

Enterprises are dealing with a deluge of observability data for both IT and security. Worldwide, data is increasing at a 23% CAGR, per IDC. In 5 years, organizations will be dealing with nearly three times the amount of data they have today. There is a fundamental tension between enterprise budgets, growing significantly less than 23% a year, and the staggering growth of data. Enterprises are already struggling with the cost of observability and security data, many spending millions a year, some into the tens of millions a year, to store their metrics, logs, and traces.
Meanwhile, observability is becoming a key initiative for enterprises everywhere. Modern application architectures continue adding additional layers of complexity, and organizations are turning to observability solutions to help them ask and answer arbitrary questions of their data that they did not plan in advance. Observability is helping to answer questions like, “why did this one user have a bad experience?” or “where did this attacker go after they compromised this machine?” However, you simply cannot ask questions of data you do not have. If you have to sample trace data heavily, you may not be keeping the critical users’ trace that you need to see. Debug logs can be incredibly valuable, but they’re too voluminous to cost-effectively put into most logging tools. Running a security investigation months after the fact requires keeping full-fidelity data online and available.
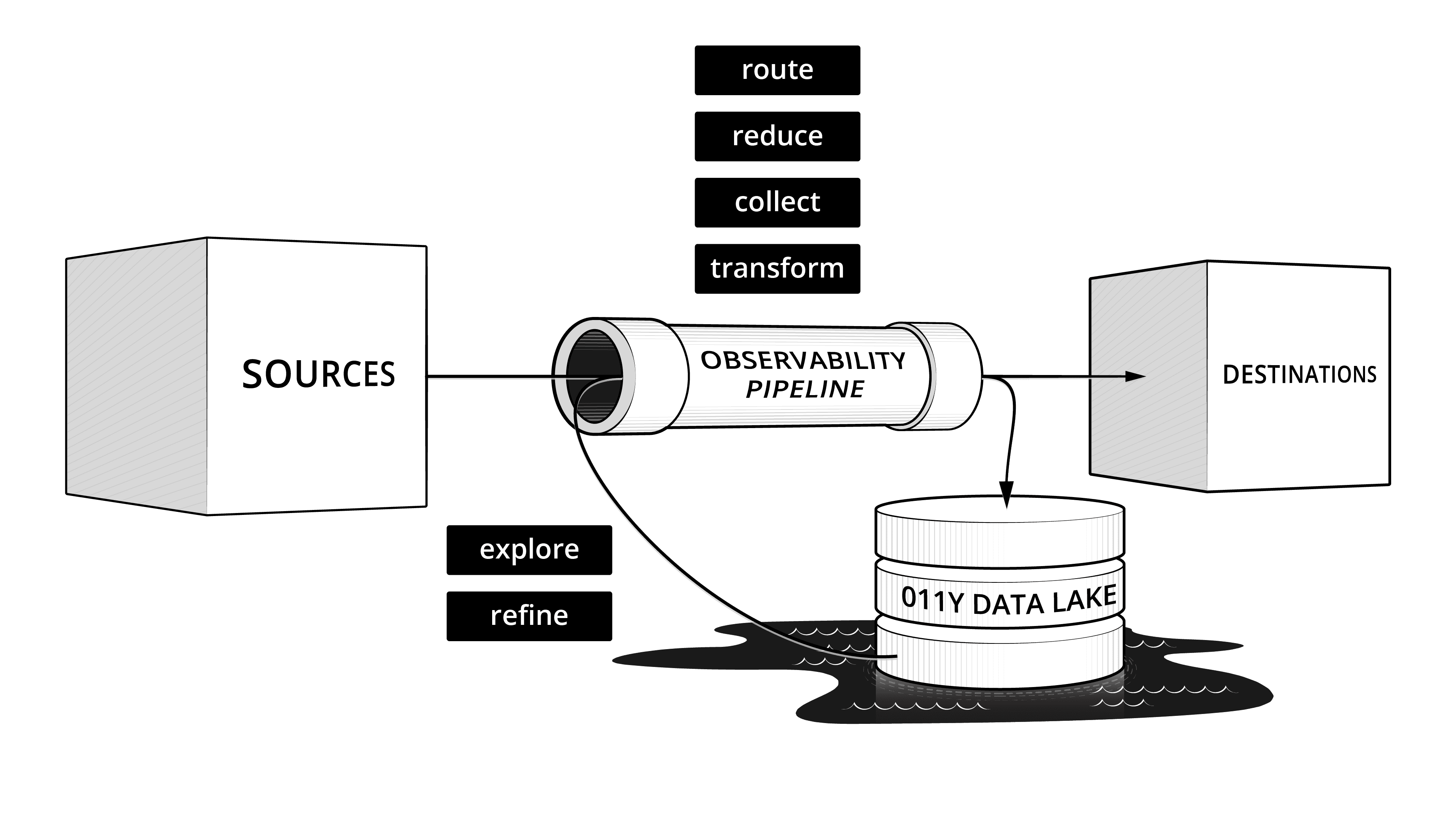
We believe a new architecture is needed. One that adds two new critical components: the observability pipeline and the observability lake. These new components are additive. Enterprises have massive investments in metrics, logging, and tracing solutions today. An observability pipeline provides an open, vendor-neutral routing tier that allows enterprises to regain the choice of where to put their data, no matter the source. An observability lake provides an open, vendor-neutral place to store data in open formats, cheaply. With these new components, customers are never locked into a particular vendor.
