


What is observability? Observability is a way to watch and understand your system so that you anticipate and prevent future problems. This methodology provides greater visibility into the log data of your enterprise. It helps determine the state of the system from the knowledge of its external outputs.
Implementing observability allows IT teams to find actionable insights into the system's health and understand if something is not working well. That way, they can fix those problems before they become bigger issues.
As the architectures of IT systems are becoming more complex, manual troubleshooting isn’t efficient enough, so we use observability to meet the need to measure their internal states.
Where to start with observability, why is it important and how does it work? We are breaking it all down in this article.
Key takeaways:
What is observability: A way to monitor the performance of your systems.
Why observability is important: Because it can help you predict potential issues.
Observability benefits: Gives better control of your data, helps distributed tracing, helps to monitor data trends, etc.
How to implement observability: By first determining your goals and all your DevOps and other teams' needs.
Observability Tools: To choose the best observability tool, go with one that is flexible, easy to use, and reduce additional costs.
What is Observability?
Observability is defined as a concept, a goal and direction that will help your organization to gain the most insight from the data you can collect. It helps companies diagnose performance issues and resolve issues before they become more significant.
The idea of observability has its roots in control theory, a field of engineering developed in the 1950s. In this context, observability describes the ability to determine the internal state of a system by examining its external outputs. This principle was essential for designing reliable machines and automated processes. As IT systems evolved from simple, monolithic applications to today’s distributed environments, often made up of dozens of microservices running across cloud and on-premises infrastructure, the need for a similar approach in software became clear.
Today, observability is about understanding how systems and applications perform in the real world, especially as environments grow more complex. Manual troubleshooting is no longer enough, so observability provides the visibility needed to measure internal states and anticipate issues before they impact your business.
One way to build your ideal observability solution is to look at it the same way you would a security solution. If you’re in the market for improved security for your network and endpoints, you can’t just ‘go out and buy it.’ All you can do is purchase security components that you will need to architect to meet your unique security needs. That’s how you should approach observability – start with a goal and then work backward.
There are no one-size-fits-all observability solutions because what your company requires is going to be very different from the rest. Each organization will have its own approach and requirements.
IT and security teams can interrogate system behavior without the limits imposed by legacy methods and products. Plus, it provides more control to employ the amount of visibility that is needed.
Observability Examples
When you go to an office, you would use your badge to get access. When you scan your badge, data is generated, such as your name, when you entered, and which entrance you used. Each person who enters the building generates log data. To gather, reduce, and clean up all the data and then send the valuable information to your analytical tool, you need a tool such as Cribl Stream. This is an example of a system that is observable.
Learn more about use cases and examples.
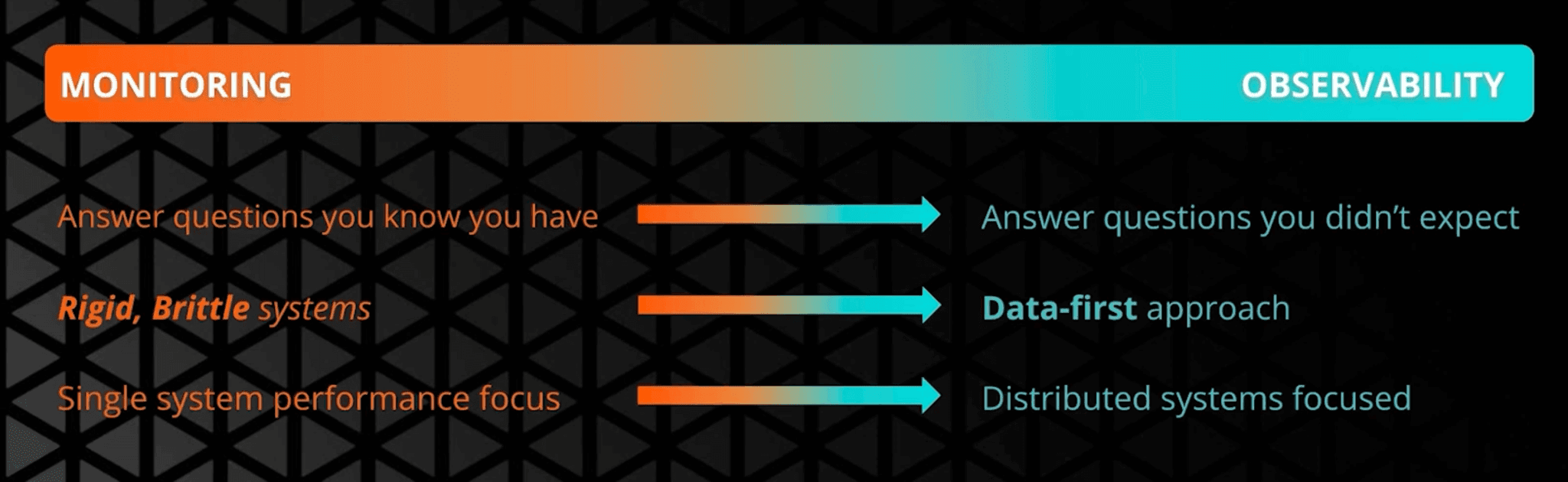
What Is the Difference Between Monitoring and Observability?
