

Four months into this new gig at Cribl, I wish I could bottle up that “lightbulb” moment I get when walking people through how Stream can improve your organization’s data agility – helping you do more with your data, quickly, and with less engineering resources:
Preface
When I started interviewing at Cribl and digging into the various use cases for Stream, the whole data reduction thing made immediate sense to me in terms of value. Analysis systems can be expensive, and not all data is created equal. So if I can do a better job controlling what data is being sent to those systems, I can better manage spending, and extract more value from any headroom I can free up. Napkin math checks out.
What I hadn’t entirely grasped until I spent more time discussing value propositions with colleagues who’d arrived before me were some of the operational efficiencies Stream provides – and what those can mean to an enterprise. Then, as I collected my thoughts on the various use cases, I stumbled on the term “data agility,” which really brought it home. How can all the data we’re collecting matter unless you can actually achieve some outcome with it?
And bending data to your needs requires engineering time, which can cause you to have to make some difficult decisions as a finite resource. I imagine sometimes leading to conversations that sound much like a certain Capital One commercial:
What is data agility, and why should I care?
Let’s not belabor the point. It’s all about how quickly you can extract value from your data. But the journey to get there can be fraught with challenges. For example, how easy is it for you to fork existing data sources to a new destination, normalize the data, clean it up, and get it into whatever format is needed for that downstream system?
