

AI agents are changing how teams build software, and ML/AI practitioners are the rule, not the exception. On the Cribl AI Research team, we use AI agents not just to write code, but to design, run, and evaluate end-to-end experiments aimed at improving our in-house models.
Earlier this year, we shipped cribl-privacy-1.0, the custom model we purpose-built for Cribl Guard to detect sensitive data in high-volume telemetry. This post walks through how an autonomous research agent continues to improve that model (and others) while we sleep.
The manual workflow
Let’s look at the manual workflow an engineer might use today when tasked with improving cribl-privacy-1.0:
Review aggregate metrics and example detections from the current production model (the baseline).
Develop a hypothesis for how to improve the model.
Make a code change designed to test that hypothesis.
Rebuild the dataset and retrain the model, which can take hours.
Compare the new results against the baseline.
Even with AI coding assistants in the loop, this process carries real friction. Engineers manage sessions to work around context window limits and account caps. They answer clarifying questions and approve tool calls. They context-switch into other projects while training jobs run in the background.
However, a closer look at each of these steps in isolation reveals that each can be reliably handled by a state-of-the-art (SOTA) model or even deterministically by a bespoke harness.
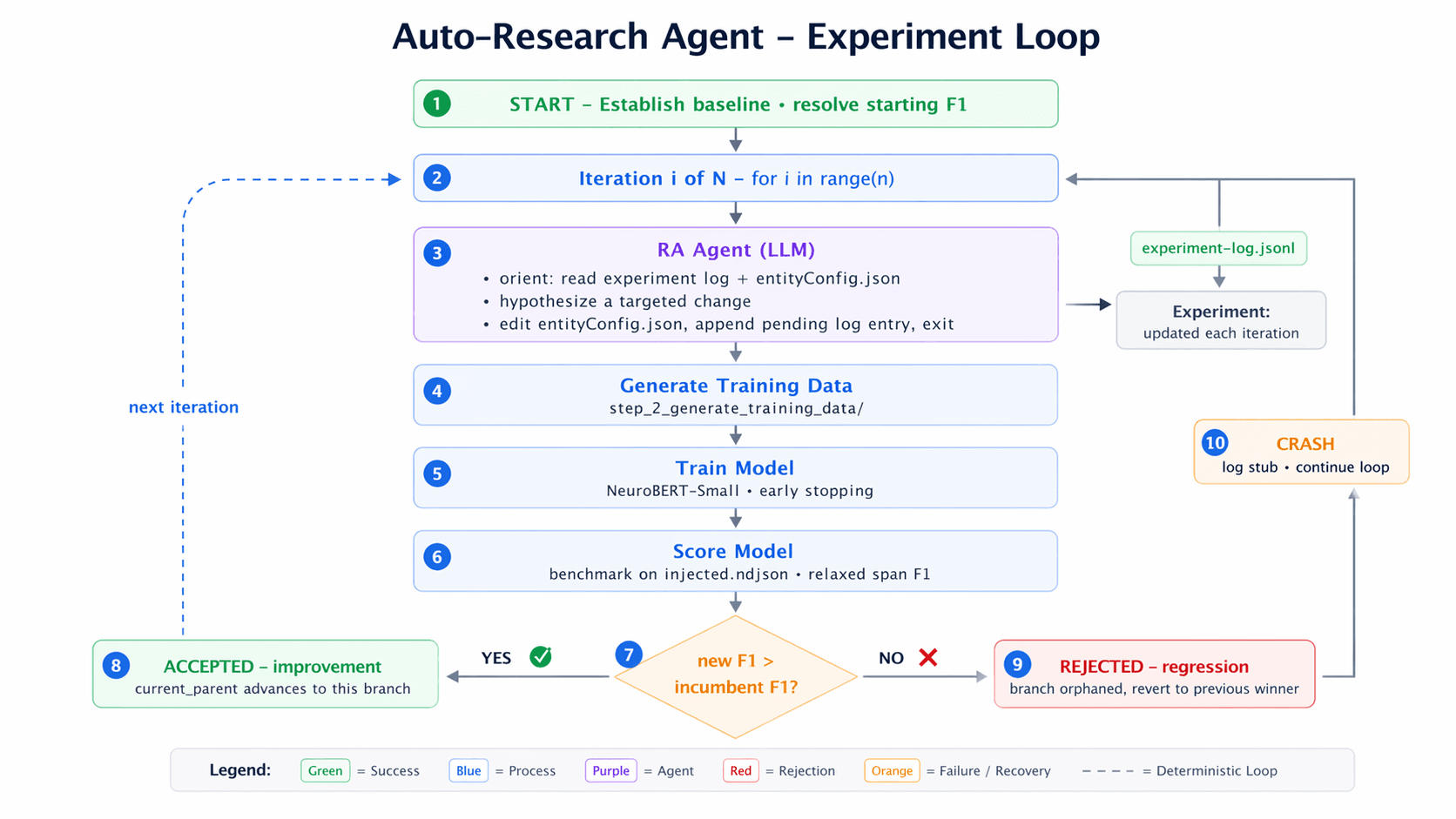
Designing the experiment loop
The experiment loop that we developed draws inspiration from projects like Karpathy's AutoResearch which gives an AI agent autonomy to iteratively edit the training code for an LLM and score the results.