Monitoring is designed around predefined dashboards and alerts that tell you when known conditions occur. Observability is what you use when you need to explain unexpected behavior by analyzing a system’s outputs in context and working backwards to root cause, which is why the distinction matters in practice when you compare observability vs monitoring vs telemetry.
Why is Observability Important?
As architectures become more distributed, the hardest outages and degradations are often the ones you did not instrument for in advance, which makes discovery as important as detection. Observability matters because it helps teams uncover new signals, connect behavior to impact, and reduce time-to-resolution across complex environments, a theme we go deeper on in The Strategic Importance of Observability: Discovery to Data Control
Observability Benefits
Observability Benefits IT and security teams with greater control over system data, enabling them to efficiently manage and analyze logs, metrics, and traces. A well-implemented observability strategy allows organizations to:
Enhance Data Usability and Accessibility – Ensure critical insights are readily available for faster decision-making.
Optimize Storage Costs – Reduce unnecessary data retention by filtering and routing only relevant information.
Streamline Data Collection – Simplify the ingestion process, making it easier to aggregate and process system telemetry.

Learn more about the benefits of observability.
Observability Challenges
While observability provides valuable insights into system performance, it comes with challenges that organizations must address to maximize its effectiveness. Some key limitations include:
Overwhelming Data Volume – Modern IT systems generate vast amounts of telemetry data, including logs, metrics, and traces. Without proper data filtering and management, organizations may end up storing excessive, unnecessary information—only to discard a significant portion later.
High Costs of Data Processing and Storage – Collecting and analyzing large volumes of data can become expensive, especially when organizations attempt to retain everything without optimizing for relevance. Costs can quickly escalate due to increased infrastructure requirements, storage fees, and data transfer expenses.
Tool Sprawl - Managing multiple tools can introduce inefficiencies and increase costs, as teams must juggle different interfaces, data formats, and methodologies.
Complexity of Modern Environments - The shift to microservices, containers, and hybrid cloud environments makes it harder to achieve end-to-end visibility without sophisticated observability strategies.
Alert Fatigue - Excessive alerts, especially false positives, can lead to teams missing critical issues and reduce the effectiveness of observability investments.
To overcome these challenges, organizations should implement strategic data filtering, compression techniques, and cost-efficient observability pipelines that prioritize actionable insights while minimizing unnecessary storage and processing costs. Consolidating tools, setting clear data retention policies, and leveraging automation can also help teams maintain visibility and control costs.
The Pillars of Observability and How Does it Work?