Now on to the use cases, which show how this can be achieved with Stream.
Integrating Acquisitions
Onboarding acquisitions is hard work, not to mention the risks that need to be mitigated to protect these large investments. Corp IT and security both need to figure out how to get organizations onboarded with a focus on minimizing any disruptions.
Before Stream, the approach might have included significant engineering, some downtime, maybe a bulk data migration, and a cutover event. It’s the kind of work that makes me glad I’m no longer on the ops side of the table. But, on the other hand, this kind of project is fraught with complexity.
How difficult is it to get the new org on whatever corp data requirements are? What format is the data in today, and where does it need to get to? What if the migration takes longer than the change window you have? What if there is an issue with the cutover?
Thankfully, once you insert Stream between whatever systems are generating your MELT data and your downstream systems of analysis/record/etc., it makes it extremely easy to implement a dual-write strategy where it’s business as usual for the acquired company. Still, they’re also aligned with corporate data formats and standard tooling.
The Approach
Let’s imagine a hypothetical scenario where the acquired company is currently on an on-premise Splunk instance, and the corporate standard is Splunk Cloud. Stream is agentless, which means we typically receive data from whatever you already have in place. In our case, we speak both S2S protocol and Splunk HEC.
That means we can first create a Stream route to act as a passthrough, with the on-premise instance (soon to be deprecated) as the destination. After that, we’ll update the existing forwarders to point to Stream, which will send everything onward in an unchanged state – business as usual.
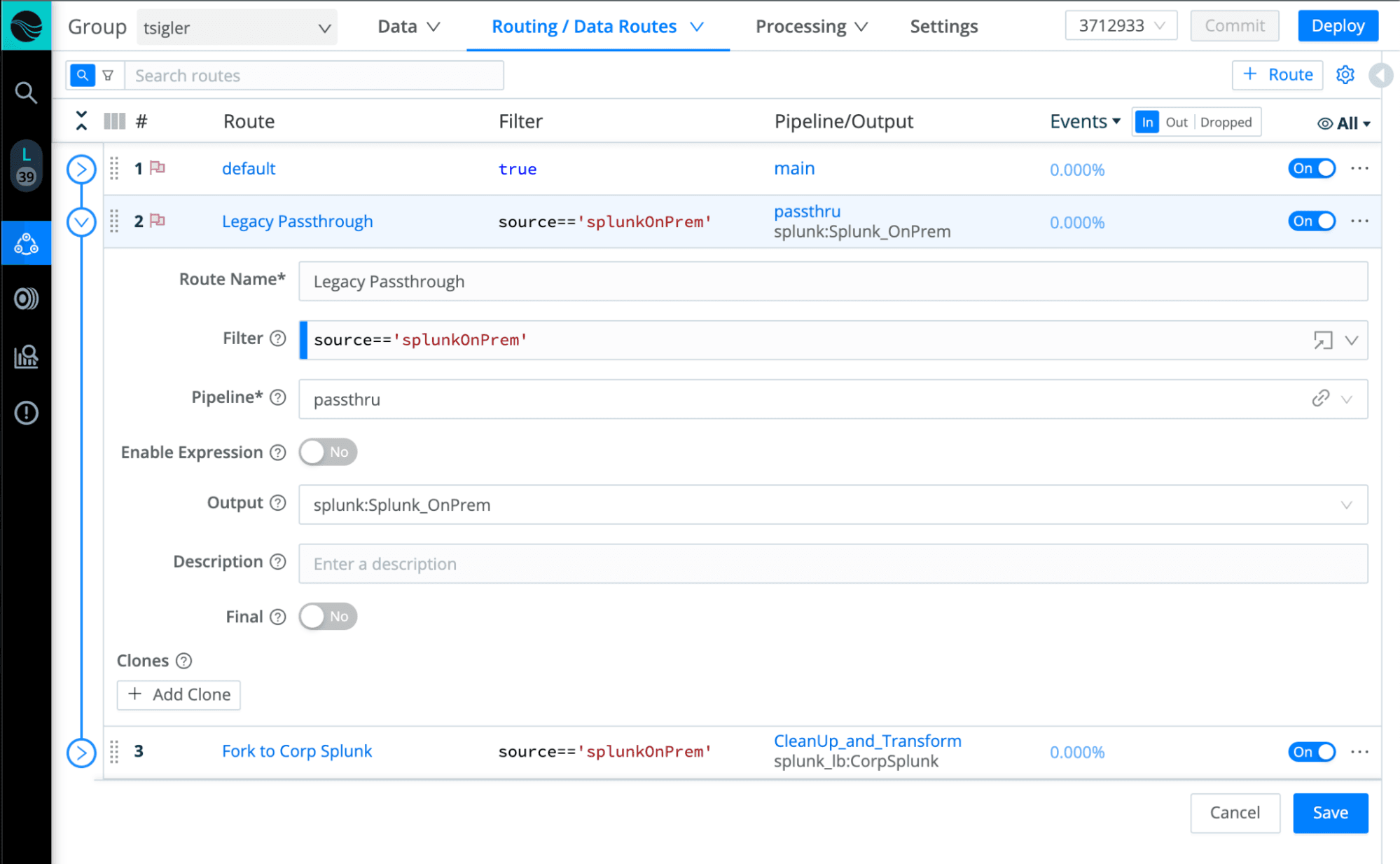
Once we’ve decoupled the source from the destination, we can now leverage Stream’s routing and pipelines to re-process the same data in a separate route, reshape/format it as needed, clean up/remove noise, and send it on to our corp cloud instance.
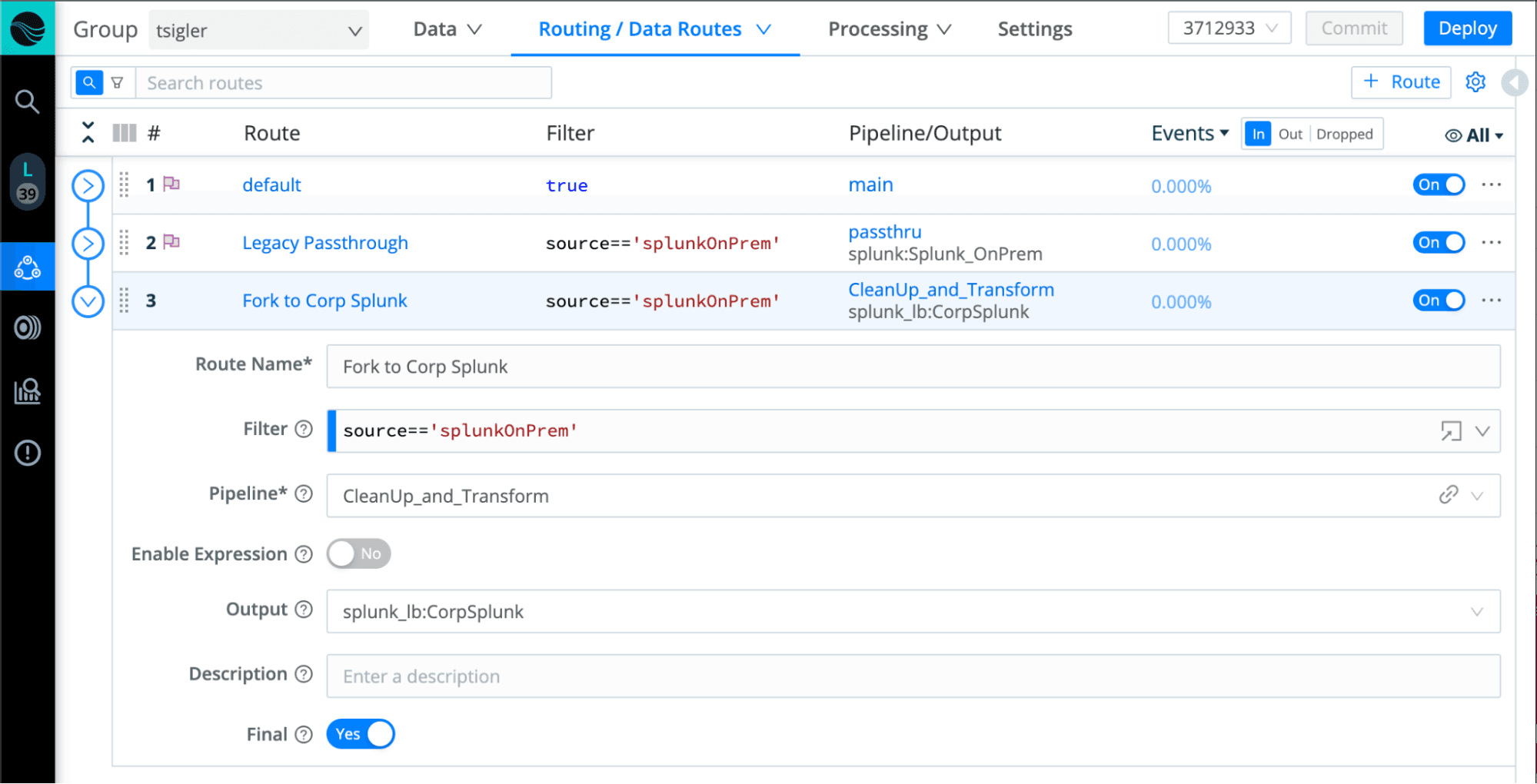
After some interval, you can shut down the deprecated system and the initial route. Or, if there is a more permanent solution in the works, this strategy can buy you the time to get that in place. By the way, this approach is identical to what you might do for straight cloud migrations to minimize the risk of a cutover event.
Security Threat Hunting
Becoming effective at security threat hunting is a journey, and Stream can help you move the needle by enriching data sets at ingest. This offloads processing, can improve search performance and enables better intel for your threat hunting.
The Approach
There are a few ways to go about enriching data within Stream. For example, you can use CSV lookup tables, leverage a MaxMind DB for GeoIP’s, or use Redis lookups for large dynamic data sets. Or maybe you can provide enrichment by simply using the data already in the log, as in our DNS example below.
