

When I was still writing code, our Splunk license only had enough capacity to monitor our Production environment. So we stood up a self-managed Elastic cluster for our lower environments. This quickly became unmanageable as we started logging more and adding additional environments. As I spend more time in the field, I see this pattern repeated over and over. Development teams approach the Operations team for centralized logging and it’s either too expensive, or they don’t have enough resources so they stand up their own shadow logging system. While they’re fun to stand up for a day, no developer wants to spend their time managing an Elastic cluster. These become incredibly expensive (especially if you are running them on cloud virtual machines), are rarely managed correctly, and are probably a few versions behind.
This is a new pattern to get 100% application log observability with no overhead outside of setup and built-in cost control. You only pay a small amount for log routing and compute for the queries to find the data. The pattern is very simple: Use Cribl.Cloud to selectively route logs to compressed blob storage with different retention periods. Then, use Cribl Search to find issues as they arise.
In my experience, application logs create 10x the volume of security logs. I have worked with customers who logged ~70M of the exact same Exception in a 10-minute period. Debug logs are incredibly valuable when trying to find the root cause of a service degradation or code issue, but it’s cost prohibitive to send these logs to a traditional log aggregation solution like Splunk or Elastic. Most customers only need Debug logs for 24 hours, but also want Error logs for 15-30 days for deeper forensic investigations.
The Pattern
In this example, I set up S3 buckets in AWS each with a different lifecycle.
Each of my environments in my SDLC needs different retention periods, similar to the following:
Developer Env
Pro-Tip Use Crib Searchl + Edge to search the local file system in place without moving files anywhere
CI/CD Environment
DEBUG: 1D
QA
DEBUG: 1D
ERROR: 3D
Staging
DEBUG: 1D
ERROR: 7D
Production
DEBUG: 1D
ERROR: 15D
Next, I use Cribl.Cloud to connect my S3 buckets to HTTP endpoints. That way, I can route logs from each environment and log level to their respective destinations.
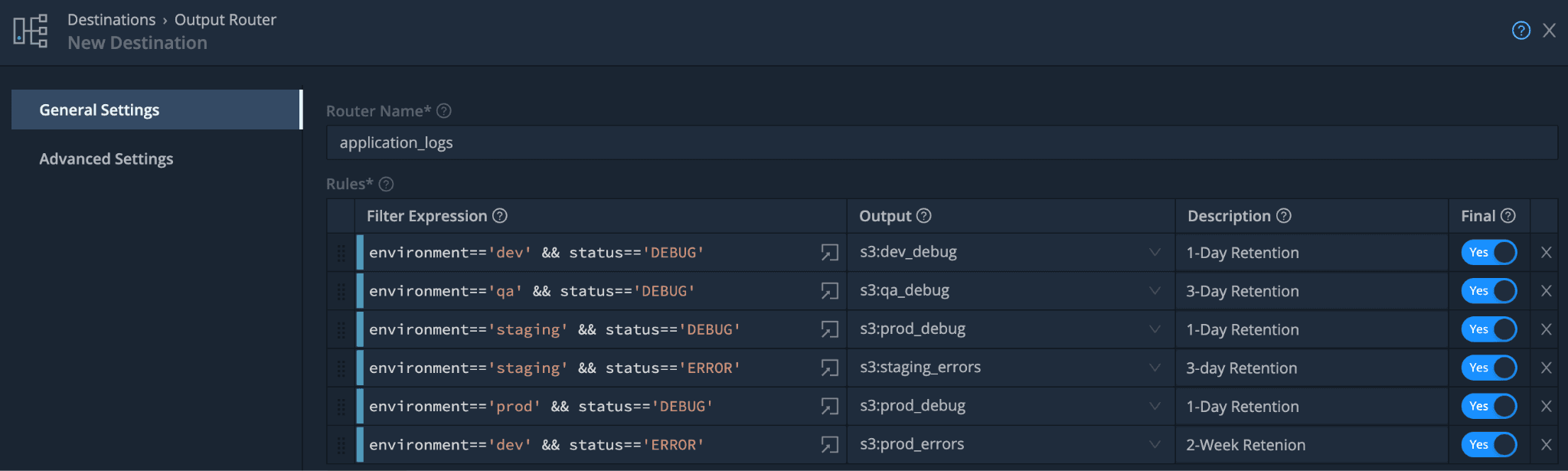
Overall, the pattern looks like this.