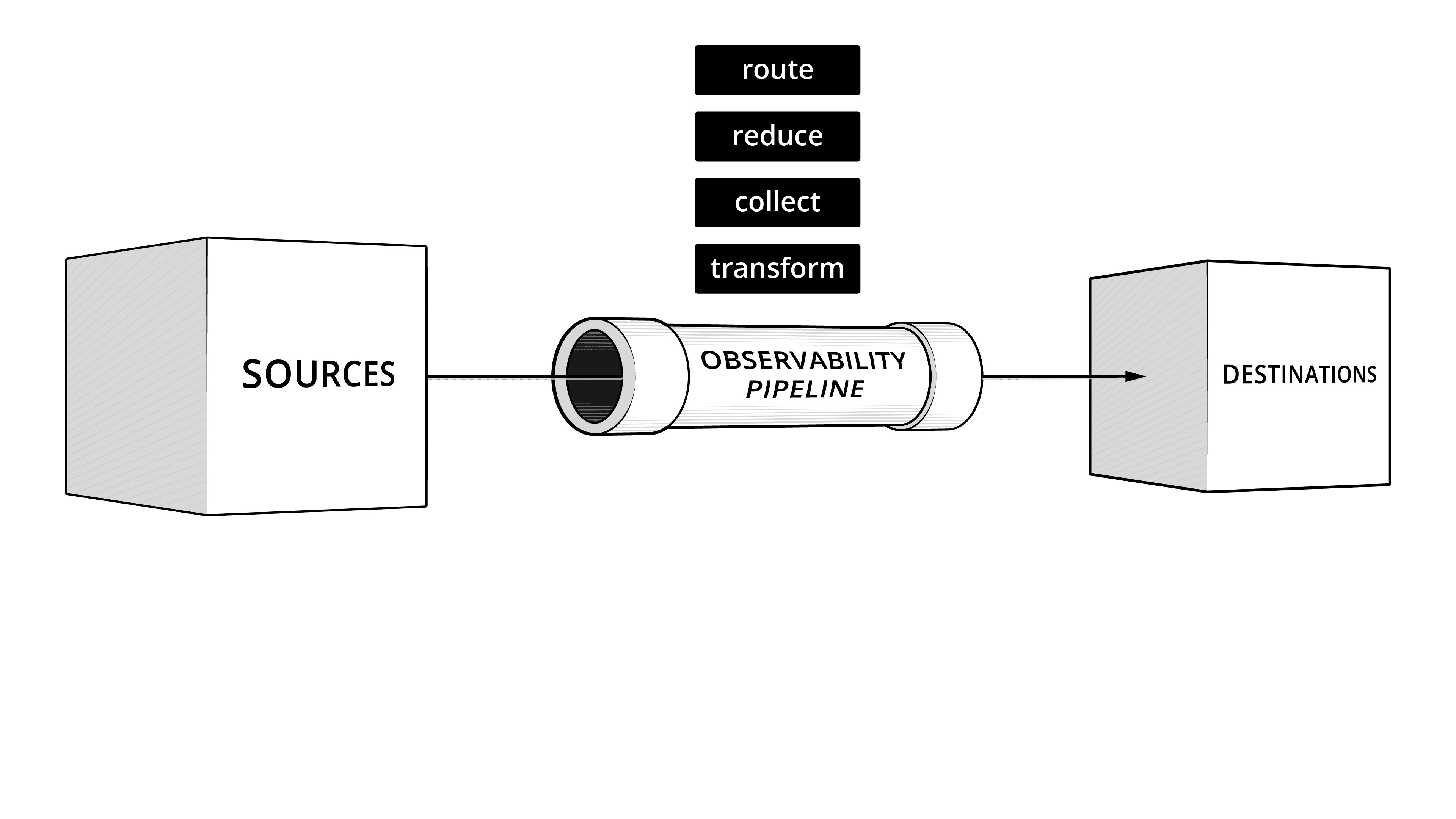
For the last several years, Cribl has been working to pioneer the concept of an observability pipeline. This has brought welcome relief to many enterprises and given them control back over their observability and security data. We have also seen customers building their own observability lakes in S3 and other cheap storage. Cribl Stream’s replay functionality allows them to easily take data in their lake and send it back to any of their existing solutions. Products like AWS Athena and Databricks allow users to cost-effectively analyze structured data at rest in their observability lakes. Future products in observability will provide new experiences, designed for operators and security pros, for analyzing any data, structured, poly-structured, or unstructured, at rest in an observability lake.
In today’s world, analyzing observability and security data at rest requires one or more commercial tools or SaaS services. Once you put data into your logging, metrics, and tracing tools and services, this data is no longer your data – it is the vendor’s data. Reading that data back requires maintaining a commercial relationship with your vendor, often with little leverage or control over the cost. The observability lake frees you from this lock-in and ensures the enterprise’s data always remains the enterprise’s data.
