners who find this value proposition compelling and are looking to work with us on early versions of the product. Search will be generally available later this year. If you’re interested in working with us, please sign up for early access here.
Search is yet another example of Cribl’s first principles approach, and it’s another example of the innovation coming out of our new products organization, Cribl Zero-to-One (C021). Cribl believes in a culture of shipping, and we will continue to innovate with new products and new approaches. If you find that exciting, we are hiring in nearly every function, and we’d love to work with you! Check out our available job postings, and let’s GOAT!