

An old colleague of mine once said to me, “It doesn’t matter how inefficiently something DOESN’T work.” This was a joke used to make a point, so it stuck with me. It also made me consider that it does matter how efficiently something DOES work. Sometimes, when we have tools like Cribl Stream making things like routing, reducing, and transforming data so easy, we can forget that there might be a more efficient way to do it. When we are getting something working, we are usually testing against a sample set of data and not a full and steady stream. It’s important to think ahead and plan for production levels of data, potential growth, seasonal increases, etc
Having said all this, let’s get into some areas to focus on when building pipelines so that you can build something that will meet your needs and go beyond just getting it working.
Measure Twice (Or at Least Once), Cut Once
In Stream, a Pipeline is a sequence of functions that are applied to the data. The order in which your Pipeline is set up to process data is important. It’s helpful to plan out the processing before building the pipeline. Just like with coding or writing a document, sure, you could just start typing, but it’s better if you have some idea of what you are trying to do before starting. This helps you determine the order that your functions should be used. For example, you would probably want to apply functions to as small a data set as possible, so it would make sense to filter out or drop unnecessary data first. A little planning never hurt anyone.
“Pre-pare” Your Data for Processing
Sometimes there may be a case where you can prepare your data to be more efficiently processed. Stream has a type of pipeline called a pre-processing pipeline that is attached to a Source and allows you to condition / normalize the data before it is delivered to a processing pipeline. Normalized data will likely be easier to process. An example of a pre-processing pipeline can be found in the Cribl Pack for Syslog Input (cribl-syslog-input) available on the Cribl Pack Dispensary.

Less Is More…Efficient
When working with large amounts of streaming data, it’s best to get rid of any unnecessary data as early as possible. I have plastic bins in my basement, full of things that I will probably never need. This makes trying to find something very time consuming and inefficient. The same goes for data. So, tap into your inner Marie Kondo, and get rid of any data that doesn’t “spark joy in your heart”. Ok, it’s unlikely that your data is going to “spark joy in your heart”, so just get rid of data you don’t need as early as possible in your pipeline.
There are a few places to do this. Where you do it will depend on how easy it is to identify whether you can drop it. We can look at reducing our dataset in two ways: what events to drop, and what fields to remove from the remaining events. This section is not necessarily about overall reduction of data but getting down to the minimal set of data to work with before applying other functions that might require a bit more processing power to perform.
Routes
After the pre-processing pipelines, your next line of defense against processing unnecessary data would be Routes. Here you can create a filter that will only send the set of data you need to the pipeline. You can filter on any fields that exist at the point the data comes into Stream. For example, if your source is a Splunk Universal Forwarder, you probably have sourcetype available to you. If you are using a pre-processing pipeline, you may have additional fields available for filtering.

Pipeline – Eval Function
The Eval function can be used to provide further filtering if necessary. Filtering at both the route and pipeline (in an Eval) are limiting the overall set of data. Eval also allows for listing fields to keep, or fields to remove, whichever list is shorter. This is helpful in controlling the size of events.

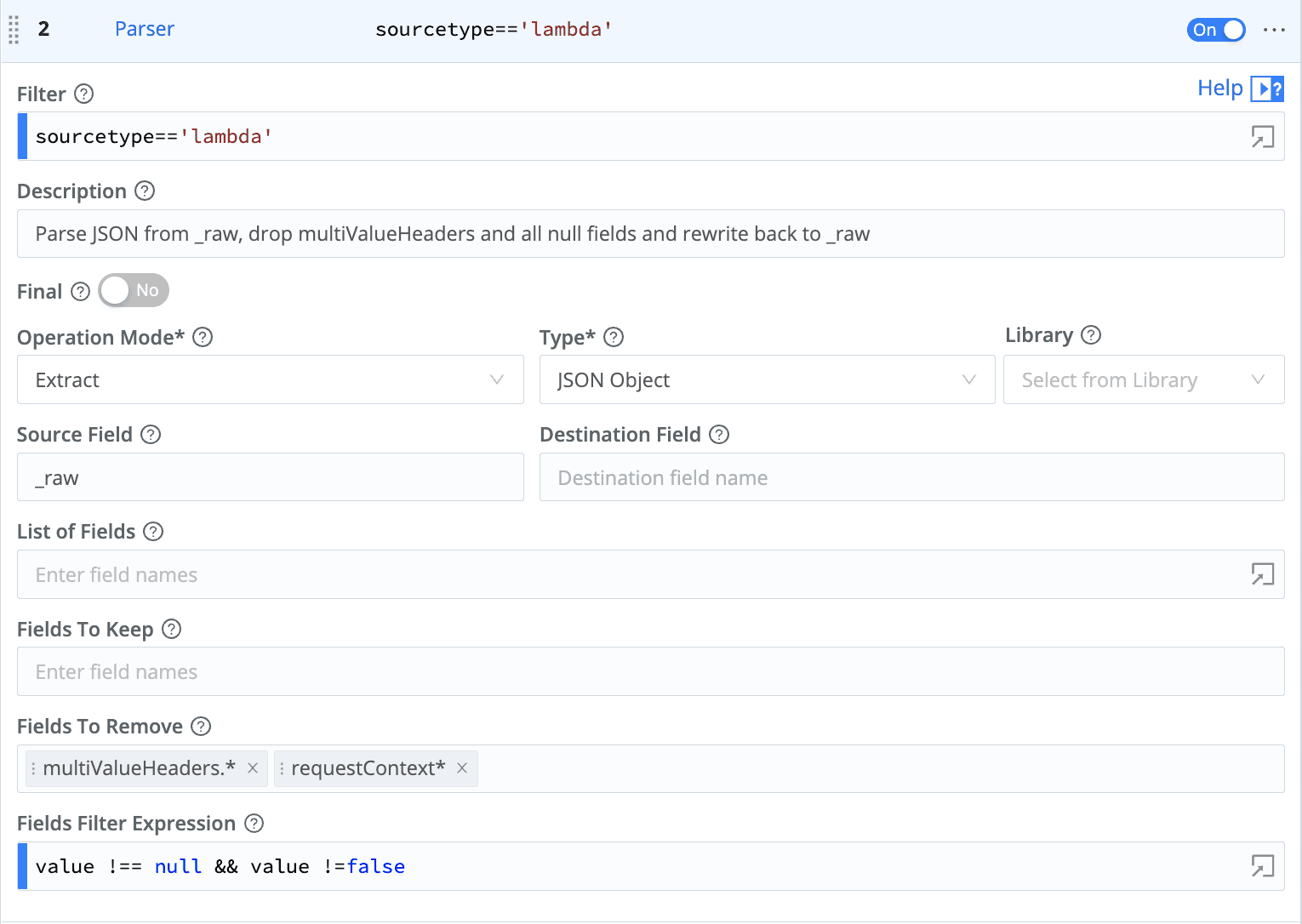
Pipeline – Parser Function
The Parser function can be used to extract fields from your events. Also, just like the Eval function, it lets you list fields to keep or fields to remove. The Parser function also allows for a Fields Filter Expression. This can be used to drop fields when they are equal to a specified value, such as null for example.
Pipeline – Drop Function
The Drop Function allows you to drop more events. This can also be done after you have performed field extractions, allowing you more specificity in what gets dropped.

