

The Core Splunk platform is rightfully recognized as having sparked the log analytics revolution when viewed through the lenses of ingest, search speed, scale, and usability. Their original approach leveraged a MapReduce approach, and it still stores the ingested data on disk in a collection of flat files organized as “buckets.” These immutable buckets are not human-readable and largely consist of the original raw data, indexes (.tsidx files), and a bit of metadata. Read on as we dive into exporting Splunk data at scale, and how it’s made easy by Cribl Stream and Cribl.Cloud.
As Splunk continues to make progress migrating their customers from on-prem or self-hosted platforms to their Splunk Cloud offering, the big question is “what happens to all of the previously ingested data?”. The current Splunk-supported options for exporting data do not address the portability or reusability of this historical data from a scale perspective, even when migrating to Splunk Cloud. Do you keep licensing in place for your historical data until your investigation, hunting, threat intelligence, and regulatory/compliance retention timelines have been satisfied? Someone needs to step up and build a solution for moving that historical data into Splunk Cloud or any other platform that best fits your needs.
I think back on the 2005 movie Robots from time to time and the recurring “See a Need, Fill a Need” theme. The older robots are faced with either expensive upgrades or termination for reasons I don’t want to spoil in this blog. An inventive hero named Rodney Copperbottom stands up against the monopolistic Bigweld Industries corporation to save the day by being the single brave sole armed with his curiosity and persistence.
Splunk customers need a solution to address the portability of this previously-ingested data that is neither expensive nor leaves the data for extinction. It needs to scale, it needs to leverage native Splunk functionality, and it needs to provide the flexibility to allow you, the customer, to format, transit, and use the data exactly as you need. Choice. The solution outlined here involves no proprietary information and you are free to make use of it, with or without Cribl, to migrate your Splunk ingested data into Splunk Cloud, object storage, or any other destination.
The Solution
Splunk includes a command-line switch called “exporttool” which provides the ability to retrieve the original raw events as they were originally indexed by Splunk. As a very important bonus, exporttool also provides metadata such as the original source name, sourcetype, and index time that allow us to organize, route, optimize, and reuse or even replay that data perpetually or on-demand. Exporttool is very fast and can either write data to disk or stream the data directly from the indexer using the CLI. Examples of how to use this command when exporting Splunk data are detailed below.
Export to stdout:
/opt/splunk/bin/splunk cmd exporttool/opt/splunk/var/lib/splunk/bots/db/db_1564739504_1564732800_2394 /dev/stdout -csv
Export to a local csv file:
/opt/splunk/bin/splunk cmd exporttool/opt/splunk/var/lib/splunk/bots/db/db_1564739504_1564732800_2394/exports/bots/db_1564739504_1564732800_2394.csv -csv
Writing to disk is generally not optimal considering that the uncompressed raw data will likely fill your disks and you are still left with decisions for how to best transit, organize, route, and optimize this data to suit your needs. The streaming option of exporttool bypasses storage and disk IO concerns but is still single-threaded which is something we will solve.
Allow me to introduce you to a python script that streams data from Splunk Indexers into Cribl using exporttool via a python script we call scribl.py. This script provides the parallelization of both the exporttool functionality and the transport of data off of each indexer. You point the script at an index of your choosing from your indexer CLI, tell it how many CPUs to use, then assign your Cribl Stream destination IP and TCP port. There are a couple of other options, such as transport via TLS or which time ranges you would like to export, but that’s it. Nothing fancy or overly complicated. Again, send directly to Splunk Cloud for licensed ingest, to object storage, to another platform, or to Cribl for organization, routing, optimization, replay, etc., before sending to any of the aforementioned destinations.
Here is a subtle but important point to consider while exporting from Splunk Indexers: Regardless of your use case, a significant percentage of your ingested data may be overly verbose given the purpose-built needs of many of your destination platforms. If you are moving your previously indexed Splunk data to Splunk Cloud, this is your chance to hit the “reset” button and have Cribl Stream reformat data “in-flight” to ensure you free up ingest volume for additional data sources, reduce storage requirements related to retention, decrease your search concurrency (CPU count), and improve cost/performance across the board.
Any gotchas? The scribl script running on your indexers and the Cribl Stream workers are built to scale and will not be your bottleneck. My scale testing shows Scribl throughput on a single Splunk indexer writing results to local /dev/null/ (no network involved) of more than 19 Gb/sec when assigning 30 CPUs. The same config pushes more than 11 Gb/sec when writing to a single Cribl worker over the network within the same AWS availability zone.