The rest of this post will outline in more detail the key drivers of the demand for a new concept, what makes an observability lake different, and use cases for observability lakes.
Why an Observability Data Lake
The primary driving factors in the demand for a new concept are data volume and data gravity. Organizations are storing a small fraction of the observability and security data available to them today. Storing debug level logging or full-fidelity trace information in existing solutions is cost prohibitive. In the case of a breach investigation, having full-fidelity endpoint and flow level data is invaluable, yet most organizations are not retaining data for more than a few months. Once stored, data has gravity. Moving from one vendor’s solution to another is a massive uplift, and usually involves losing access to older data stored in the old vendor’s formats.
Organizations have already begun asking themselves how they can take control back over data volume and data gravity. Enterprises feel held hostage at every contract renewal to maintain relationships with vendors that are not aligned with their interests. Migration costs are high, and these vendors know they have all of the power. Organizations are gravitating towards observability pipelines as a way to control data volume and ease switching costs, but that only helps with new data. A new concept is needed to solve for data volume and data gravity for data at rest.
What is an Observability Data Lake
The observability lake solves for future-proofing the storage and retrieval of an organization’s observability and security data. The observability lake allows for storing many multiples greater volumes of data available to enterprises today, cost effectively. Data is delivered to the observability lake from the observability pipeline, and data is stored in that lake in open formats which can be read by any number of solutions. The observability lake is queryable. The observability lake can hydrate new observability and security solutions with full fidelity data stored in the lake. The observability lake has configurable retention, allowing for high-fidelity short-term storage of observability data and long-term retention of security data.
There are a number of properties which make an observability lake different from what’s come before:
Vendor-neutral: data is in open formats
Cost-effective: data is stored in the cheapest storage available
Schema-agnostic: data can be stored without a predefined schema at write time
Format-agnostic: accepts any data, including things like configuration files or packet captures
Queryable: data can be interrogated questioned, or replayed to another data store
Optimizable: data which is read back can be optimized for fast query, but not by default
The observability lake does not replace existing observability and security solutions – it augments them. Much is written about pillars of observability, and the data that make up those pillars: metrics, logs, and traces. However, those pillars come from a fundamentally implementation-centric view. An observability lake will not offer the cost and performance of a time series database, nor will it offer the speed of search of an indexing engine or the user experience of a distributed tracing solution. An observability lake gives organizations choice and control, and it may take on some use cases of existing observability solutions, but it is not designed to replace them. Think of an observability lake as an umbrella option that delivers “enough” until you’ve decided which data is important, and where it needs to reside to provide the most value to your organization.
Many existing vendor solutions offer some of these properties, but not all. There are implementations of observability lakes at enterprises today, utilizing a variety of general purpose data processing engines. Organizations may use Presto-based products like AWS Athena or Starburst, or they may use engines like Databricks to analyze the data at rest in object storage. Most of these engines struggle to deal with the data volumes and number of unique data shapes present in observability and security data, but some success is being achieved today. More vendors will work to address these gaps and provide fit-for-purpose observability lake solutions.
Use Cases for Observability Data Lakes
Observability Lakes open up a number of new use cases and architectures. For example, debug level logging is often useful, but it’s expensive to even egress high-fidelity logging or traces for every interaction between every part of a microservices architecture. For troubleshooting, it might be useful to have the last several hours of API payloads to troubleshoot failed requests and help reproduce error conditions. Backups of configuration data can help understand the state of the environment at a particular time. Packet capture data can help understand unusual network conditions or security concerns.
There is often a large gap between when an enterprise becomes aware of a breach and when the breach first occurred. Breach investigations are problematic in today’s logging architectures because data is often only kept online for 90 days or less. Persisting data in expensive block storage, replicated many times, and with large full text indexes makes long retention times cost prohibitive. Storing compressed raw log data, with no index, especially with the cost effectiveness of infrequent access object storage, can cost-effectively store 100x the amount of data for the same price. Queryable observability lakes give investigators access to unparalleled retention to be able to rewind the clock the six months or a year required to look back to when breaches occurred before being detected.
Model training is an iterative process. In today’s world, access to full fidelity data used to understand user behavior, either from an operational or security perspective, usually requires getting a feed of the firehose because only summary level data is retained. With the observability lake, it is cost effective to store full- fidelity data, and easily rehydrate data from the observability lake and replay it through ML training models, allowing for fast iterative development of models.
There are unlimited possibilities that will surface by giving cost effective access to massively greater volumes of data.
Wrapping Up
There are organizations building observability lakes today, utilizing an observability pipeline to deposit data, generally into object storage. Products like Cribl Stream can easily replay the data. Products like AWS Athena can query that data serverlessly, although maybe not with the optimal user experience today for data exploration. In the future, queryable observability lakes will enable organizations to collaborate on top of full fidelity data and eliminate forced compromises where data must be aggregated and summarized simply to be retained. If you’re interested in learning more about how Cribl products can help enable your next generation observability architecture, please contact us or join our community to interact with our users and partners doing this today!
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.