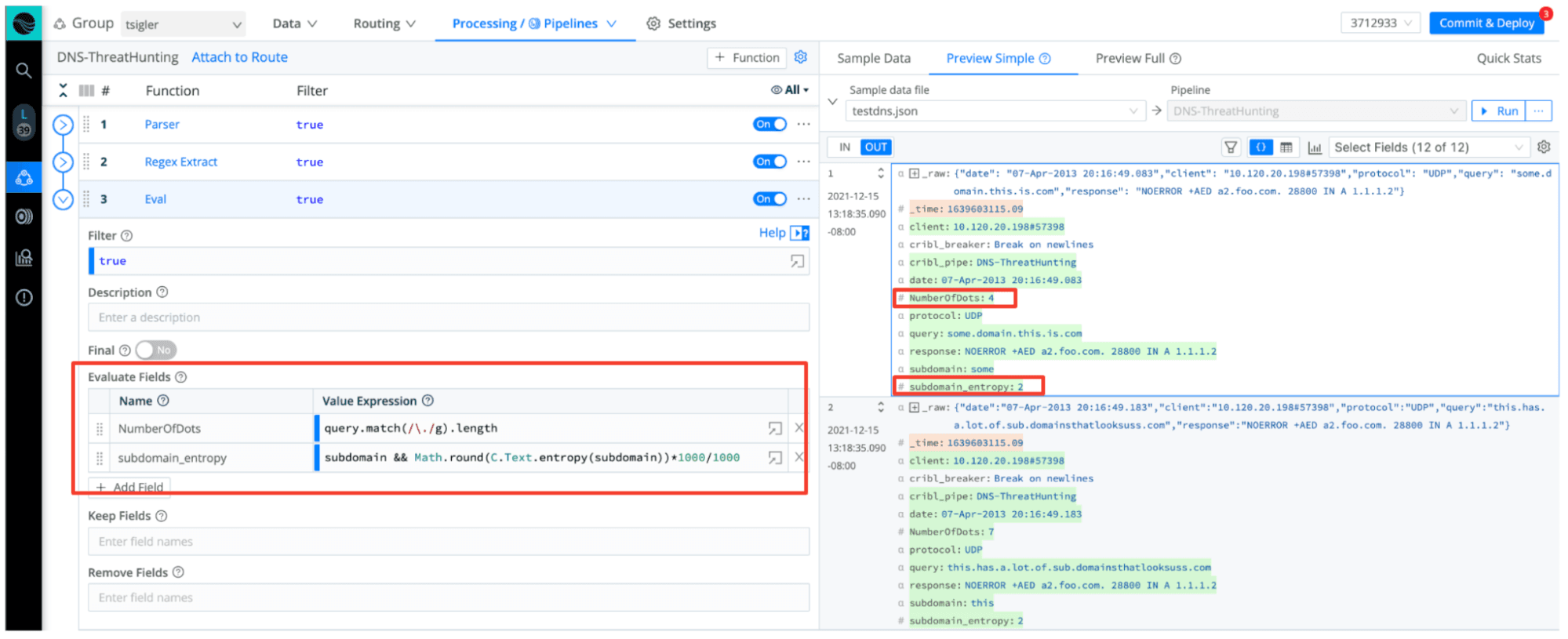
In the above screenshot, we’ve parsed out the domain in the DNS record, along with the subdomain. We use these two values to derive the complexity – which oftentimes can be a great indicator of nefarious activity. The two fields we’ve added via our Eval function, with some basic JavaScript, are the number of segments in the domain and the entropy of the subdomain. This information can enable better analysis in your downstream SIEM.
Managing Personally Identifiable Information (PII)
Effectively managing PII has huge implications for your organization’s inherent risk of data breaches. The key questions are: can you easily determine when and where PII is in play on an ongoing basis, and secondly, how quickly can you address it? Your success on both fronts can have implications – thankfully, Stream can help in both areas.
