
Before I became an employee at Cribl, I was a prospective customer. For years, I, and others at my former employer, had been struggling with the requirements of our log analytics system. The yearly re-justification of the license cost; the ever-escalating infrastructure costs, due to the constantly compounding growth of data; and the inevitably destructive trade-offs we made around what we logged and what we ignored were a constant struggle.
When I saw what Cribl LogStream could help us achieve, it brought a tear to my eye. Then, during the sales cycle, I was lucky enough to be exposed to Cribl’s roadmap, and heard about what they were at the time calling “Replay”. If the product made me cry, this made me sob in joy and relief. Ok, I didn’t really sob or even cry, but the idea immediately made me realize that we could *completely* reimagine how we were doing log analysis and retention.
What Is Data Collection?
Simply put, data collection is batch data ingestion. Batch processing is nothing new – it’s been around as long as computing has. But it is new to the log analysis world, which has been focused almost exclusively on real-time data: logs and metrics stream in and are analyzed in a timely manner.
Those systems are really optimized for near real-time access, but so many of us have also made them the system of record for our log data, so we store months or years of data in them, just to meet a compliance requirement. Most of that data *never* gets analyzed – it’s like a data insurance policy; save it for some time in the future when you might need it. Unfortunately, due to data growth, it’s an insurance policy with an ever-escalating price tag
Data Collection enables LogStream users to break that cycle. Instead, they can store *all* of their data in an inexpensive storage solution – like AWS S3 or even AWS Glacier – and *only* index data that is needed for analysis. You can see the potential benefits from this in my “When All I’ve Got is a Hammer” post. The Data Collection feature completes the vision that I describe there.
Reimagining Log Analysis
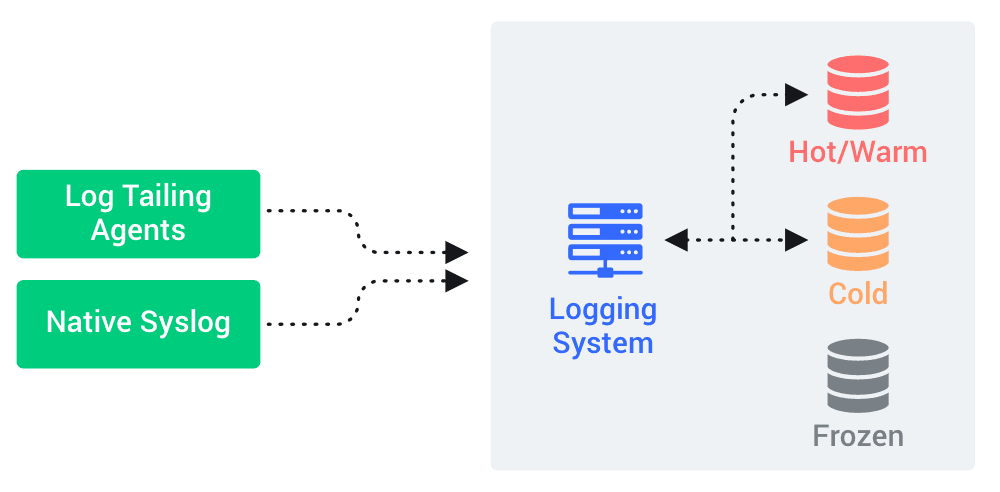
We were like many shops, where a variant of the type of logging environment you see on the left was in place. We had high-performance SSD storage for the Hot/Warm data, and slightly lower-performance SSD or HDD in place for the Cold data. We had the old SATA HDD’s in place for “Frozen” data, which was not directly accessible by the logging system, but could be “thawed” back into the system (although this was typically a pretty slow and painful process that was done outside of the logging system). This worked fine when we started, but was a struggle to scale, both tactically and financially. Keeping performance up meant more reliance on high-cost SSD’s and more and more compute, ultimately breaking the budget.
LogStream has had the ability to write to an archival store like S3 since its very first beta release. The ability to replay it from that datastore changes the game. Data Collection gives you a very fast and easy way to “warm up” archived data, replete with all of the power of LogStream pipelines, functions, etc.
So now, with LogStream in place and making use of Data Collection, a typical deployment can looks more like this:
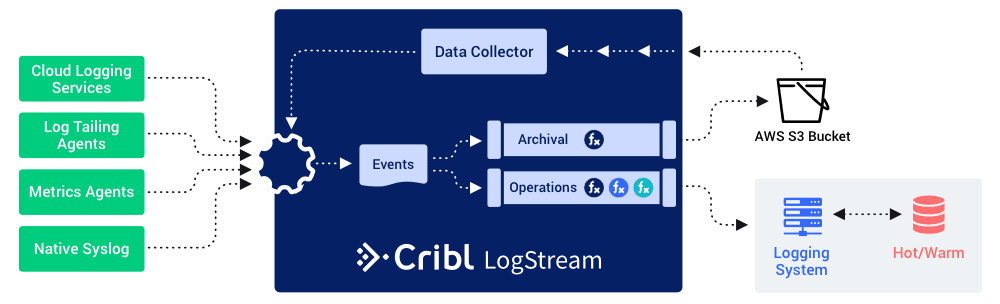
In this deployment, all data that’s coming through LogStream is being archived to the S3 bucket, which also has a Data Collector configured for it. This enables you to be a lot more aggressive with filtering out the data you don’t need for immediate troubleshooting or analysis. You can now do things like convert log data to metrics (sending only the metrics on), drop superfluous fields, sample, or even drop logs or log lines that you decide are unnecessary. All of this still safe in the knowledge that if you need any of that data back in the system, it’s a simple matter of running a data collection job.
Come Try it Out
As part of our 2.2 Release efforts, we’ve created an interactive sandbox course to help you learn how to use the Data Collection feature. This course takes about 30 minutes, offers an Accredible certificate upon completion, and is available at https://sandbox.cribl.io/course/data-collection.






