
If one thing has become crystal clear in the last few years as we’ve entered the market, it’s that the need for Cribl Stream is pervasive. Cribl Stream implements an observability pipeline, which allows you to route machine data from any source to any destination while transforming it in motion to enrich it with additional context, secure its contents, and control costs. In this post, we’re going to explore alternative build strategies for implementing an open source observability pipeline on top of other popular projects like Fluentd, Logstash or Apache NiFi, and compare that to Cribl Stream approach.
(For more info on an observability pipeline, read our thoughts as well as Tyler Treat’s thoughts on the value prop and the problems we are solving).
There is much to be said for custom engineering your own solution to this problem. It will be tightly integrated into your workflow. It will create career opportunities for engineers. It will be exactly what you need and nothing more. A custom tailored suit is going to fit better than something taken off the rack.
If you’re building an observability pipeline, we believe in order to solve the problem effectively, there are a number of properties you will need: protocol support for existing agents, an easily manageable system, and performance. Not coincidentally, Cribl Stream includes these out of the box. However, we also encounter a number of prospects who are considering building their own observability pipeline on top of a number of open source projects like Apache NiFi, Fluentd or Logstash. We’ve seen prospects and customers be successful at this, but for all of them it’s a journey, usually a costly one, that involves potentially major architectural shifts and building a number of things on top of the base open source bits. In this post, I’m going to outline what we’ve seen successful builders implement above the base open source bits to solve the real business problem helping to connect all your machine data systems cost effectively.
Protocol Support
The first, and biggest, struggle with implementing an observability pipeline is protocol support. We speak with customers regularly who have 10s to 100s of thousands of deployed agents already. If your agents are proprietary, like the Splunk Universal Forwarder, you’re looking at step 1 being a major uplift to replace all your existing agents or at a minimum install a second agent collecting the same data.
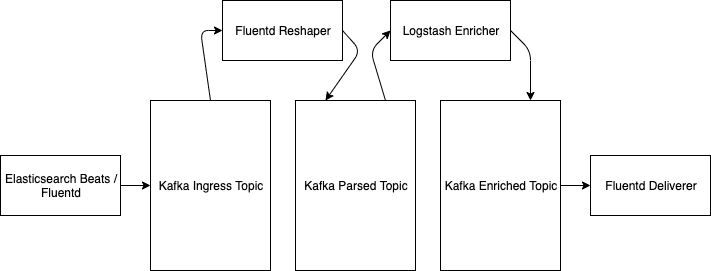
If your agents are already open source agents like Elasticsearch’s Beats or Fluentd, you can probably implement Apache Kafka as an interim receiver to pre-preprocess before sending onto Elastic, but you’re now adding a new stateful distributed system to your pipeline which still does not solve the end to end use case. To solve the real problem, including transforming and processing the data, your pipeline isn’t simple. It’s going to include multiple processing steps, with additional processing software like Fluentd pulling data off of topics and a second copy on a different topic, like this:
In addition to supporting agents, an observability pipeline should also be able to support wire protocols like Syslog, Kafka, Kinesis, or Splunk’s HTTP Event Collector. It should be able to receive data natively, without setting up a separate connector software infrastructure.
Cribl Stream supports all the existing data producers in the market, so it can drop into an existing pipeline and emulates the destination to the producer. It looks like a Splunk Indexer to a forwarder, or Elasticsearch to Beats or Fluentd, allowing us to simply be a bump in the wire. The first use case in nearly all our opportunities is simply to be a passthrough pipeline. Stream’s protocol support means you don’t have to make a major uplift in your architecture.
Programming Your Pipeline
The second major challenge we see with building an observability pipeline on top of a generic streams processing engine is how much work is left to the administrator. Systems like Apache NiFi are very very flexible. You can use them to transport even binary data from the edge. You can use them as a passthrough, routing arbitrary bytes from one Kafka topic to another. From the Apache NiFi documentation, “Apache NiFi is a dataflow system based on the concepts of flow-based programming.” NiFi is a graphical environment, but most generic streams processing engines are providing a programming environment to their end users. Programming a streams processing engine requires end users to work at a much lower level. Extreme flexibility comes at a cost of requiring the user of the system to reimplement many things which are done out of the box in logging systems.
In logging systems like Splunk, Elasticsearch, etc, there is a good amount of work handled for you by combination of the shipper and the storage tier, like a Splunk Forwarder or Elasticsearch Beats, and Elasticsearch or a Splunk Indexer. The shipper picks up a byte stream off of disk, and it may do lightweight parsing on the endpoint to break that bytestream up into events, or it may ship raw bytes off and do event breaking at the centralized tier. Either way, from the user’s perspective, the concept of an event is the base unit of work. If you’re trying to do put something like Apache NiFi in the middle of your ingestion pipeline, it is incumbent upon the developer to do things like event breaking. This is possible, but it adds a lot of work. To build your own observability pipeline on NiFi or a similar system, you will need developers to implement event breaking for you.
