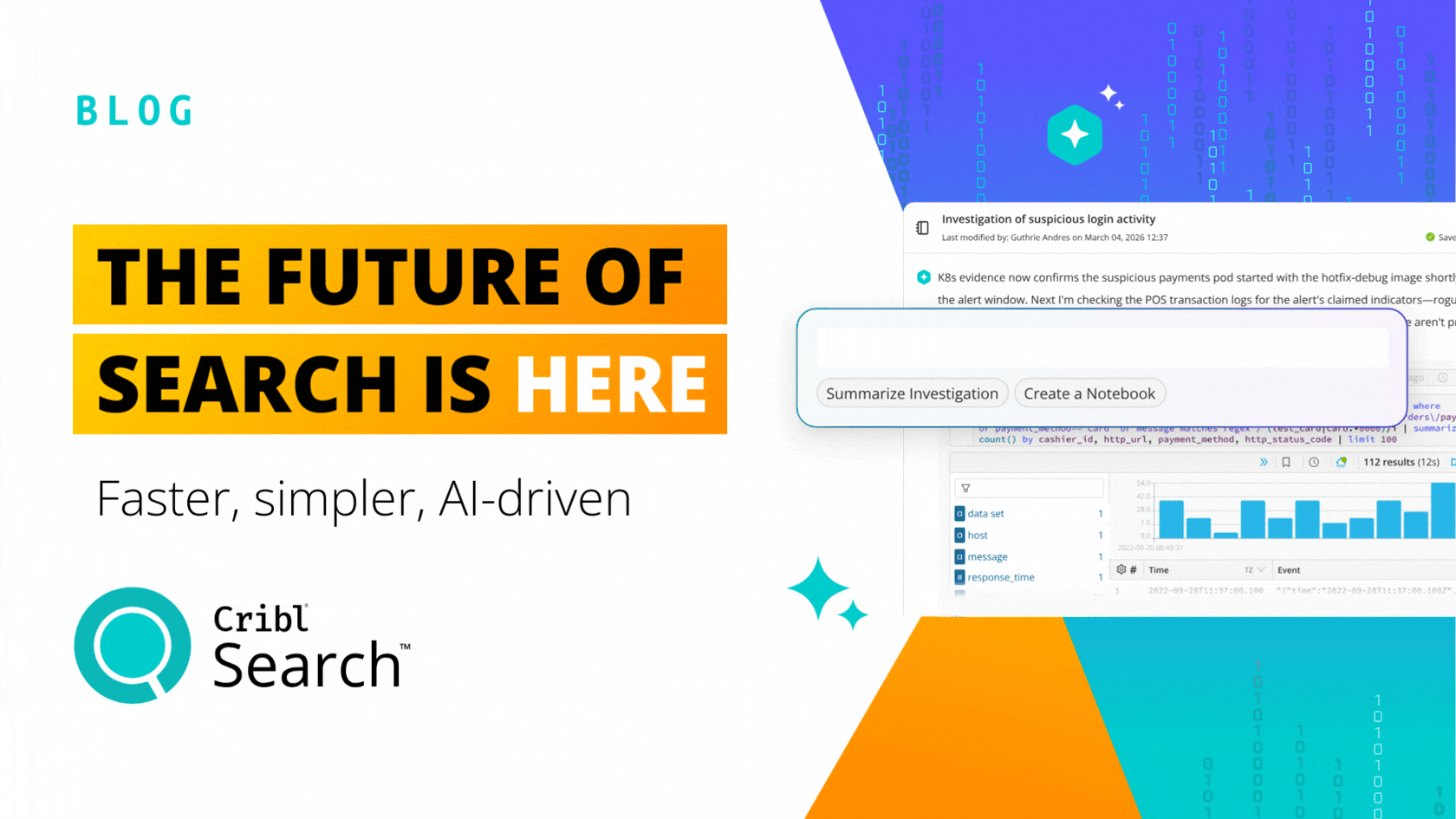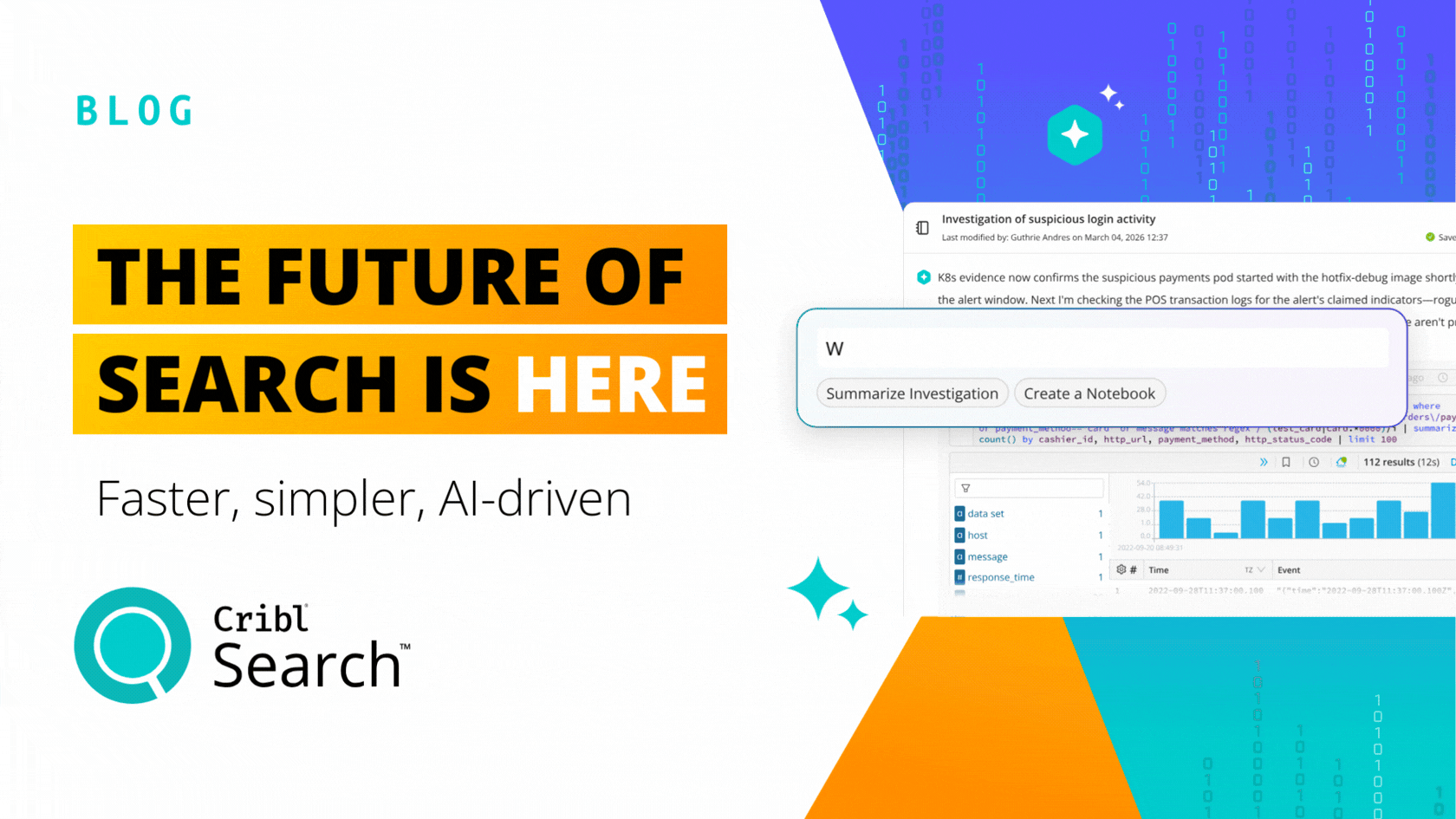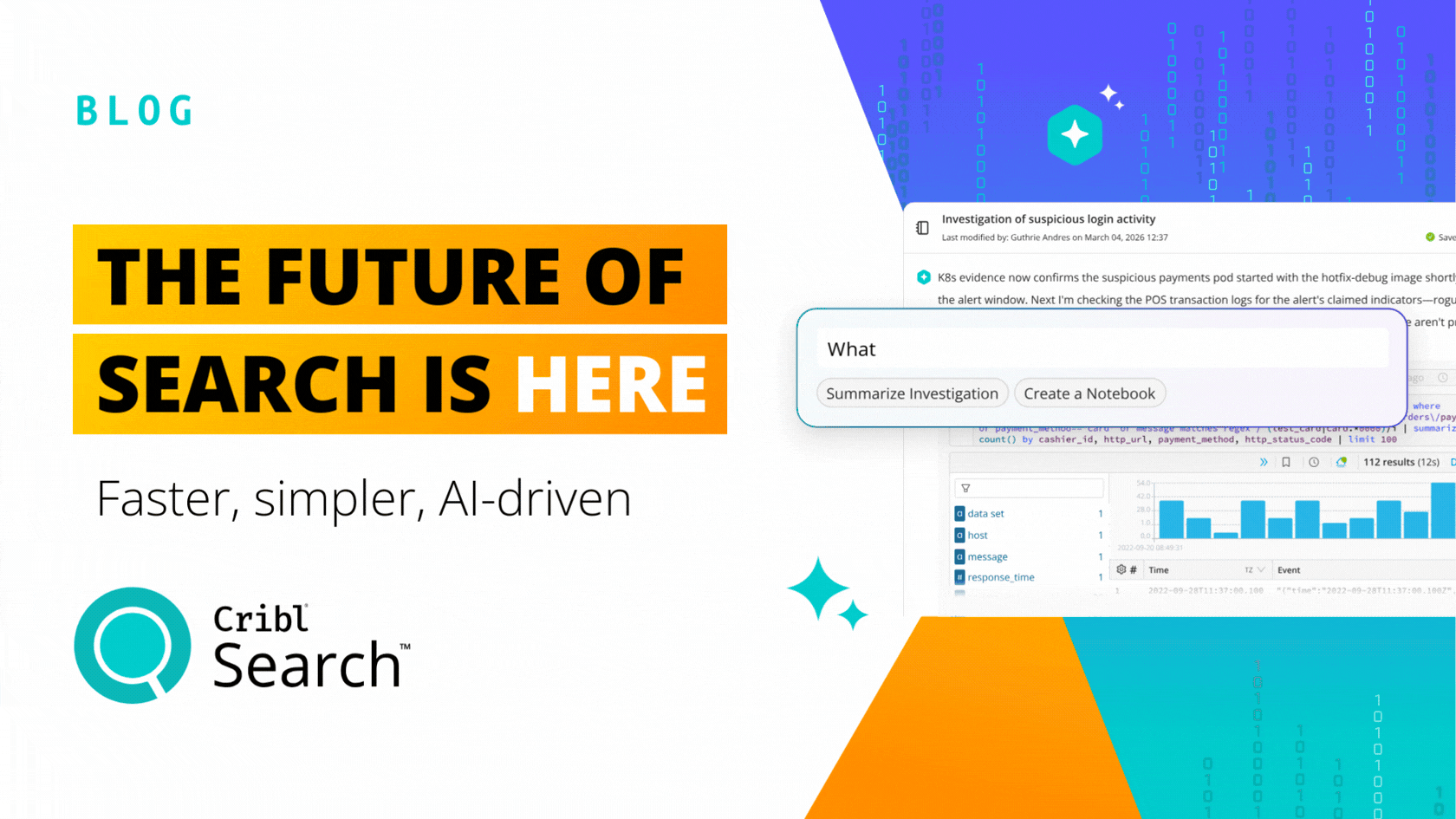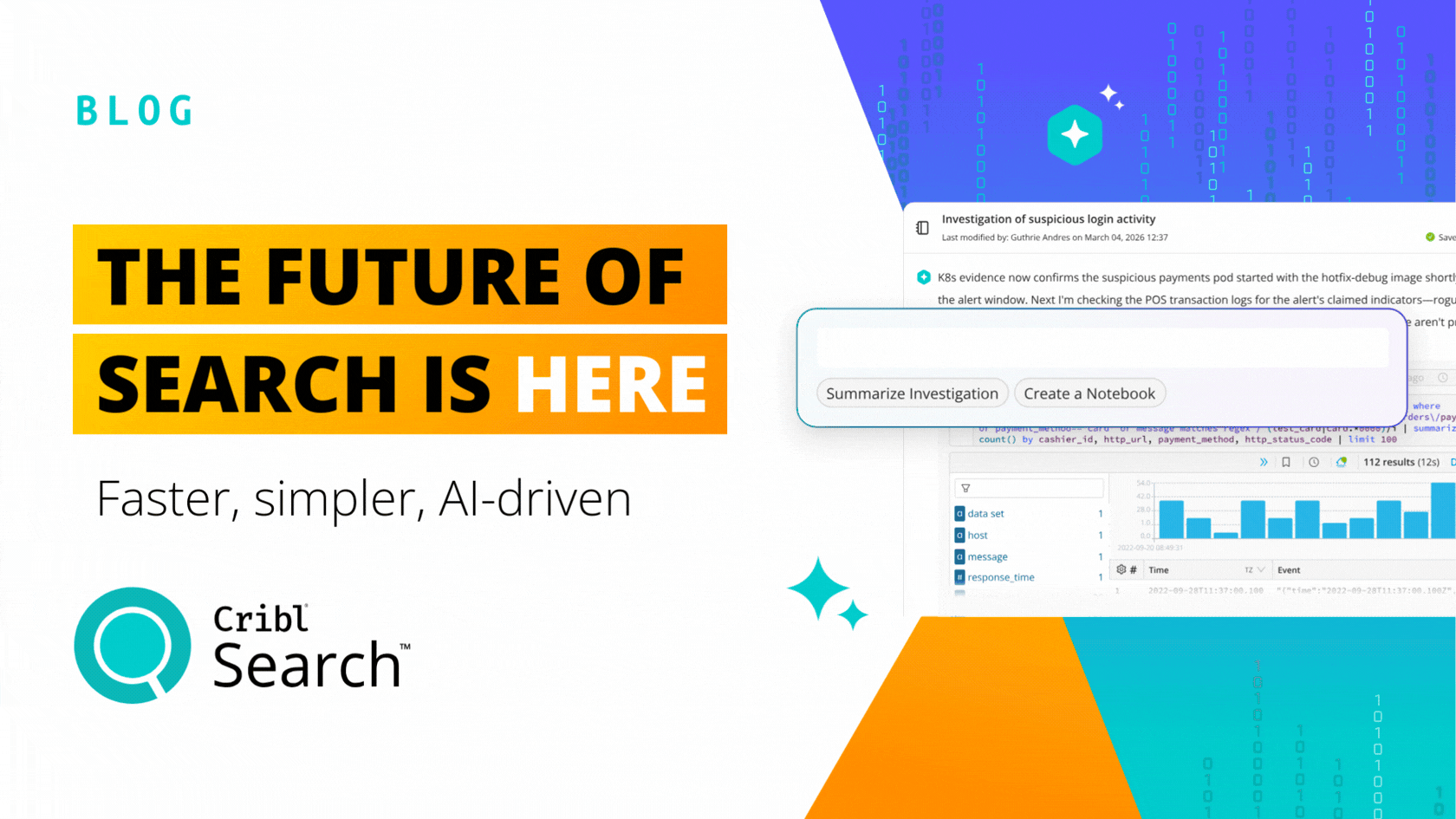
Cribl, a leader in open observability, today released Cribl Search, the first federated query engine focused on observability and security data. Search flips the observability market on its head, dispatching queries to where the data is already at rest. Cribl Search was engineered to let you search data-in-place, whether the data remains at the edge, in the stream, in the observability lake, at the endpoint, or even in existing search tools.
