

According to a 2018 study by the Ponemon Institute, the average time from the occurrence of a security breach to detection is 197 days (with the entertainment industry on the high side – 287 days, and the Energy sector at the low end – 150), but with stories like the Marriott breach (occurred in 2014, detected in 2018) or the Dominion National breach (occurred in 2010, detected in 2019), it’s clear that retention of data critical for investigations is an important part of any security incident response plan.
Logs and machine data are such critical data, but most companies have given up on retaining log data for multiple years due to the expense. If that security data is being retained in an indexed log management system, the infrastructure to support multiple years of retention is prohibitively expensive. If we use the example I put forth in this post, but push out our retention to 5 years, about 1.8PB would be the total storage, at a monthly cost of about $180K (based on list AWS EBS pricing), or about $2.2M per year. That’s a pretty large chunk out of even the best-funded security team’s budget. However, move that all to low-cost archive storage, like AWS Glacier Deep Archive, and that monthly cost goes down to about $5400 per month or $65K per year. I’m using cloud costs because they’re standardized, and on-prem costs will vary widely depending on technology in use, etc.
Cost-Effective Is Great, but How do I USE It?
Now, solving the cost of retention is only part of the solution; if the data is sitting in cold storage and you have no way to use it, it’s as good as thrown away. That’s where LogStream’s new Data Collection capability comes into play. As you can see in the diagram below, Data Collection can be used in the existing tool environment to pull data from the archival bucket and feed it into the log analytics system.
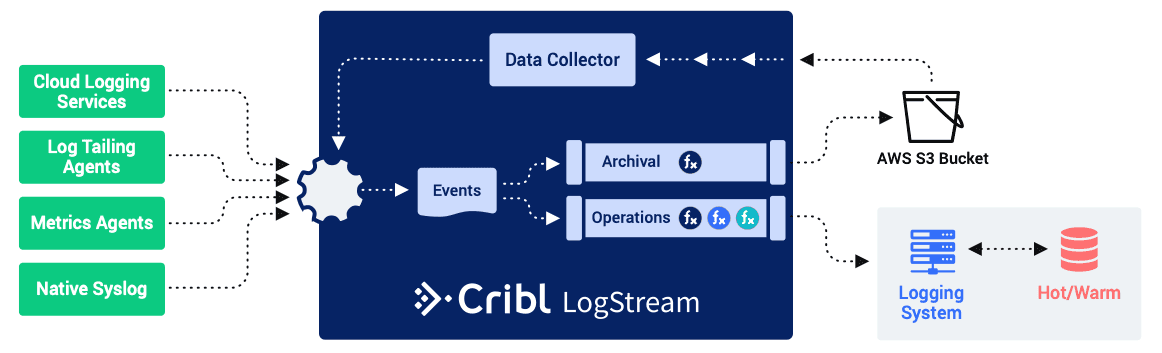
This makes retrieving data feasible, but it still has its challenges:
The retrieved data competes with the normal data flow for resources, like fast storage, RAM, CPU, etc.
The retrieved data counts against your daily ingestion license limits, which could cause problems with your day to day operations.
However, there is an alternative to loading the data into your existing environment: load it into a new one that’s dedicated to your investigation. In the diagram below, you can see that we just have a LogStream instance, using Data Collection to pull data from the archival bucket, doing any transformations necessary via a pipeline, and then delivering to a cloud-based instance of ElasticSearch. If you’re concerned about egress fees, you can use AWS’s Elasticsearch Service.

This approach has the advantage of ending up with a dedicated system for your investigation that you can set up to perform as you need it, and that does not require a pre-existing license, as you pay for what you use instead of a predetermined limit. On top of that, since it would likely be in the same account (or just as likely the same Organization) as the data, you wouldn’t be charged egress fees for moving the data (assuming you’re not analyzing it in a different region).
With this dedicated environment, you can feel free to explore the data at will, without impacting anybody else (or having them impact your work). And, if the investigation leads to needing more data (e.g. additional time frames, or types of data you didn’t pull initially), that data is only a data collection job away from your fingertips. When you’re done with it, simply get rid of the environment and its costs.
Data Collection, For the Win
The introduction of Data Collection in LogStream 2.2 enables security teams everywhere, with the ability to retain more data at a much lower cost, as well as the capability of delivering that data to almost any logging analysis system.
As part of our 2.2 Release efforts, we’ve created an interactive sandbox course to help you learn how to use the Data Collection feature. The sandbox actually implements a slimmed-down version of this approach. This course takes about 30 minutes, offers an Accredible certificate upon completion, and is available at https://sandbox.cribl.io/course/data-collection.