Cribl Stream is a no-code configurable solution, which works natively on events, just like most of our sources and destinations. Stream also handles event breaking natively and intuitively in the product when sent a raw bytestream. Stream does not require you to be a developer to work with observability data.
Building Your Own Management
When thinking of implementing a system, most projects and products tend to focus on the day 1 problem: “how does the user get this up and running?” (See https://dzone.com/articles/defining-day-2-operations for definitions of Days 0-3). However, over the lifetime of the solution, Day 2 questions like “how does the user make changes safely and reliably?”, “how does the user know if the system is performing properly?”, or “how does the user troubleshoot this system?” are left to the implementer of the system. Log processing tools like Fluentd and Logstash are okay on day 1. Downloading them on your laptop, throwing some data through, and building an initial configuration are pretty easy to do.
Managing configurations and configuration changes require a significant investment on top of your base system like Fluentd or Logstash. Shops building their own observability pipelines successfully have built their own unit testing frameworks for configurations and intense code and configuration review processes. These processes weren’t invented for nothing. Before implementing these processes, minor configuration errors would regularly break production. This also involves implementing your own continuous deployment pipeline to roll changes safely to production.
On top of CI/CD which needs to be built, monitoring comes next. If data is coming in delayed or the system slows down for any reason, metrics need to be available to determine which system is causing back pressure or which particular set of configurations might be the culprit. One bad regular expression can destroy performance of a data processing system. Building up rich monitoring dashboards are a huge part of the Day 2 cost of building your own system.
Lastly, when data is not being processed in the way in which the end users are expecting, the operators of the system need to be able to reproduce data processing so they can validate why a given configuration produces a given output. There is no environment like production. Attempting to take a configuration and an environment where the given conditions reproduce the problem can be hugely time consuming. Tools like Fluentd and Logstash provide little in the way of introspection, data capture, or troubleshooting capabilities.
Cribl Stream provides configuration validation in product, with built in distributed management and monitoring, and provides rich data capture capabilities to help you troubleshoot your data flows in production.
Performance
As we’ve written about recently, in our market we are working with prospects moving data at multi-petabyte daily volumes. At that scale, a 20% improvement in processing speed can have impacts in the tens to hundreds of thousands of dollars a year in infrastructure costs. Fluentd and Logstash have had long known performance challenges. Generic systems like Apache NiFi are not designed for petabyte/day scale. Over the course of the next few months, we’ll publish official benchmarks, but our initial testing shows Cribl Stream is multiple times faster for the same use cases as open source tooling. You should do your own testing to validate, but building your own system may be very costly from an infrastructure perspective at scale.
Cribl Stream is performant and can pay for itself many times simply in infrastructure savings.
Conclusion
An observability pipeline is a new concept, and we are seeing some successful home built implementations. Of the users we speak with who have gone down this path, most are very happy with their implementations. Many might have considered us at the time they embarked on their journey to build out all the capabilities outlined here. The purpose of this post is not to disparage these other projects, but simply to highlight solving the business problem requires a full solution and the existing projects are not yet solving the full solution needs without a lot of integration and building effort on the part of their users.
Organizations which head down the path of building should prepare for a non-trivial investment. For organizations we’ve spoken to who have built, most are investing 2-5 resources from 3-12 months, depending on the sophistication of their requirements. Putting this in real dollars, a build option starts at around $100k, and up to $1m or more, for the first year. In addition to the initial build, a continual investment of a scrum of 1-3 developers to write transformation code puts the sustained maintenance in the hundreds of thousands a year. We’ve spoken to prospects with over 100 developers writing Apache Spark data transformation code to accomplish an observability pipeline, so our estimates are on the very small side. Building may best satisfy your requirements, but it is not cheap. Building will invest precious resources into undifferentiated infrastructure and process.
Cribl Stream provides a full solution out of the box, and we’re committed to giving our customers an in-year ROI. If building out all this functionality seems like it’s not core to your business, we’d love to talk to you about implementing our solution to this problem. If you think your solution is really awesome, we’d love to hear about how you’ve solved this problem! We want to highlight successful observability pipeline implementations, regardless of whether they were using our product, because we believe there is much to learn from one another.
Cribl, the Data Engine for IT and Security, empowers organizations to transform their data strategy. Customers use Cribl’s suite of products to collect, process, route, and analyze all IT and security data, delivering the flexibility, choice, and control required to adapt to their ever-changing needs.
We offer free training, certifications, and a generous free usage plan across our products. Our community Slack features Cribl engineers, partners, and customers who can answer your questions as you get started. We also offer a hands-on Sandbox for those interested in how companies globally leverage our products for their data challenges.







