
Cribl LogStream often gets compared to more general purpose streams processing engines. “How is this different from Apache NiFi?” is a frequent question from our prospects. In the past few months, we’ve been laying out our vision of an Observability Pipeline, and how one can achieve these benefits, even building your own. We’ve seen people build pipelines on top of engines like an Apache NiFi, but, they’ve usually been for relatively small use cases, no more than a few hundred gigabytes a day. In our experience, systems like NiFi, which allow for a ton of flexibility in use cases, often trade off performance for flexibility. Our testing shows this to be true.
In this post we’ll compare the performance of Crib LogStream vs Apache NiFi for one of the simplest and common use cases our customers run into – adjust the timestamp of events received from a syslog server.
TL;DR Results
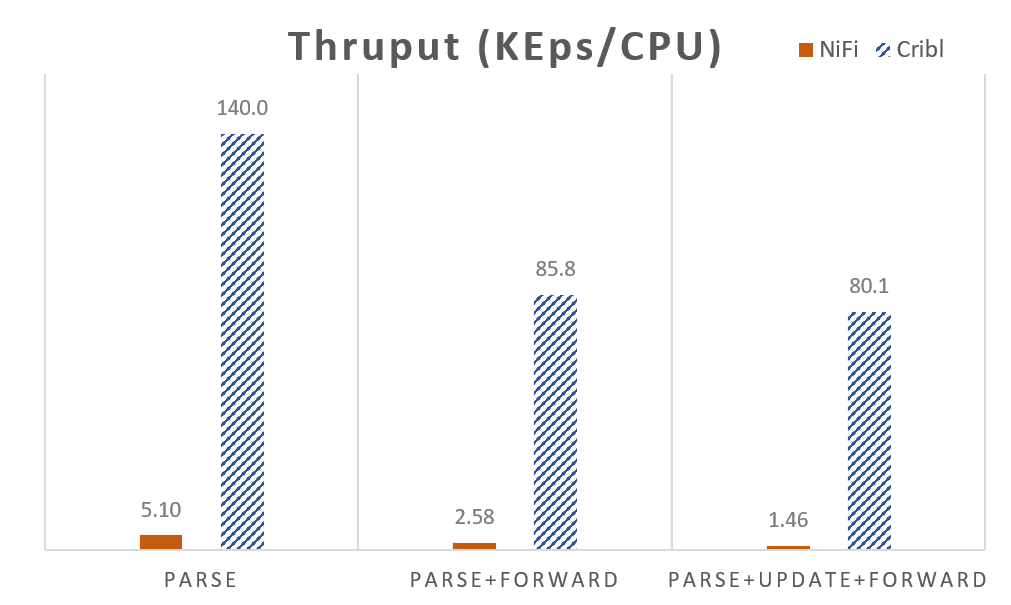
The chart below shows the CPU normalized throughput, (K events/sec) that each system was able to sustain. In the Parse test case Cribl outperforms NiFi by a factor of 27x, in the parse and forward by about 33x and and in full test case by about 55x. As we mentioned in our Scaling Part 2 post, serializing and deserializing network data can become dominating costs in streams processing, and this can be seen in the thruput drop between Parse and Parse+Forward.
Get your hands on experience with Cribl LogStream in a free sandbox environment!
Test Descriptions
Three separate test cases were performed
PARSE – data is sent to each system and each system is configured to drop the data
PARSE+FORWARD – data is sent to each system, which then forwards it to another destination
PARSE+UPDATE+FORWARD – data is sent to each system, the timestamp of events is modified then data is sent off to another destination
Environment & Settings
Testing was performed on AWS c5.2xlarge (8CPU, 16GB RAM) instance running on AWS Linux (ami-0e8c04af2729ff1bb).
$ uname -a
Linux ip-172-31-14-129.us-west-2.compute.internal 4.14.165-131.185.amzn2.x86_64 #1 SMP Wed Jan 15 14:19:56 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
$ ./cribl/bin/cribl version
Version: 2.1.0-d58cfc78
Installation type: standalone
$ java -version
openjdk version "11.0.6" 2020-01-14 LTS
OpenJDK Runtime Environment Corretto-11.0.6.10.1 (build 11.0.6+10-LTS)
OpenJDK 64-Bit Server VM Corretto-11.0.6.10.1 (build 11.0.6+10-LTS, mixed mode)
$ ./nifi-1.11.1/bin/nifi.sh status
# test data
$ zcat syslog.log.gz | wc
15875552 269725643 1944436637Methodology
Each system was ran with default out of the box configuration settings. Cribl LogStream and Apache NiFi were configured to listen on a local port and updated the configurations to perform each of the test cases. When sending data out, each system was configured to send data to another localhost listener that simply drops the data. Two concurrent senders were used to send the test dataset. We measure and report the CPU consumption of all target system processes before and after sending of the data completes. We use the CPU time to compute the thruput instead of wall time as we’re interested in resource consumption normalized throughput.
