

After writing this post, Jaimie passed away. This blog is a perfect example of the helpfulness and joy she brought to all of the customers she worked with. If you find this content beneficial, consider donating to an organization Jaimie was passionate about: Pug Rescue of Austin.
To keep Splunk running like a well-oiled machine, admins need to ensure that good data onboarding hygiene is practiced. Traditionally, this meant ensuring that your props.conf was configured with the “Magic 8” and that the Regex in your transforms.conf was both precise and efficient. But what if I told you that you could replace your props and transforms Regex code, no matter how large and complex, with a few simple functions within a Cribl Stream pipeline, saving you both event processing time and infrastructure resources?
In today’s blog post, I am going to show you how we helped one of our customers (who we’ll call ACME Corp) replace their whooping 4,000 lines of Regex with a simple three-function pipeline, helping them to stop overloading their indexers (and reduce their overall infrastructure costs) simply by enriching their events using Regex extracts and lookups in Cribl Stream.
Enrichment, the Old Fashioned Way
One of ACME Corp’s resource-heavy use cases is the enrichment of their PCF data, which has been flat-out overloading their indexers.
Pivotal Cloud Foundry (PCF) is a platform for deploying and operating both on-prem and cloud-based applications. Events are typically collected from the PCF Loggregator endpoint and streamed into Splunk via HTTP event collector (HEC). Before being ingested in Splunk, PCF events must first be enriched, typically by using Splunk heavy forwarders to attach the necessary metadata fields.
Before reaching Splunk, ACME Corp requires their PCF data to be enriched with the following fields based on the event’s original sourcetype, which is done in the props.conf and transforms.conf files:
org_name
app_env
index
app_id
new sourcetype
Two bottlenecks make using props and transforms to complete this enrichment painfully slow:
When searching through any .conf file, the search doesn’t stop when a match is found – but instead continues through the entire file. Because of this, the sheer size of Acme’s transform.conf file (~4,000 lines) makes iterating through each and every line a time-consuming chore.
Although Splunk can set more than one metadata field at a time, ACME Corp’s regex was designed to assign each metadata field based on what was set in the previously set field(s); because of this, we can only assign value to one field during each pass through of the regex code, resulting in having to iterate through all 4,000 lines of code for each of the fields for a total of five times.
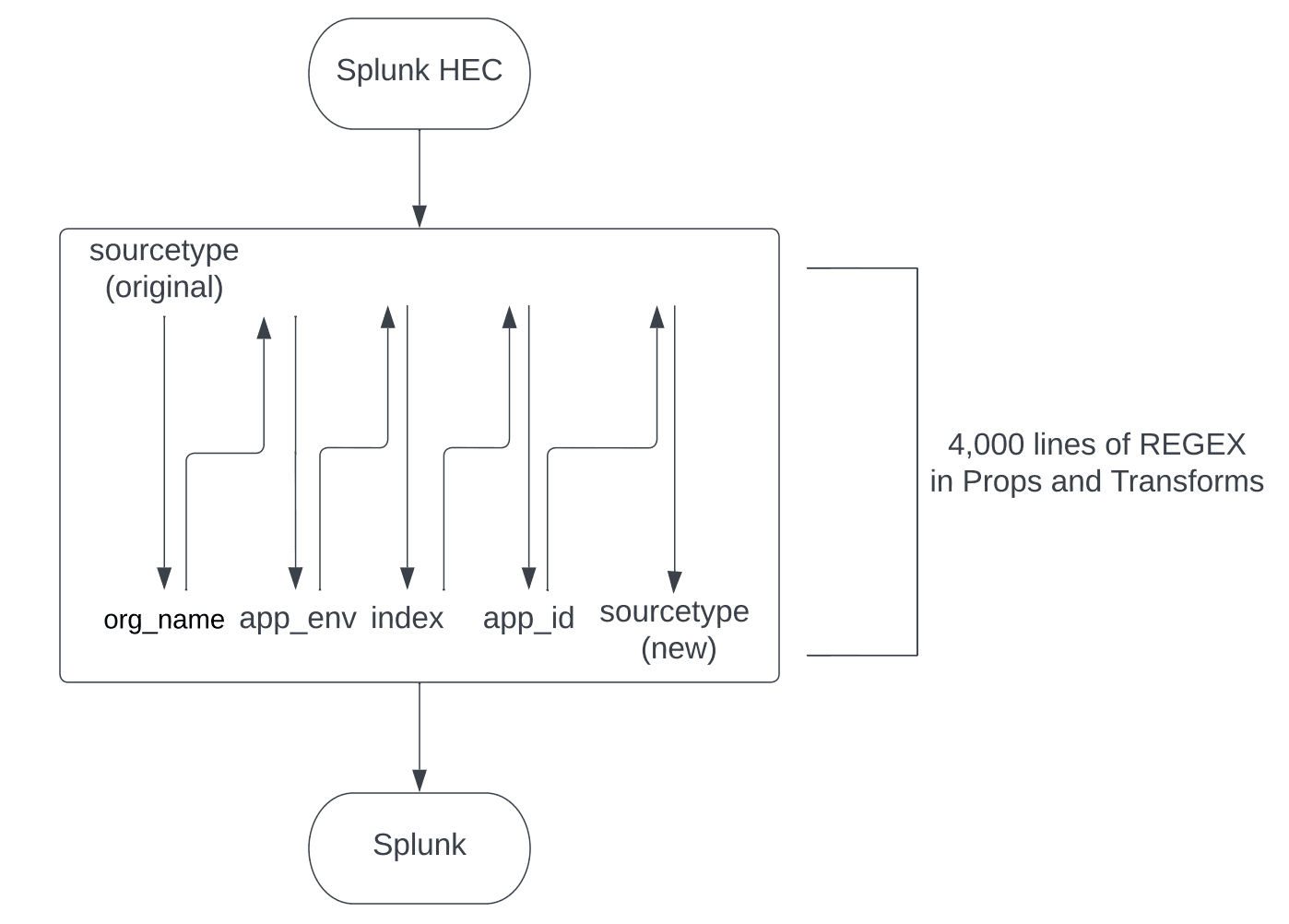
So let’s do the math – that means, for every event, we are basically iterating through roughly 20,000 lines of .conf regex to set five additional metadata fields. Wow. Just wow. There’s got to be a better – fast – sexier way, right?
Cribl Stream to the (Speedy) Rescue
