

Over the last 15 years, digital technology has fundamentally changed the way businesses operate. Every industry, from retail and hospitality to banking and airlines, has not only had to adjust to a world where customers increasingly rely on digital experiences, but they also have to build and manage the platforms where these experiences take place.
Nowadays, it’s not only easier than ever to buy groceries, deposit a check, or book a hotel reservation online, but it’s become our preferred mode of action. I remember not too long ago, when I wanted to book a flight, I called up an airline and said, “I’m gonna go from here to there,” and they handled everything for me. Now I’m doing all of this on my own inside that same airline’s app. Everything has gone digital, and as a result, every business is now a software company.
With Digital Transformation Comes High Expectations
Since every enterprise is essentially a software company, customer expectations for the performance of that software have gone through the roof. Not only do banks and airlines need apps that allow everyone to make all of their transactions and travel arrangements through their phones, but they also have to make sure that their apps and service work perfectly 100% of the time.
Even if only 1% of users are having a shit time, you’re in trouble. Those people then go to Twitter or they’re calling your service desk and they’re royally pissed off. And it’s easy for customers to switch if they have a bad experience — it’s as simple as downloading a new app or visiting a new website. With high expectations from customers and continued digital transformation, companies have to be extremely responsive to the customer experience while managing all of the data being generated. Every tap, refresh, URL click, or app launch generates a possible nugget of gold a company must understand, move, analyze, search and store. Applications constantly collect user experience data, usage data, and system data, which is used to understand how users interact with the app, track performance and stability issues, and improve the overall user experience. But this data collection doesn’t come without a cost.
Data Is Skyrocketing But Your Budget Isn’t