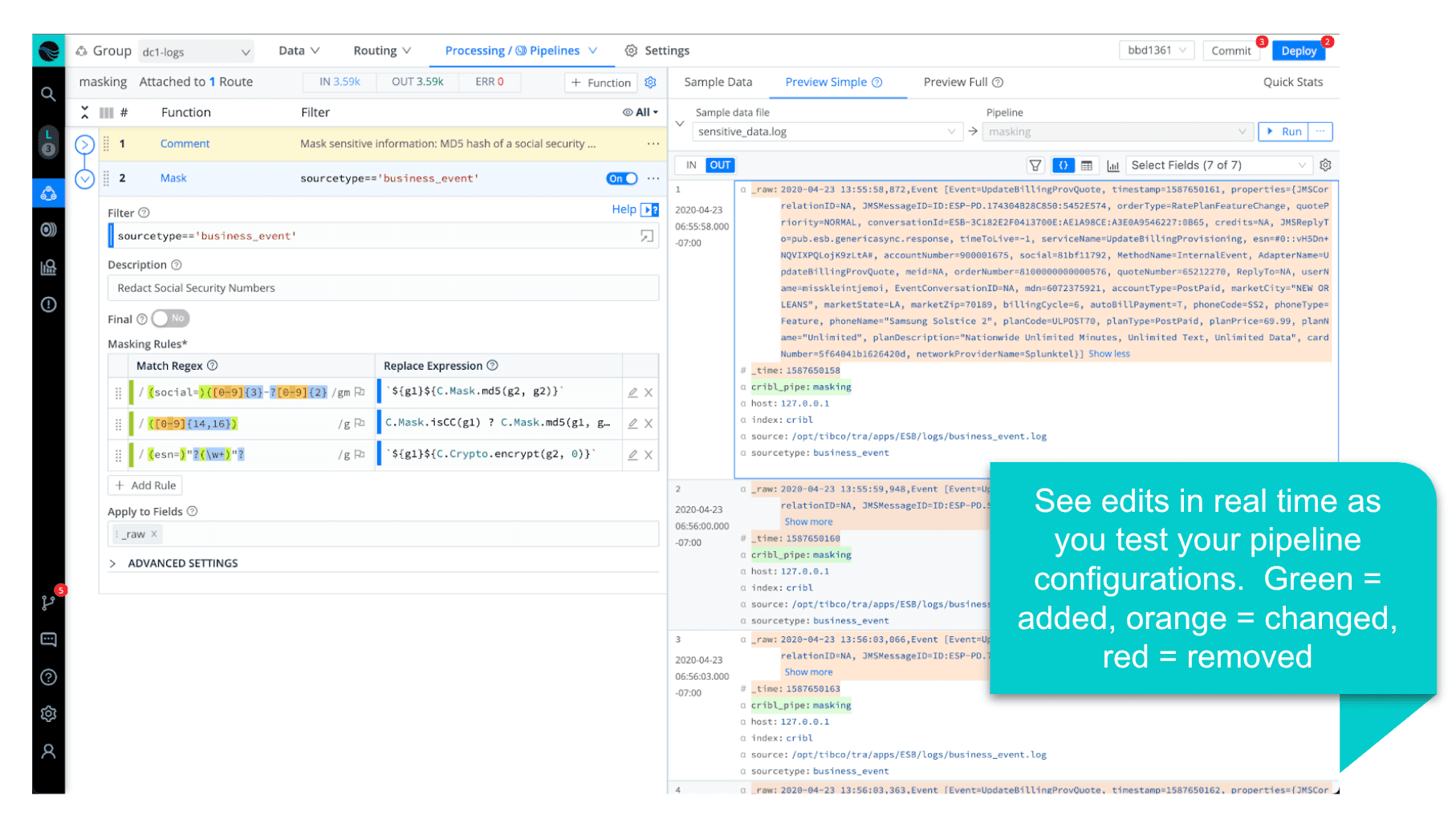
You can certainly go about detecting PII once the data makes its way into your analytics tool of choice. Still, the great thing about working with PII in Stream is our ability to centrally and dynamically manage the discovery and masking of sensitive data flowing through your various data pipelines.
The Approach
By creating a single pre-processing pipeline for all incoming sources, you can locate and mask all PII before sending it to your destinations. Then, if needed, you could optionally do some intelligent routing – where you fork an unmasked copy to a secure store and retain a masked version where PII isn’t required. Or maybe this is a means to identify a service unexpectedly leaking PII.
