Log data search tools found their first traction in the Linux sysadmin community in the mid-00s, helping users troubleshoot problems across dozens or hundreds of systems from a central search bar. For troubleshooting, fresh data is much more valuable – I need to know what’s happening now.
But log data search tools have many more use cases today. They are often the security system of record where data is stored for compliance or in case needed for a breach investigation months later, but never queried. Log systems are also often used for large time series data sources where customers run read-time aggregations across large full fidelity event streams.
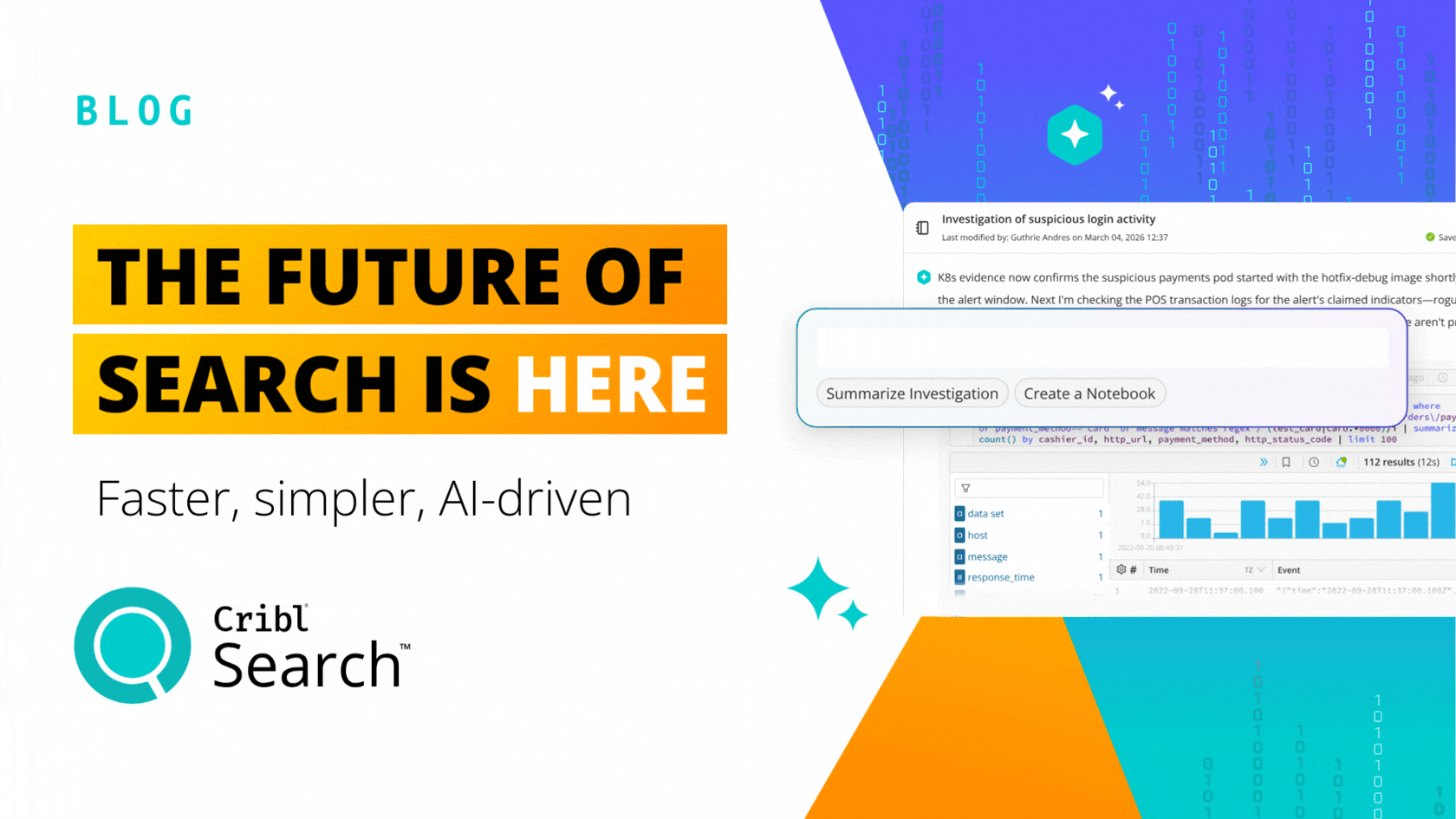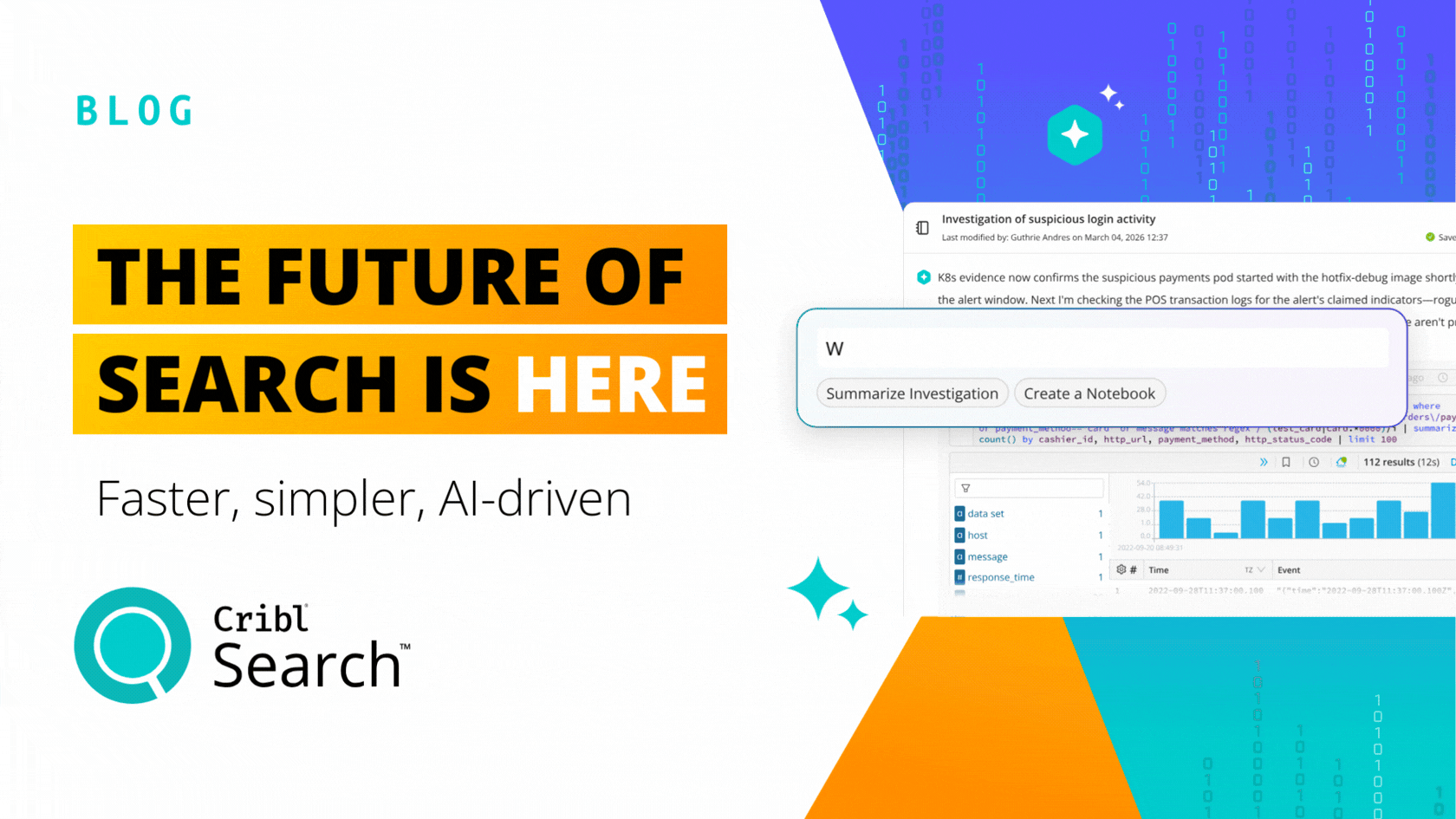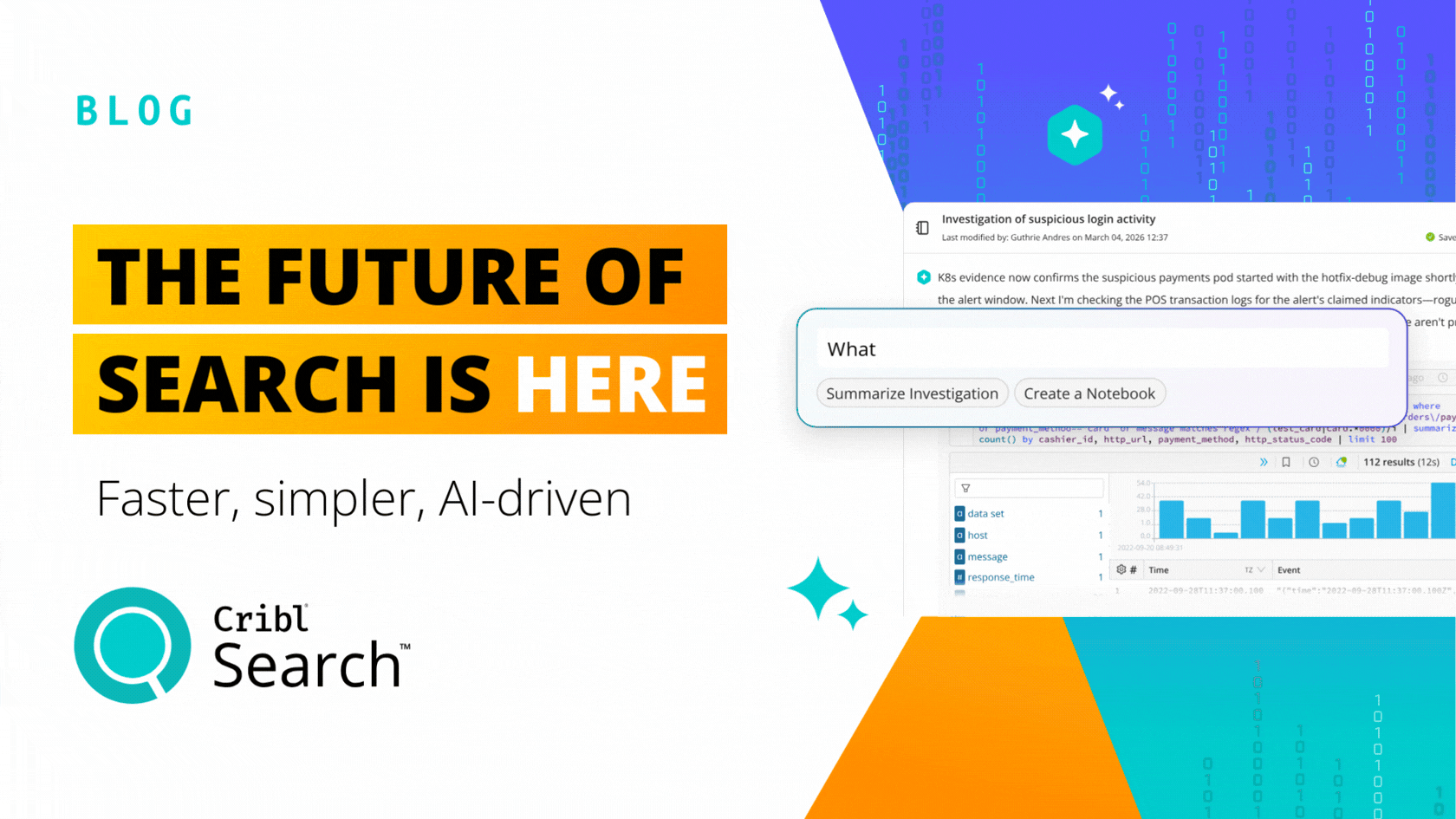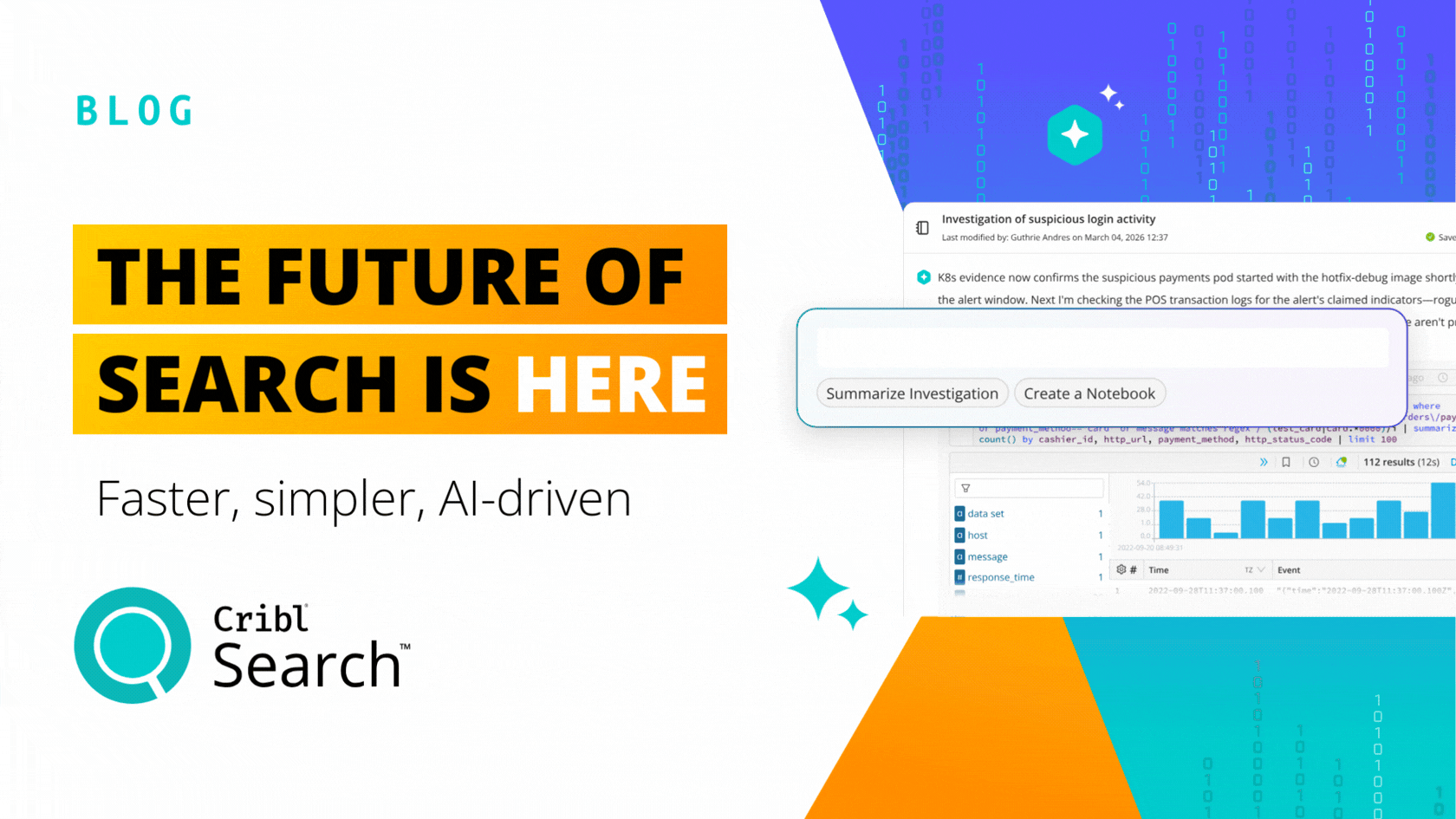