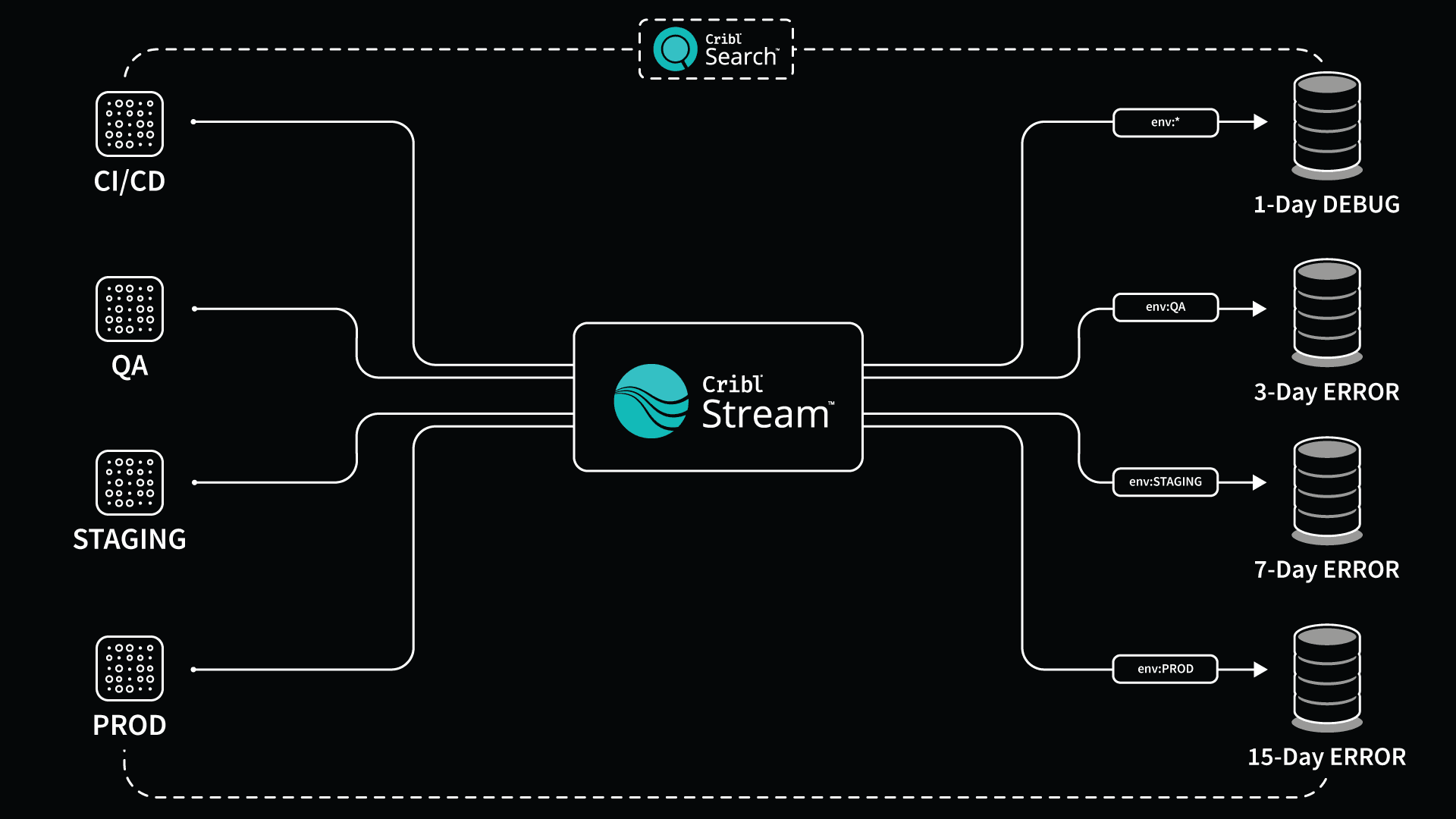
You can see in this diagram that DEBUG logs from all environments are being sent to an S3 bucket and are only retained for 24 hours. Not only are you moving logs to cheap blob storage, but these logs are also compressed using gzip so you will see up to a 90% reduction in storage.
Pro Tip: Use rolling file appenders to store DEBUG logs on the local file system for 1-day retention and never send logs anywhere! Cribl Search can use a common query language to federate searches across clouds and file systems.
Log Appender Setup
In this example, I set up a quick .NET application to generate some transactions, with Serilog as the logging framework. Most logging frameworks will allow you to add additional appenders without modifying the code. This is an easy way for your operations team to easily route logs without having to engage the dev team to make changes. In this instance, I added an HTTP Appender that points to my Cribl.Cloud HTTP endpoint and added a property called env that can be modified by your deployment framework.