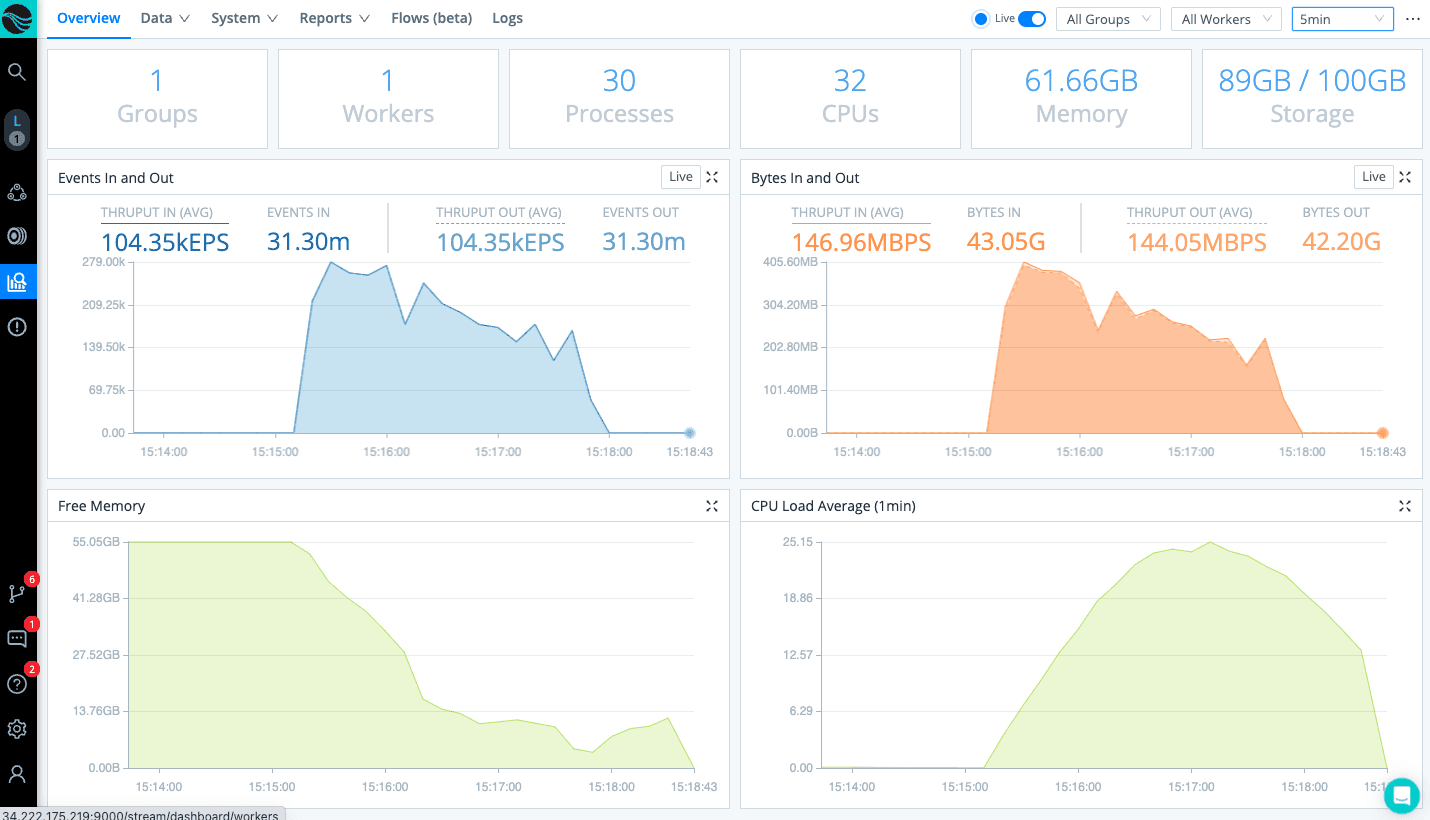
Your bottlenecks will almost certainly be bandwidth constraints between your indexers and your final destination. Depending on where you deploy your Cribl Stream workers, that bandwidth bottleneck might exist between the indexers and Cribl workers or between your Cribl workers and the final destination. If you happen to have unlimited bandwidth, you might find your bottleneck to be the ingest rate at your destination platform.