Today, we’re pleased to announce the general availability of LogStream 2.2. With LogStream 2.2 we give customers a new option: Data Collection lets you land data in cheap storage and replay it if and when it’s needed. LogStream 2.2 enables you to decide, later, whether data is interesting.
LogStream 2.2 adds a rich graphical user experience to enable any user to fetch data back from cheap storage. Ad-hoc collection jobs can be run through LogStream like any other data, enabling aggregation, enrichment, filtering, sampling, or one of many other use cases we support. With data collection, replay can take data from cheap storage and deliver it to any destination.
If you’d like to learn more, please join our webinar on June 18th, where we’ll walk through a number of use cases for this new way of handling logs. We’ll have a live demo of the new feature in action, and we’ll have Q&A at the end.
Additionally, if you’d like to test drive Data Collection, please try our LogStream 2.2 sandbox and share your completion certificate! If you want to dive in deeper, please read on.
Data Collection
LogStream was the first stream process engine purpose-built for log data. And now with the release of LogStream 2.2, it is the first tool purpose-built for the batch processing of logs. This is a huge change in how people will be able to use log data for observability and security efforts. Instead of putting all log data in an analytics tool, LogStream helps you process it and determine whether it should be analyzed now, aggregated and converted to metrics to be sent to a time-series database, or stored and made available for analysis in the future. The ability to collect data from an object store and replay it to an analytics tool at any point in time gives you tremendous flexibility in how you process log data in the first place. This offers security and IT professionals a new way to both optimize their ability to get value from machine data and control costs.

Data Collection helps you save money and analyze more data at the same time
Why This Matters
Log systems are optimized for fast retrieval by indexing all of the data. When people first started using log analytics tools like Splunk and Elastic it made sense to index everything because the amount of log data they were analyzing was relatively small compared to today. Indexing data has real costs both in terms of storage size and in computing power required. Costs have compounded as organizations have experienced 30-50% data growth year over year. Security and IT professionals have to make decisions about which data to analyze, how long to retain it, and how to investigate previous incidents using log data.