Working Smart, Not Hard
When adding functions to a pipeline, it’s best to use as few functions as possible to accomplish your goals. The more functions you use in your pipeline, the more invocations of code that will happen. More functions also means more time and resources will be required to process events.
This goes back to planning out your pipeline as I mentioned earlier. If you can have a single function do multiple things, you will be better off. For example, if you have to rename several fields, it’s possible to do this in one invocation of the Rename function. See the example below:

Don’t Be Greedy
Let’s talk about regular expressions for a bit. They are important when it comes to building efficient pipelines. A good understanding of some of the things that make a regex inefficient can make all the difference in your pipelines. Think about the fact that a regex is going to be applied to every event that a pipeline must process. Even if we are talking about sub second differences, you need to multiply that time difference by the number of events being processed.
This is not going to be a tutorial on how to write efficient regex. There are plenty of sources for that out there. Let’s call out a few things that can help improve regex performance.
If you are familiar with regex, you have probably heard the term “greedy”. Remember earlier when I talked about just getting things working vs. making things as efficient as possible? Well, we are all probably guilty of this. It’s easy and quick to write greedy regular expressions. But understanding a little bit about how they work will make you want to find a better way. Consider the following text:
Field_1: 1024 Field_2: 5.1 Field_3: 256 Field_4: .5
and the following regular expression:
.* Field_2: (\d+\.\d+) .*
This is a greedy regex. It’s greedy because it uses .*, which will consume everything up to the end of the string, then it will backtrack until it finds Field_2.
An alternative would be to use a lazy regex. I never thought I would say it’s better to be lazy than greedy. Both options sound like bad character traits to me, but in the case of regex, lazy is better. Here is the lazy version of the regex above:
.*? Field_2: (\d+\.\d+) .*
In this version, it would start from the beginning until it reaches Field_2 and would continue to match the rest of the string.
Could You Be More Specific
Another way to make your regex more efficient is to be a little more specific. One way to do this is to use character classes instead of our greedy friend “.*”. A character class lets you specify what characters to look for or NOT look for. Some examples would be:
[abc] – This will accept any one of these characters in the square brackets.[0-9] – This will accept any one number in the range 0 to 9.[^abc] – This will accept one character not in this list.[0-9]+ – This will accept any number of consecutive digits in the range 0-9.
Anchors Away
Let’s end with one more quick tip. Using anchors like ^ and $ allow you to indicate where the cursor should be within a string. ^ indicates the beginning of a line and $ indicates the end of a line. For example, I can use the following regex to match strings that begin with an IP address:
^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}
would match:
192.168.1.10 10/22/2022 11:57:13 blah blah blah blah
And would NOT match:10/22/2022 11:57:13 192.168.1.10 blah blah blah blah
Time Will Tell
I just spent this entire blog telling you about how to make your pipelines more efficient. It’s only fair that I provide a way to measure how long it takes your pipeline to process events. A fairly easy way to get a rough idea of pipeline performance is to add an Eval function at the beginning of your pipeline and set __starttime to the current time. We prefix our field name with __ because this indicates an internal field, which won’t get passed on to the destination.

This will allow us to calculate an elapsed time at the end of the pipeline. We do this by adding an Eval as the last function in your pipeline that subtracts __starttime from the current time.

Getting Started
So, if all of this sounds great, but you don’t have a way to make use of this information, we have a few ways for you to get started with Cribl Stream. Try it out yourself at no cost.
Also, check out the following related blog: High Performance Javascript in Stream
The fastest way to get started with Cribl Stream and Cribl Edge is to try the Free Cloud Sandboxes.