Now let’s look at how we can complete the same exact task using a quick and clean Cribl Stream pipeline. Let’s use the two sample events below (nerd points if you catch the references in the events).
{"cf_app_id":"69db45ea-b89b-43e9-98d7-9d7153635all","cf_app_name":"CA13579-kobol","cf_org_id":"e7ce3eec-dece-48be-95c5-c33f9ff3316a","cf_org_name":"caprica_prod”,”cf_space_id":"b966db927-fe68-4ef6-851e-ebb1495221da","cf_space_name":"caprica-03","deployment":"cf-a10ef785f2016cd492b6","event_type":"LogMessage","ip”:”198.180.167.53","job":"apollo_viper","job_index":"cbdce7db-8df2-4ed34-88b56-7eb4166430da","message_type":"OUT","msg":"2022-04-26 13:59:42,997 WARN c.w.l.e transports.TransportManager - The work queue is at capacity, discarding the oldest work item.","origin":"rep","source_instance":"0","source_type":"APP/PROC/WEB","tags":{"app_id":"69db45ea-b895-48d9-kd84-93kd83kdall","app_name":"CA13579-kobol","instance_id":"0","organization_id":"e7cejd8-d8ec-ke88-dkk9-dakfjdadf8","organization_name":"caprica","process_id":"88ejdnd788-daf88-dk82-dk93-9348jdj83","process_instance_id":"dafdn8238-kmde-3348-dnadf8-383hnd","process_type":"web","product":"VMWare Tanzu Application Service","source_id":”dfadsf882-dj38-338k-d8kd-28jdjduiaall","sp)ce_id":"828djhj38dehj-ddeg-8888-dddd-akjdfakfdk","space_name”:"caprica-03","system-domain":"system.lab.battlestar.galactica.net"},"timestamp":1650981582977105700}
{"cf_app_id":"69db45ea-b89b-43e9-98d7-9d7153635all","cf_app_name":"CA02468-cylon”,”cf_org_id":"e7ce3eec-dece-48be-95c5-c33f9ff3316a","cf_org_name":"leonis_dev”,”cf_space_id":"b966db927-fe68-4ef6-851e-ebb1495221da","cf_space_name":"caprica-03","deployment":"cf-a10ef785f2016cd492b6","event_type":"LogMessage","ip”:”198.180.167.53","job":"apollo_viper","job_index":"cbdce7db-8df2-4ed34-88b56-7eb4166430da","message_type":"OUT","msg":"2022-04-26 13:59:42,997 WARN c.w.l.e transports.TransportManager - The work queue is at capacity, discarding the oldest work item.","origin":"rep","source_instance":"0","source_type":"APP/PROC/WEB","tags":{"app_id":"69db45ea-b895-48d9-kd84-93kd83kdall","app_name":"CA02468-cylon,”instance_id":"0","organization_id":"e7cejd8-d8ec-ke88-dkk9-dakfjdadf8","organization_name":"caprica","process_id":"88ejdnd788-daf88-dk82-dk93-9348jdj83","process_instance_id":"dafdn8238-kmde-3348-dnadf8-383hnd","process_type":"web","product":"VMWare Tanzu Application Service","source_id":”dfadsf882-dj38-338k-d8kd-28jdjduiaall","sp)ce_id":"828djhj38dehj-ddeg-8888-dddd-akjdfakfdk","space_name”:"caprica-03","system-domain":"system.lab.battlestar.galactica.net"},"timestamp":1650981582977105700}
First, Cribl needs to evaluate the original sourcetype on the event to determine how the metafields will be set. For our example below, the sourcetype is “cf:logmessage”.
From there, we need to parse out the org_name field from the _raw, since that is the first field we’ll be using to set the other metadata fields needed. In our first pipeline function, we can actually accomplish two of the five fields using a simple Regex Extract function:

Looking at the events, we can now see those two fields set based on values we pulled from the “cf_org_name” field within the _raw: org_name and app_env.
“cf_org_name”:”caprica_prod”
“cf_org_name”:”leonis_dev”
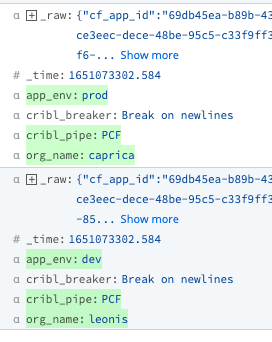
And with one simple function, our work to avoid overloading indexers is almost halfway done – and in a mere fraction of the time.
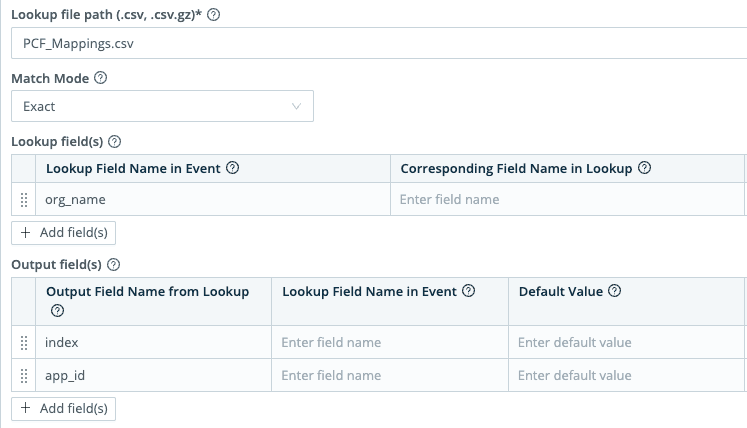
Next, we need to set the app_id and index based on the org_name field. Because the events can be from one of hundreds of different org_name values (based on the app), we’ll want to create a lookup table. For simplicity’s sake in this blog, this is what our lookup table looks like; keep in mind that in a real world production environment, the customer has hundreds of rows, since we were replacing their rather large props and transforms.

Back in our pipeline, let’s add a Lookup function that searches through our PCF_Mappings.csv lookup file to match the index and app_id based on the org_name field within the event.
And there you have it – four of our five fields, enriched!
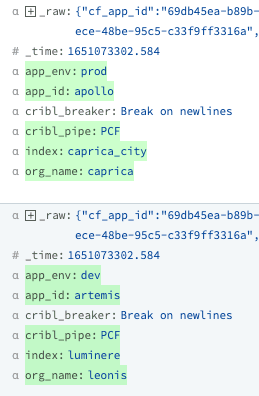
Lastly, we need to add just one more function in order to set the new sourcetype, which is actually going to be a combination of values from the _raw. (The original sourcetype for this event was cf:logmessage) This calls for a Regex Extract function:

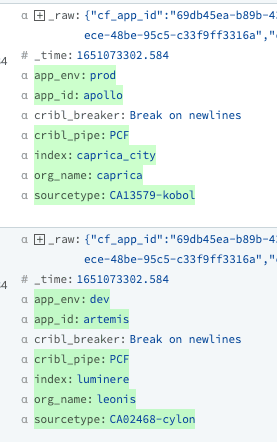
And there you have it – our PCF events are now enriched with five metadata fields that are necessary prior to Splunk ingestion – and literally in a fraction of the time it would take for the props/transforms to complete the task.

Summary on Avoiding Overloading Indexers
Don’t get me wrong – props and transforms have their place in this world and can be imperative for getting your data onboarded efficiently into Splunk. But with new technologies emerging, such as Cribl Stream, it might be time for you to reevaluate whether or not your Ps and Ts can be done in a much easier and cleaner way. Here are some additional resources to check out:
The fastest way to get started with Cribl Stream and Cribl Edge is to try the Free Cloud Sandboxes.








