
My story is not unique. Years ago, I saw the benefit of capturing system logs across all of my systems and being able to search through them. It started out pretty inexpensive: a few thousand dollars for a reasonable Splunk license, and a box to run it on. I was using the data to troubleshoot problems and maybe see some trends, so I had a fairly easy time balancing performance and retention – I didn’t need to retain most of my data for very long. The system got popular, and I needed to ingest more and more data. Finally, the security and compliance teams caught on, and suddenly I had to retain all of this data.
My logging infrastructure costs started exploding, and my performance got steadily worse – I went from retaining a month of data to retaining 13 months. Moreover, I was now ingesting a lot of data that was never used in the analysis, simply to get it retained. That felt like a waste of my available capacity. But why was I retaining all of that data in my analysis system? Because I really didn’t have another choice at the time. As the old saying goes, when all you have is a hammer, everything looks like a nail. Log Analytics was my hammer, and every requirement looked like a nail.
Over the last 10 years, with the move to cloud services, such as AWS, the cost of archival storage has been racing to the bottom, and now with services like Glacier Deep Archive, the cost of storing a Terabyte of data is less than $1/month. It’s time to separate retention from analysis and serve both needs better. Analysis and Troubleshooting of system problems benefit greatly from the fast response you get from not having “extra” data in the system. Retention benefits from having a well organized archival capability, but the data does not have to be at your fingertips. In all of my years in IT, I have *never* seen a request for year old log data that had to be available *right now*…
A Different Way
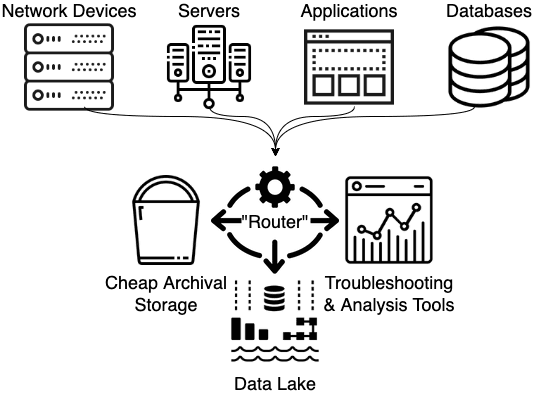
By inserting some sort of routing mechanism into the environment, as seen on the right, instead of feeding all of the data that has to be retained through the log analytics system, the entire “firehose” worth of logs can be retained by sending it to low-cost archival storage, like Amazon S3, Glacier/DeepArchive or Azure Block Blobs. This enables filtering the data for the log analytics system to only the data needed for analysis. If that routing system has the capability to transform, enrich and/or aggregate the data, now simple metrics about the data can be fed to the https://cribl.io/blog/the-observability-pipeline/data lake for use in normal business reporting. This separates out the data retention requirement from all of our analysis needs.
Cribl White Paper: 6 Techniques to Control Log Volume
Learn how to cut costs with Cribl LogStream.
Benefits
Cost
Let’s take an example – say we’ve got an environment that is ingesting 2TB a day, and getting a roughly 2:1 compression ratio in storing that data, leading to about 1TB/day of storage consumption. Add to that a compliance requirement of 18 months of retention. Averaging 30 days in a month, that comes out to about 540TB worth of storage. In the table below, there are 4 scenarios for retention management, and you can see the drastic difference this can make in cost of infrastructure: An aggressive move from managing all of the data in General Purpose (GP) Elastic Block Store (EBS) volumes to one that keeps a minimum (30 days) in EBS, while moving the rest to Archival storage (with automated lifecycle management dealing with the migration between the “tiers”) reduces storage costs from $54K/month to $4.3K/month – that’s a net savings of almost $600K/year, and this is only looking at the storage costs, not taking into account compute resources, software licensing, etc. While you could go even more aggressive and go directly to Deep Archive for all retention, this scenario balances retention cost with the likelihood that more recent data is more likely to need to be retrieved – Deep Archive’s retrieval time is considerably longer than S3…
The example is based on cloud services, but a similar approach can be followed in an on-premises data center environment. The economics are a bit harder to model, due to differences in hardware and operating costs, but it is possible using standard storage options.
Performance
The simple act of eliminating a massive amount of the data in a given analysis system will likely yield immediate, measurable improvement in the performance of queries, especially any queries that are not properly constrained by time ranges (we all have users who do this and then don’t understand why their queries take forever). With a much smaller footprint to work with, one can optimize the storage for its purpose. For example, moving to provisioned IOPS EBS volumes (the cost addition is far less prohibitive on 30 TB than it is on 540 TB).
Data Quality
Developers are incentivized to put every field in the log entry – it’s far more expensive to have to go back and add logging statements than to include it initially. As a result, a lot of the log entries that applications generate have empty fields or extraneous data. Without the need to retain the data in its original form, we can easily remove fields we don’t need, drop empty fields, and even aggregate repeated log entries (great examples are port status lines on switches or Windows Event Log login notifications). Cleaner data leads to quicker resolution and cleaner metrics.
How To Do It
At the heart of this approach is by building what we at Cribl call an Observability Pipeline. This can be built from open source components (see Clint Sharp’s post on this topic for details), but we believe that our product, Cribl LogStream, is the best way to do this – it can be a drop-in replacement for components in your logging environment like Splunk Heavy Forwarders or LogStash instances, and configuring it to do exactly this just takes a few clicks of the mouse.
The fastest way to get started with Cribl LogStream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using LogStream within a few minutes.