Prior to Cribl Search, traditional search tools required first collecting, centralizing all the data, and only then could it be analyzed for value, a resource and costly process. Customers told us time and time again their data is everywhere, and they needed a better way– a cost-effective way– to query the data where it is located. Most often data is distributed on hundreds or thousands of systems, too voluminous to collect, or just does not make sense cost-wise to move and centralize. Cribl Search performs “search-in-place” queries on any data, in any format, at any location — at the edge through Cribl Edge, in an organization’s observability lake, within existing systems, together vastly increasing the scope of analysis. All this without having to collect, route, and store the data first means you are able to query massively greater quantities of data and do it cost-effectively by leveraging existing compute capacity.
Last May when we first announced Cribl Search, we stressed Cribl’s first principles approach to solving observability challenges, essentially customer challenges. And although our engineering teams have hundreds of years of combined observability and Search experience, we chose to engage with a team of development partners who could help guide us on this journey to a new, better way to query the huge volumes of data being generated daily. Working with our development partners, we started with the goal of not only eliminating the cost and complexity of legacy search technologies but also making sure we are targeting the real-life day to day challenges of our customers.
Over a decade ago, the state-of-the-art model in Observability search was collect, route, store, and only then search. However, we have now reached the point where our ability to generate, collect, and store data has exceeded our ability to effectively analyze it; big data has just become too big to handle as we always have, and all indications are it will continue to grow. Worldwide, data is increasing at a 23% compound annual growth rate (CAGR), per IDC. In five years, organizations will be dealing with nearly three times the amount of data they have today being generated by a growing diversity of data sources, from datacenter to cloud to edge computing.
There is a consistent pain amongst nearly everyone we talk with: Data is everywhere. That data comes in many forms. Goes to many destinations for IT, SRE, DevOps, and Security teams, investigating a problem involves a lot of different types of data. The traditional three pillars of observability are metrics, logs, and traces. But that’s just the surface. There is also configuration data, wire data, deployment artifacts, source code, wikis and knowledge bases, etc. Much of this data simply won’t fit into the traditional data processing view of the world. It’s too big. It’s too hard to move. It doesn’t neatly fit into rows and columns. It changes rapidly.
Cribl Search is a bold new vision to address observability growing pains. With the introduction of Cribl Search, we will usher in a new era of convergence between observability and security operations by enabling queries on any data, in any format, at any location, furthering the company’s mission of unlocking the value of all observability data. For the first time, security and IT operations can keep up with the explosion of telemetry data and eliminate blind spots in data operations without slowing the productivity of their limited resources.
The observability industry required a better solution and Cribl Search delivered, by leveraging the latest in search-in-place technology that was simply infeasible 5 to 10 years ago. Cribl Search allows you to put or even keep data in the right place for that specific type of data, leverage the best, the most cost-effective advantages of existing data storage, or, query the raw data wherever it may exist in your data lake.
And finally, Search is designed to complement all of your existing investments in data technology, while providing a familiar search experience that feels comfortable to users of existing investigation tools. Search is cloud native. It’s elastically scalable, and the infrastructure is only running while queries are processed.
Today’s announcement signals our shift from the leading observability pipeline company into a full observability suite designed to complement a customer’s existing investments in observability infrastructure. Cribl Search, building on the foundation of Cribl Stream and Cribl Edge, solidifies the Cribl Suite offering, the trifecta of open observability.
For more information, please visit the Cribl Search webpage.