As digital transformation continues to accelerate, so is the amount of data created. Observability data is skyrocketing — companies are overwhelmed and under-resourced to handle the onslaught of data they’re receiving from their infrastructure, not only from a technical perspective, but also a budgetary one. Data is growing at about a 25% CAGR — in five years, you’re going to have about 2.5 times more data than you have today, but your budget isn’t going up 2.5 times. So if data is a commodity, and you pay to store and transport every byte, what should you do?
We have to ask ourselves, “Do we need to store all this data? Can we drop some of this data? Can we route this data to cheaper storage? Can we leave the data in place so that we can start to utilize existing paid-for resources to give us access to significantly greater volumes of data?” This is the fundamental problem that Cribl solves — we alleviate the tension between data growth, budgets, and resources.
Is Your Enterprise Ready for Increasing Security Needs?
Let’s say you’ve figured out how to meet customers’ high expectations and account for enormous increases in data. One problem might be under control, but now you have another: data security. Now, it’s time to make sure you’re able to perform detailed incident response investigations when (not if) they arise. The time will come when you need to ask questions of your data that you didn’t know you needed to ask previously. To do that, you’ll need access to massive amounts of ludicrously high-fidelity data that historically has not been aggregated and stored. It’s great to get broader views, but in some cases, you’ll have to be able to drill back down and see every individual connection or file that was opened.
As it happens, all of this high-fidelity data is completely worthless until it comes time for forensics, where it turns out to be invaluable. You have absolutely no need for such a high level of detail until the exact moment when you do need it — and you actually can’t do anything without it. So, if you’re investigating an individual user problem or an attacker’s lateral movement throughout your organization, you need to make sure you have access to that data, because you won’t be able to ask questions of data you don’t have.
How Cribl Stream and Cribl Edge Rise to The Occasion
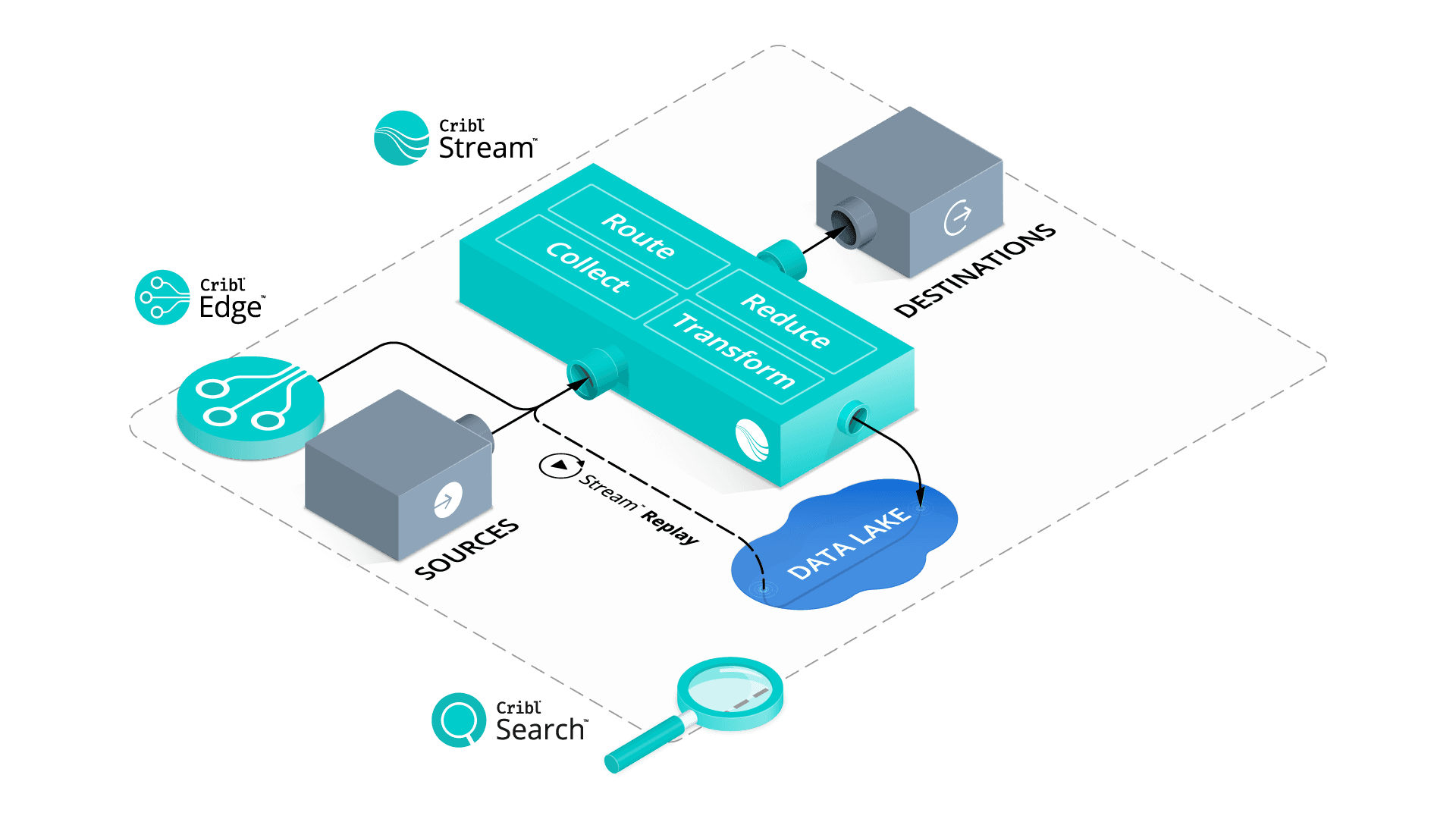
To solve these challenges (“my app experience better be good” and “I better be able to do a detailed incident response investigation”), you have to have all of your data stored somewhere. If you don’t have extra piles of money sitting off to the side ready to be spent on more data storage, then you need to do all of this inside the structure you already have in place.
The stone-cold truth is all of your data isn’t the same, so it shouldn’t be treated the same. Using Cribl’s products, you gain control over where your data is stored and streamed with full control over formats, dropped fields, and more. You can use Cribl Stream’s data filtering to boost your data’s signal, then increase the value of what you choose to keep by enriching it with context – automatically adding related data from external sources – all in real-time.
Security teams will be able to enrich their data with third-party sources like GeoIP and known threats databases before it even gets into your logging and SIEM platforms. By providing greater context to the data your organization is generating, you’ll enable a deeper, more actionable response of your security and observability data.
Additionally, you can also mask copies of events that will be shared with IT and operations teams and keep full-fidelity copies in low-cost object storage for compliance needs. If there is a security incident that needs to be investigated, you can easily replay events to reduce audit costs and time spent demonstrating compliance. Instead of a one-size-fits-all approach, you get choice and control over where and how your data is stored.
With our newly released agent, Cribl Edge, we’ve expanded our software all the way down to the endpoint. Cribl Edge enables you to route system metrics and logs to any destination with the processing happening directly at the edge, using the free capacity at the endpoint to process data previously done in the Stream. You can also teleport from centralized management into any endpoint to investigate running processes, containers, auto-discover log data, and easily egress any of that data to your favorite storage system. It’s an agent built for the cloud era. We’ve extended our simple UI that you’re already familiar with to the agent as well as providing a rich, graphical configuration on top of the ability to reduce, enrich, and route data to any destination before it ever leaves the system. Cribl Edge gives you a rich, centralized monitoring of its managed nodes. Edge includes pre-built dashboards that highlight the operating status of the nodes and offer deep visibility into the data flow.
With Cribl Stream and Cribl Edge, your organization is in control of your data — not your vendors, who address these challenges through the lens of what worked in the 2010s (and who are basically saying, “just keep doing the same shit you paid us for last time”). By integrating Cribl products into your existing infrastructure, your “software” enterprise can meet all of the challenges of the new digital world and be free to focus on providing exceptional customer experiences. When combined with Cribl Stream, the two products think locally but act globally. You end up with a centralized management of a massively distributed observability pipeline that provides you with access to more data than previously thought possible.
Next Up: Cribl Search

Earlier this year, we announced Cribl Search. Cribl Search will change how organizations think about data processing in observability and security. Search offers a new search-in-place approach with federated, centralized query, and decentralized data storage. Search allows you to put data in the best place for that data, offering the best advantages of existing data storage while also giving you the ability to query raw data at the edge, in the stream, or in your observability lake. Cribl Search will complement all of your existing investments in data technology while providing a familiar search experience that feels comfortable to users of existing investigation tools.
Cribl Search lets you use your data without moving it first. Instead, you can query it and leave out the most complex and expensive parts. Then, you can ship useful parts to another system for further analysis or long-term storage. With volumes of data increasing and distributed architectures proliferating, it becomes critical to search in place to find ALL useful data.
What’s Next for Cribl?
We look at problems from a customer’s first perspective. We offer customers the choice and control with observability data they didn’t know was possible before. We believe our products are needed by every enterprise in the world today, tomorrow, and in the coming years.
Are you ready to learn more about Cribl’s products? Spin up a free version of Stream and Edge in the cloud with sample data ready to go in our Sandbox. You’ll be glad you did.