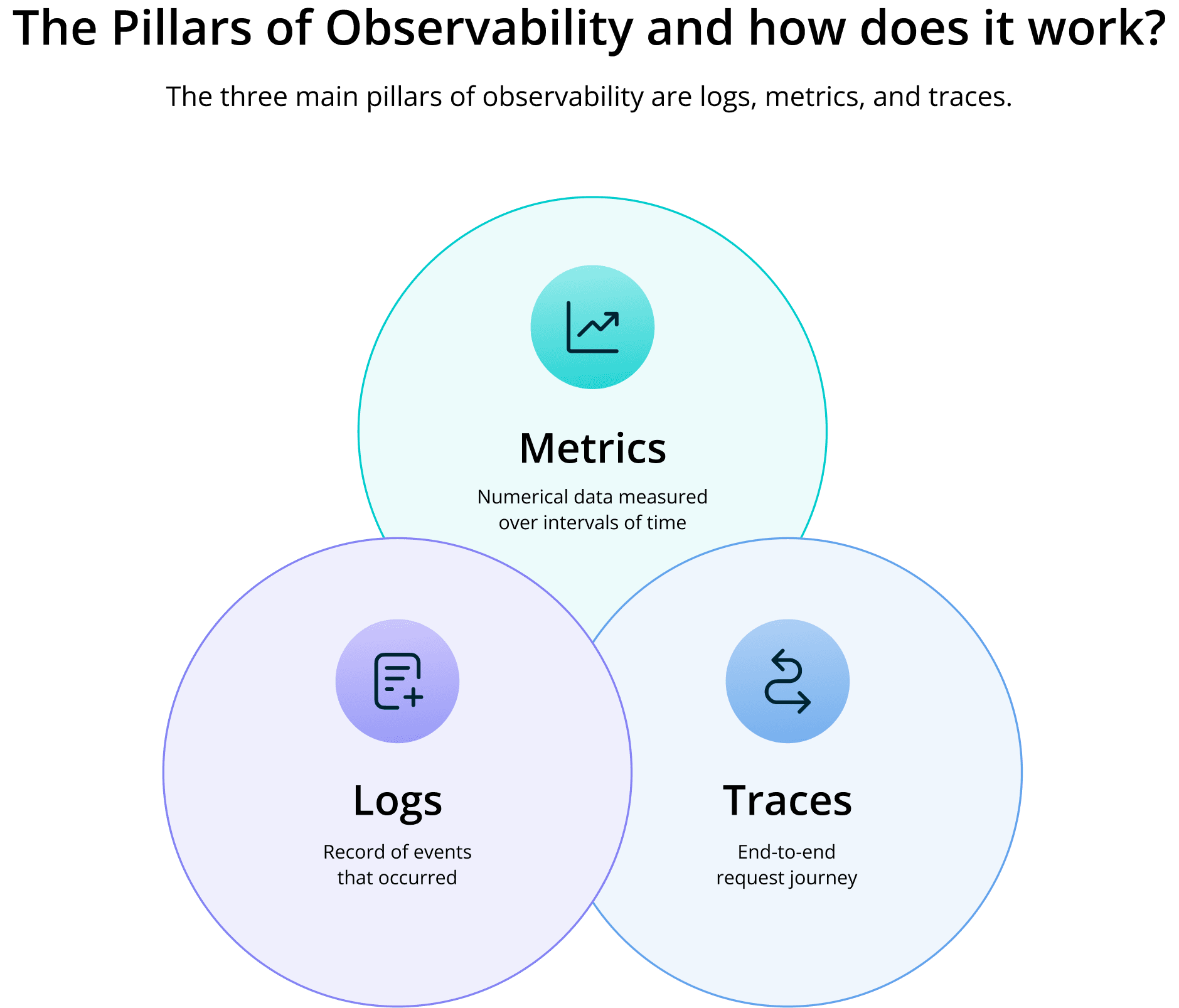
Observability is often summarized as logs, metrics, and traces, but in real environments, the value comes from correlating signals based on the problem you are solving rather than treating each signal as a separate “pillar.” That framing is why we recommend thinking in layers instead, as described in The Layers, Not Pillars, of Observability.
How Do You Implement Observability?
Start with your hardware and software systems. Here are some questions you need to answer:
Do you have IaaS up in the cloud?
Are you utilizing SaaS?
Do you already have observability systems?
If you have systems on a freemium contract with restricted capabilities, you may want to upgrade licenses. If you use open source, you should know that even though it is free, there can be unexpected costs that add up when you actually start working with it.
After you get an understanding of your current capacity and capabilities, you can start to think about what you need to move forward based on what needs are not being met today.
Get in touch with each department that has an interest in observability and figure out exactly what each of them needs. ITOps, AIOps, DevOps, and your SREs should all be able to tell you what they need or which tools they can’t live without.
After you get an idea of what everyone needs, you want to talk about the sources you are currently capturing data from. Log shippers, applications, network devices, and customers’ instrumentation that your software developers may have built will all collect and forward data at some level. Find out exactly what your stakeholders are missing — which events, metrics, or data do they need, and from which devices?
Then there’s the other side of the data pipeline coin: destinations. Where does that data you collect actually go? These are your log servers, systems of analysis, and storage that can be either on-premises or in the cloud, databases, search engines, APM, systems API collector, or any custom systems that were developed. Decide what might be missing here as well, and then figure out if all the data you bring in is being processed correctly.