Invoke the agent, which
reviews the results of prior experiments
develops a hypothesis that may improve the model
makes a code change to test it.
Rebuild and retrain the model.
Score the result.
Log the experiment outcome.
In short, anything that can be done deterministically is done deterministically. That lets the agent focus its attention where it matters: research, design, and analysis.
Results
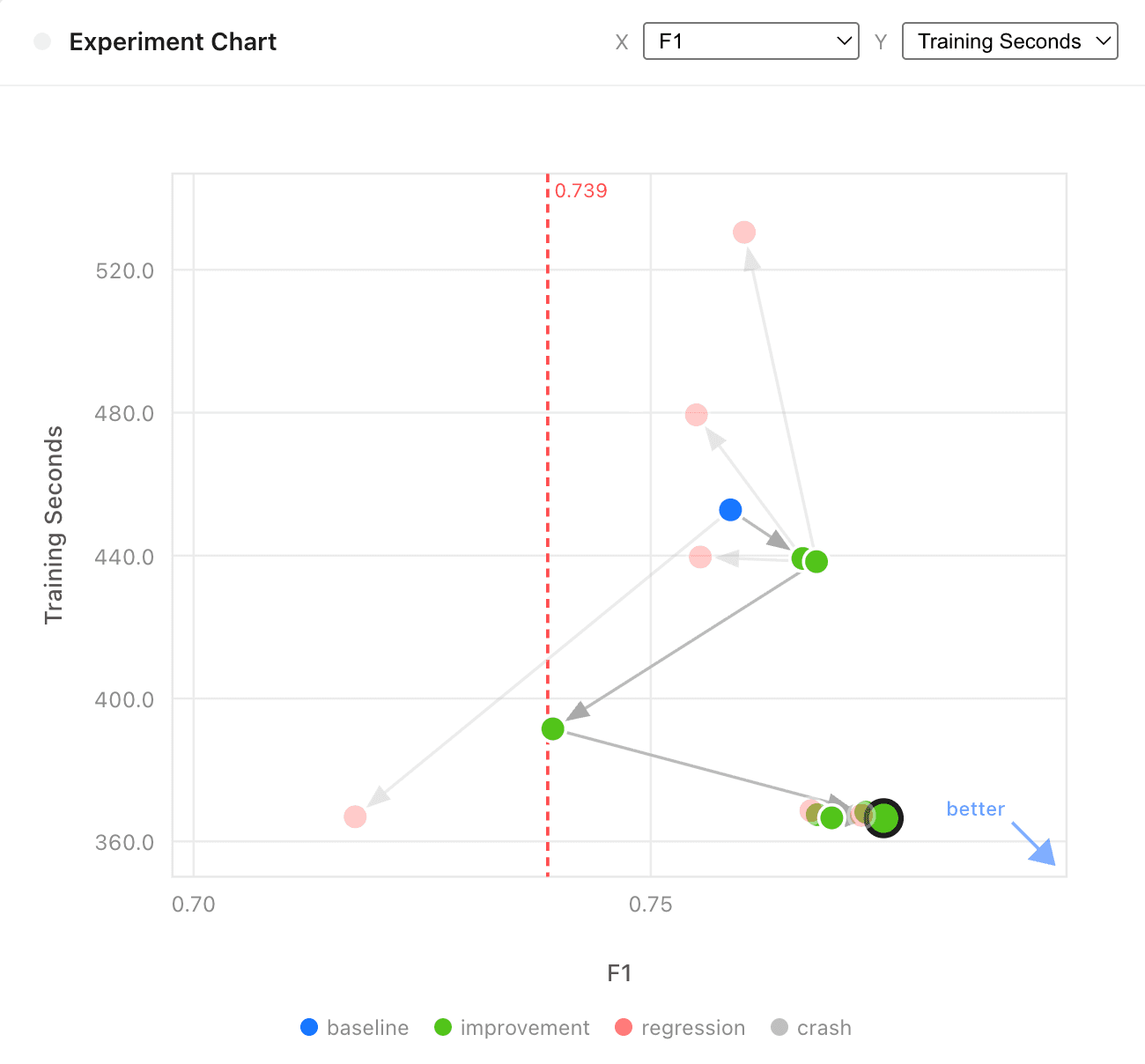
Experiment 1: Reduce model training time
North star metric: training seconds
Guardrail metric: F1
Result: 23% reduction in training time
Model training is the bottleneck of our research agent's experiment loop. Improvements here compound across every future experiment the agent runs.