Exporting Splunk Data: The Details
With exporting Splunk Data, you will need:
CLI access to each Linux indexer with the index/buckets that need to be exported which means this process only applies to on-prem or non-SplunkCloud deployments.
To install netcat on each indexer to act as the transport mechanism.
To make sure outbound communication from each indexer to the Cribl Worker TCP port is open.
Scribl.py is a python script that parallelizes native Splunk exporttool functionality available in the Core Splunk platform as long as you have CLI access to your indexers and can install the OG netcat utility on each of your indexers. Since python is embedded in every Splunk install, all you need to do is copy/paste the script from the repo, install netcat if not already installed, and follow the repo instructions for configuring Cribl Stream.
Scribl needs to be run on each of your indexers independently which is where we achieve an even higher degree of scale by bypassing any bottlenecks related to aggregation components like a search head. As detailed below, scribl will reach into the index that you want to export, build a list of all buckets that need to be exported, then balance the exporting and transiting of the data in each bucket across the number of CPUs that you dedicate to the export process.
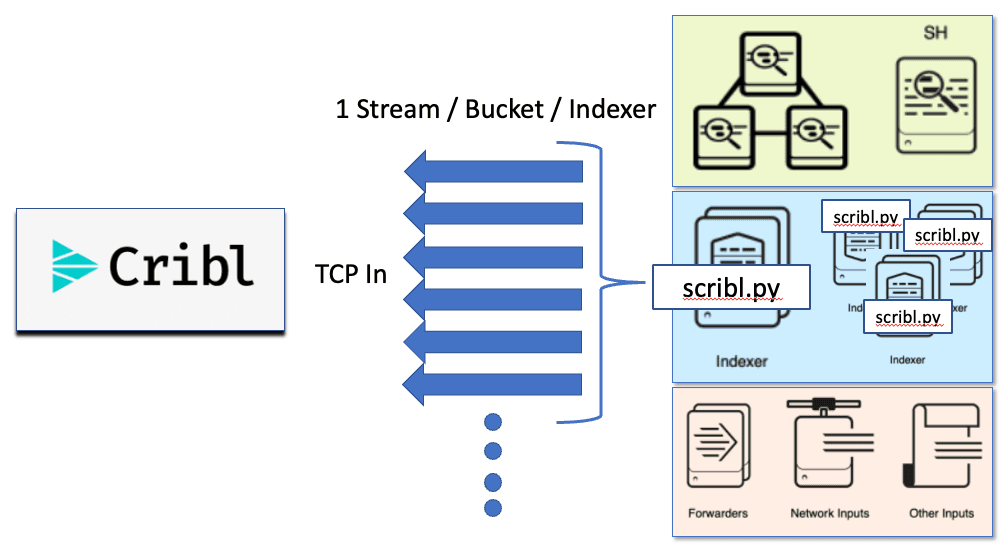
The data will be csv formatted into the following fields when delivered to Cribl Stream:
_time
Source
Host
Sourcetype
_raw
_meta
Cribl Stream performs the following while exporting Splunk:
Load-balancing across multiple Stream Worker nodes for scale.
Event breaking to handle multi-line events with the most common example being Windows Logs.
Provide the ability to filter by original sourcetype for granular optimization (reduction, dedup, aggregation, etc) and routing of data to its final destination.
Ensure the _time value represents the original event time in the _meta field.
Remove the _meta field after it has been referenced for _time.
Perform some formatting to clean up the exporttool output.
The scribl github repo provides you with the scribl.py script, instructions for usage, and for configuring Cribl Stream. Don’t forget, you can use a Cribl.Cloud instance to stream your exported Splunk data to for testing in a matter of minutes. If you want to take scribl for a spin in your lab environment, one of the best ways to do this is to use one of Splunk’s open-sourced Boss of the SOC datasets. They contain pre-indexed data (many sourcetypes) in a single index which you can have scribl export and stream to your Cribl Stream worker node(s) then on to Splunk Cloud or any other platform.
Additional resources you may find useful during your testing of exporting Splunk data include Cribl Sandbox, or the Cribl Docs. For more information on Cribl’s solutions, visit our Podcast, LinkedIn, Twitter, or Slack community.
The fastest way to get started with Cribl Stream and Cribl Edge is to try the Free Cloud Sandboxes.