Finally, you should embed observability in your management and continuously monitor the metrics.
Learn more about how to implement observability.
How Do You Make a System Observable?
An effective way to make a system observable is to build a highly flexible observability pipeline.
An observability pipeline is a strategic control layer positioned between the various sources of data. It allows the user to ingest data and get value from it in any format, from any source, and then direct it to any destination. The result – better performance and reduced application and infrastructure costs.
How Do You Deliver Data to Your Analytical Tools?
Data usually streams in real-time from collectors to analytical tools through pipelines. The pipeline also identifies and transforms the data in the required format. Once the data is collected, you have to analyze it.
Given that there are multiple tools analyzing overlapping pieces of the same data, organizations quickly start to find this process to be quite cumbersome. A highly flexible observability pipeline helps minimize this.
Currently there are plenty of good observability tools and observability platforms available on the market, depending on your needs and preferences. Some popular options are Cribl, Datadog, Elastic.
How to Optimize Observability?
Observability is a combination of tools, services, engineering designs and systems of analysis, all working together.
To optimize observability, you must seek to understand the ways in which the IT systems impact the goals of the organization. Then, you must question how your systems, applications, or network operate to ensure those impacts and translate these questions into measurable answers. Depending on the types of measures that are considered acceptable to the organization, you can understand how the internal system is running.
What is the Future of Observability?
The future of observability is being shaped by the rapid evolution of IT environments, the explosion of telemetry data, and the need for deeper, faster insights across increasingly distributed systems. While pervasive application instrumentation-embedding high-fidelity data collection directly into applications-remains foundational, several key trends are redefining what’s possible and what’s necessary.
OpenTelemetry and Standardization
OpenTelemetry (OTel) is rapidly becoming the industry standard for collecting and transmitting observability data. By unifying how telemetry is captured across different platforms and vendors, OpenTelemetry breaks down data silos and reduces reliance on proprietary agents. This standardization enables organizations to simplify instrumentation, increase flexibility in tool selection, and lower operational costs. As it matures, expect deeper integrations with AI, improved trace context propagation, and broader support from major vendors.
Cost-Efficiency and Data Management
As data volumes soar, controlling observability costs is a top priority. The future will see greater adoption of intelligent data filtering, adaptive retention policies, and dynamic observability pipelines that scale data collection based on system activity. Organizations will focus on capturing only the most valuable data, consolidating tools to eliminate redundancy, and leveraging tiered storage to optimize spend-all without sacrificing insight.
A Strategic Advantage for the Business
Observability is expanding beyond IT operations to become a strategic enabler for development, security, and business teams. Unified platforms, AI-powered automation, and open standards are making it possible to link system health directly to business outcomes, drive innovation, and deliver better user experiences.
As these trends accelerate, organizations that embrace modern observability practices will be best positioned to manage complexity, control costs, and unlock the full potential of their digital ecosystems.
Check out the entire video by Clint Sharp, CEO of Cribl on the topic.
FAQs
What is observability?
Observability is the practice of understanding a system’s internal state by analyzing its external outputs, such as logs, metrics, and traces. It helps teams diagnose issues, optimize performance, and maintain system reliability.
Why is observability important?
Observability allows organizations to detect and resolve issues faster, improve system stability, and optimize performance. It provides full visibility into complex IT environments, helping teams proactively manage and troubleshoot systems, address unknown problems, and enhance user experiences.
What are the three pillars of observability?
Metrics – Numeric data points that track system performance (e.g., CPU usage, response time), offering a quantitative view of health and trends.
Logs – Event records that provide detailed insights into system activity and help trace the sequence of events leading to issues.
Traces – End-to-end tracking of requests moving through different services, revealing dependencies and pinpointing bottlenecks.
What’s the difference between monitoring and observability?
Monitoring tracks predefined metrics to alert teams when known issues occur—it's reactive and focused on “what” and “when.” Observability analyzes logs, metrics, and traces to understand “why” issues happen. It enables deeper insight into complex systems and helps diagnose both expected and unexpected problems proactively.
How do you implement observability?
To implement observability, organizations should:
Instrument applications and infrastructure to collect logs, metrics, and traces.
Use centralized observability platforms to analyze and correlate telemetry data.
Optimize data collection by filtering and routing relevant information to the right destinations.
Leverage automation, including AI and machine learning, to detect anomalies and accelerate root cause analysis.