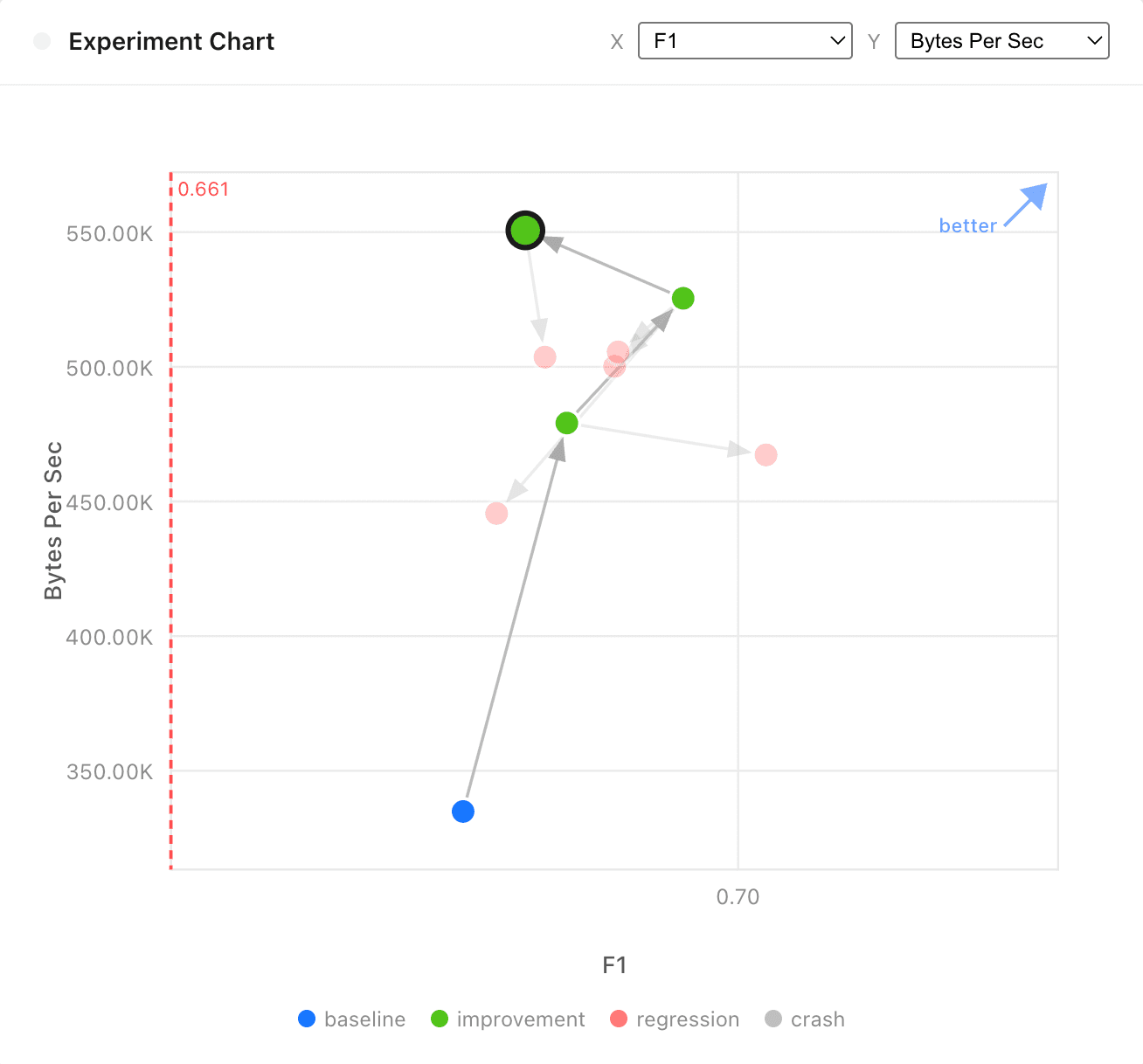
Experiment 2: Increase model throughput
North star metric: throughput (kb/s)
Guardrail metric: F1
Result: 60% increase in throughput
Throughput matters for cribl-privacy models because they run in resource-constrained environments — single-threaded, on CPU. Throughput gains directly expand which customers can run Cribl Guard on their highest-volume streams.
These experiments run on base models in environments deliberately scaled down to keep iteration cycles fast. Numbers in production will differ, but the gains translate to meaningful improvements at scale.
Conclusion
AutoResearch agents significantly amplify the leverage of the Cribl AI research team. Instead of burning time in the iterative design, execution, and analysis of experiments, our engineers are freed to focus on the higher-level, 0-to-1 tasks like launching the next model or project. This accelerated, agent-driven research loop directly translates into a superior user experience in Cribl Guard through smaller, faster, and stronger models. Even in customers’ high-volume, resource constrained environments, we can supply customers with advanced intelligence for sensitive data detection.
We're hiring
If problems like these sound interesting, we'd love to hear from you.