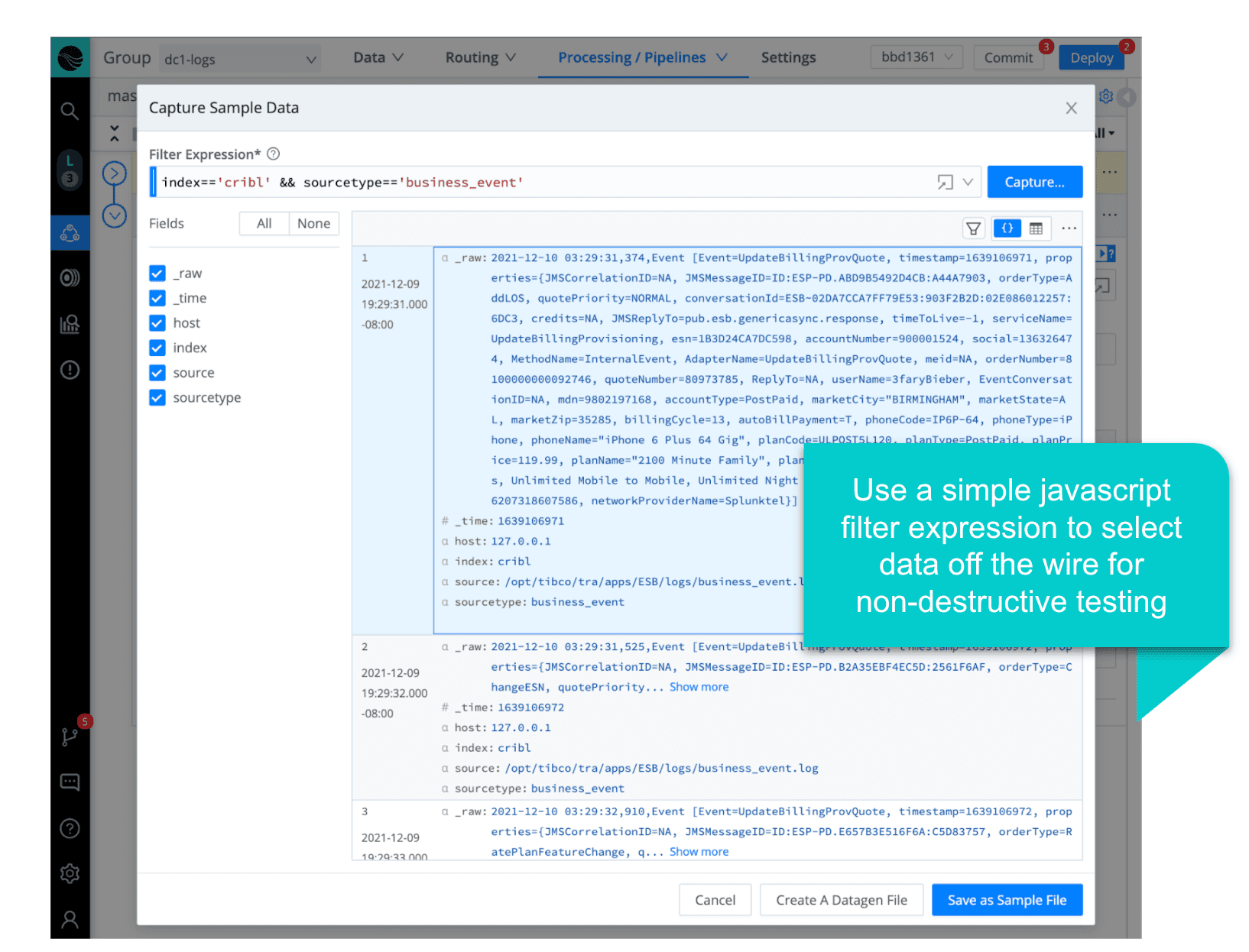
The pipeline creation experience is what truly sets Stream apart. Think about how you do this today, and compare that to Stream – where we can capture sample data directly off the wire, test changes with real-time feedback (before/after views of the sample data), and use a built-in regex editor to play with the pattern matching.
Wrap up
I hope this sheds some light on how you can improve your data agility by easily routing data to multiple locations, enriching data sets with basic JavaScript, and managing PII centrally and dynamically – all without the need for any significant engineering time.
If you’d like to explore these use cases or other ways these capabilities could help your organization, please don’t hesitate to drop a Q in our Community Slack. As always, feel free to try a Stream Sandbox or spin up a free Stream Cloud instance that supports up to 1TB a day of free ingest.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.