If budgets were unlimited, keeping log data in a logging system indefinitely would be a no-brainer. The reality is that most budgets make this approach untenable. LogStream 2.2 lets you route full-fidelity data to a low-cost storage location and then collect the data you need to analyze when you need it. This approach can reduce infrastructure costs by 99% compared to storing it in an indexed analytics system. For a more detailed look at this, check out “Why Log Systems Require So Much Infrastructure.” Determining whether data should be analyzed now or stored for future use in real-time helps you control costs and gives you tremendous flexibility to improve future investigations.
Let’s take a look at three use cases for Data Collection.
Use Case 1 – Reduce Data Sent to Analytics Tools
If you’re familiar with LogStream, you know that right-sizing log data is at the heart of what we do. Our mission is to “Unlock the value of all machine data.” That means being able to analyze everything that can give you answers about your IT and security efforts. More importantly, it means being able to discern between data that has analytical value now and data that can be archived for analysis later or dropped altogether. The more data that is sent to an indexed analytics tool, the more you pay in license and infrastructure costs. Separating out only the data that needs to be analyzed today from the rest saves our customers millions of dollars a year. With our 2.2 release, we make it easier than ever to reduce log volume sent to an analytics tool. Because you are able to collect data from storage and replay it at a later time, you can be more aggressive reducing the amount of data sent to your analytics tools while putting full fidelity into storage. As with previous versions, LogStream can also aggregate log data into metrics that can be sent to a Time Series Database which can reduce the data size by a factor of 1,000-to-1.
Use Case 2 – A Better Approach for Retention
Sending less data to an expensive analytics tool is a great way to control costs. Data that is retained in those systems also incur significant costs with respect to infrastructure. For some of our larger customers, infrastructure devoted to logging systems cost more than $10 million a year. The longer you retain data in these systems the larger the cost. So even if you are using LogStream to reduce data ingestion, keeping data in these tools for several months has materially significant costs. You likely want to keep data for a while in case you need to analyze it at a later date. Many industries and IT departments have retention policies that require keeping data for a specified period of time, up to 7 years in some cases. LogStream 2.2 solves this by only putting data that needs to be analyzed in real-time directly into your logging tool and routing a full copy of all the data to a low cost datastore. Because you can collect data when you need it and replay it to the analytics tool, you don’t need to retain it in a system that will swell the infrastructure that has to support it for several months. Customers that reduce data retention periods to as little as a month can save millions of dollars on infrastructure costs. For more information on this read, “When All I’ve Got is a Hammer” to learn strategies for affordable data storage.
Use Case 3 – Investigating a Security Breach Long After it Happens
Most security breaches are discovered long after they start. I used to find it curious that companies often announced data breaches that happened 6 months or earlier. In extreme cases, it can take years to learn that a security breach is ongoing. Take, for example, the Marriott hotel chain, which in late 2018 discovered that one of their subsidiaries’ reservations system had been compromised dating back to 2014. Most companies, even those with stringent data retention compliance policies, don’t keep security logs in their analytics tool for more than 90 days or maybe up to a year – the infrastructure costs alone would dismantle their IT budgets. Employing LogStream 2.2, companies like this could park full-fidelity data in a low-cost storage location for years, if not indefinitely. When security breaches are discovered they could collect the data from storage, filter the data to the target time range, and use other criteria to replay security logs to any SIEM or UEBA tool of their choosing. Without an affordable strategy for keeping data long-term, you have to choose between supporting (and paying for) a massive infrastructure and not having the data available to conduct a proper investigation.
Other Features
Data Collection is the highlight of the LogStream 2.2 release, but there is plenty more in there to excite you. Here are a few highlights:
Improvements for Distributed Management
New Sources, including Splunk HEC Raw and HTTP and TCP sources
New Destinations, including Syslog UDP and Minio
Updated Diag Service (improved support for diagnostic bundle generation)
Improved Troubleshooting (centralized log searching, time range filtering, more)
Improvements to Working With Data, including S3 and TCP binary sources
Logging Management Improvements (new redaction capabilities and fine-grained control)
UX/UI Updates (new Home, Sources, Destinations, and Pipelines page designs)
Plus many other improvements and changes
For a complete list of new features and improvements, read the LogStream 2.2 release documentation.
Wrapping Up
Believe it or not, all of that is squeezed into the 2.2 release. Want to learn more? Here are a few ways to get started.
Try LogStream 2.2 with our sandbox course on Data Collection
Download LogStream today for free and process up to 100 GB of data per day at no charge!
If you have any questions about anything Cribl, use the chat widget here on the site
Join our community Slack and follow us on LinkedIn.