In Cribl Stream Cloud
Here you can visually see the logs flowing through Stream. These logs contain PII/PHI data so I can use our Masking functions to scrub and sensitive data before writing it out to blob storage.
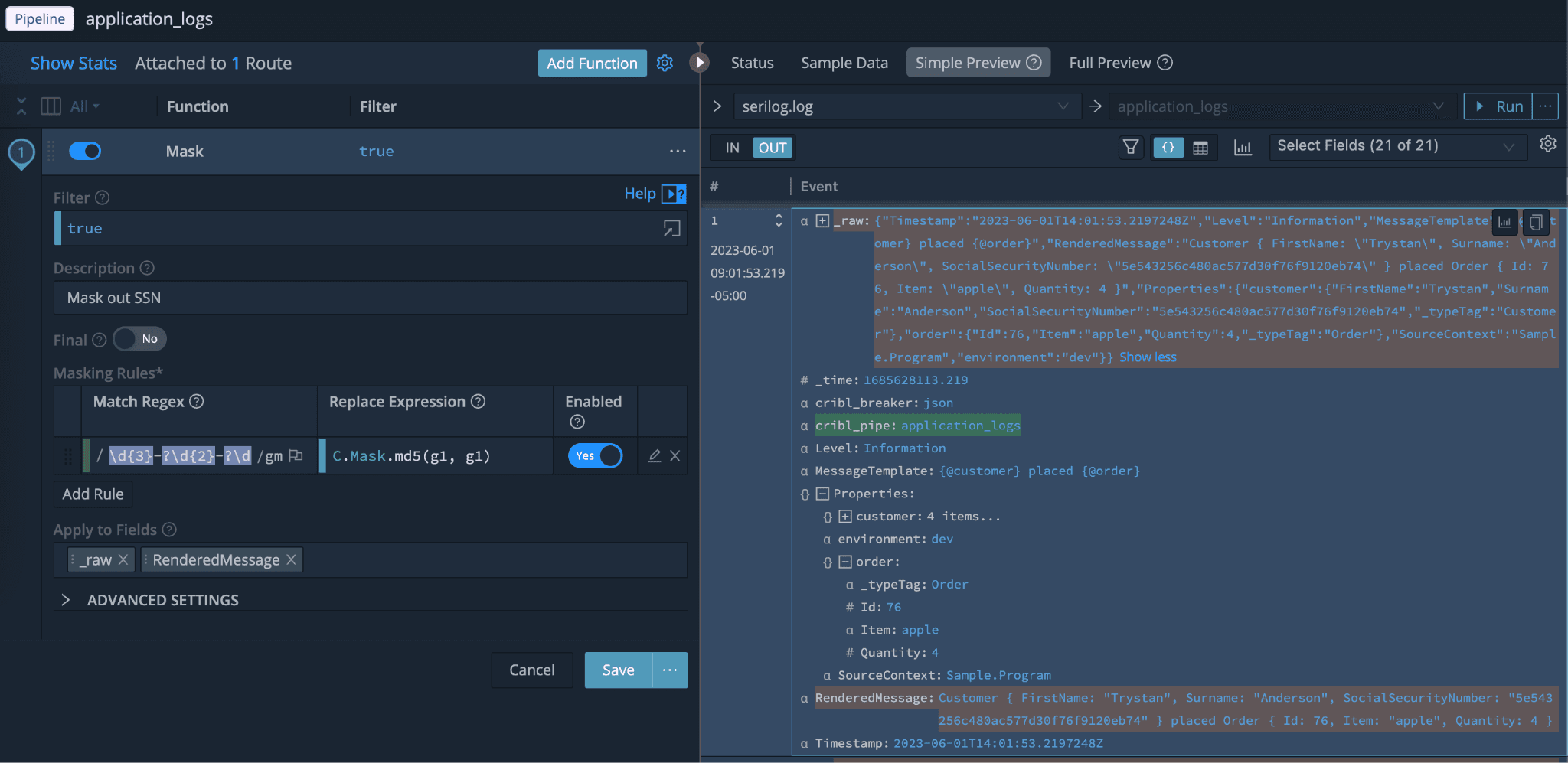
ProTip: Use Sampling/Aggregation to reduce Exception count while still maintaining full observability.
Wrap Up
Using Cribl Stream Cloud plus Cribl Search is a new way to aggregate logs while controlling costs and maintaining full observability. Our unified search capabilities enable you to use the same queries in your local development environment that you do in production. We’re so confident that you’ll love it, that we offer up to 1/TB per day for free to get started. Sign up for a free Cribl.Cloud account today!