normalized_thruput = sent_events / cpu_timeWe’ve used the following scripts to measure the CPU consumption. Note, these measurements underestimate the CPU consumption by a small amount as the sender can complete before the destination system has fully processed the last buffered chunks of data.
top -bn1 | grep cribl
zcat syslog.log.gz | nc localhost 6666 &
zcat syslog.log.gz | nc localhost 6666 &
wait
top -bn1 | grep criblNiFi Flow Spec
NiFi was setup as follows, with UpdateAttribute having an expression that updated the time as follows:
${syslog.timestamp:toDate("MMM d
HH:mm:ss"):toNumber():minus(3600000):format("MMM d HH:mm:ss")}
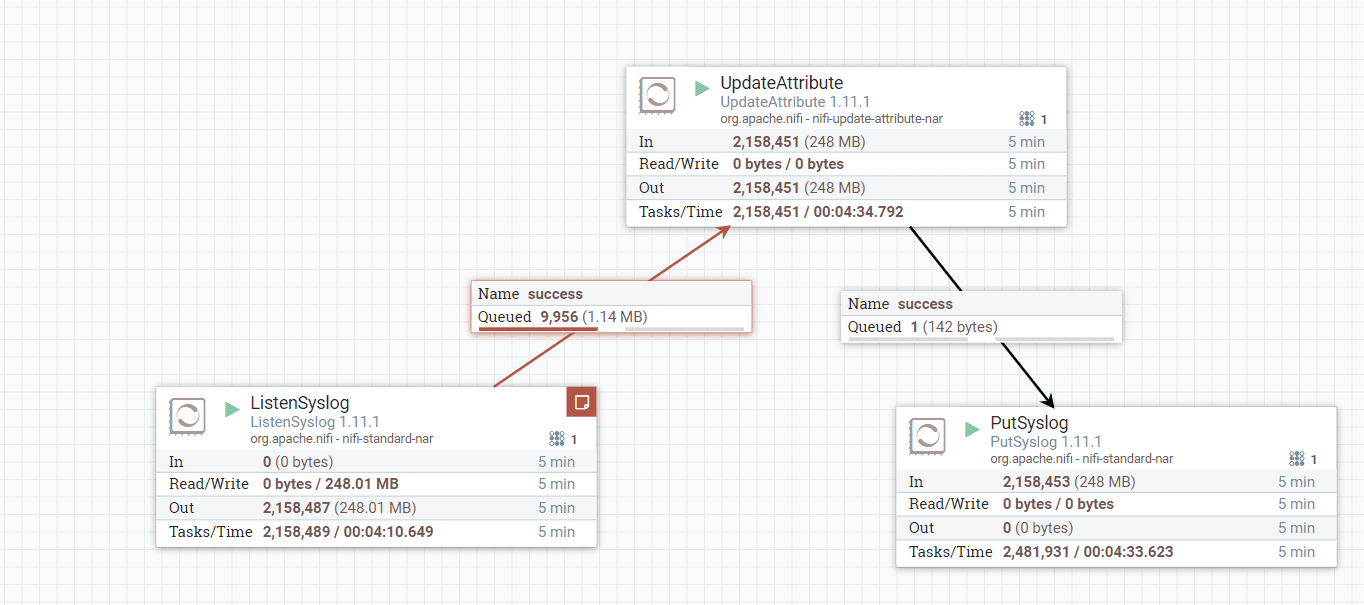
Note in the above flow above the perceived thruput is about 7KEps, once normalized for CPU consumption (see below) the thruput is as reported ~1.5Keps

Results
The chart below shows the CPU normalized throughput, (K events/sec) that each system was able to sustain. In the Parse test case Cribl outperforms NiFi by a factor of 27x, in the parse and forward by about 33x and and in full test case by about 55x. As we mentioned in our Scaling Part 2 post, serializing and deserializing network data can become dominating costs in streams processing, and this can be seen in the thruput drop between Parse and Parse+Forward.
Wrapping Up
In the coming weeks we’ll post performance comparison results against a few other tools we’ve come across in the market. If we find we are slower in basic use cases, we will happily highlight it. We are by definition experts on our system and not others, if we’ve missed a “GoFaster = true” setting or any other questions or suggestions please reach out!
One more thing, we’re hiring! If the problems above excite you, drop us a line at hello@cribl.io or better yet talk to us live by joining our Cribl Community.




