

Can there really be too much of a good thing? Oh yeah!
For several years now, the American Southwest has been dealing with drought. But this wasn’t always the case. Not so long ago they had the opposite problem, too much water. With hundreds, thousands, 10s of thousands of upstream tributaries forwarding huge volumes of data, I mean water to the dam. There was so much water that the dam actually hit its limit and administrators ran out of options, there was just no more storage capacity left to be had. The excessive volumes exceeded initial designs, and the dam could no longer fulfill its regulatory responsibilities. It could no longer store additional volumes for future use: electricity generation, providing drinking water or regulating downstream flows. The only option left was to bypass the dam and dump it via the never-before-used spillway tunnels. And so they did.
Sound familiar? This is similar to what we are experiencing today, with systems of analysis being inundated by ever-increasing volumes of IT and Security data they were never designed to collect and retain. This data, flowing from the thousands of enterprise tributaries; the servers, the endpoints, the apps, and network components, all generating logs, traces, and metrics is just overwhelming. Just like the dam, those systems were never designed for the scale of today’s growing volume of data, currently at a 28% CAGR.
As a result, IT administrators are facing a similar dilemma, a deluge of data, just too much of a good thing to process effectively. With all the data being generated, the classic collection, retention, and analysis model within Systems of Analysis has reached the breaking point. Just like the dam, they were never designed to be the retention system for that much data. Forget the vendor marketing. It’s basic math. The infrastructure, the resources, and the budgets can no longer handle the flow, so something has to give. Turn off sources, but maybe miss critical data? Dump data to an ‘overflow’ channel but lose visibility to it? Return to the well for more budget; what’s the chance of success there? Is there another option you’re missing? Yes, it’s time to rethink the traditional data analysis approach of collecting, storing, and searching.
Ok, ok, I hear you already. You’ve spent years selecting, purchasing, and integrating your system tooling, and it does just what you need it to. The only issue is volume; you’re not ready to rip, replace, and start the learning curve again. Well, what if I said you could have your cake and eat it too? What if Cribl could offer you a way to maintain your existing tooling with no changes but optimize what data flows into your analysis systems? No overages, no volume bursts, no budget-busting and never lose visibility and access to your data, no matter how much it grows.
Unlike the dam administrators, network teams really can’t afford just to dump the data. They need a small percentage of it– time-sensitive data– routed to a real-time monitoring system, but the remaining volume must also be retained. Ideally, in low-cost storage, yet still visible and accessible if an event were to require its analysis. And, maybe they need a full-fidelity copy available for compliance reasons and recoverable without looking through racks of tape decks – sorry, dating myself.
Ok, enough with the pitch. Let’s talk about real-life, day-to-day challenges.
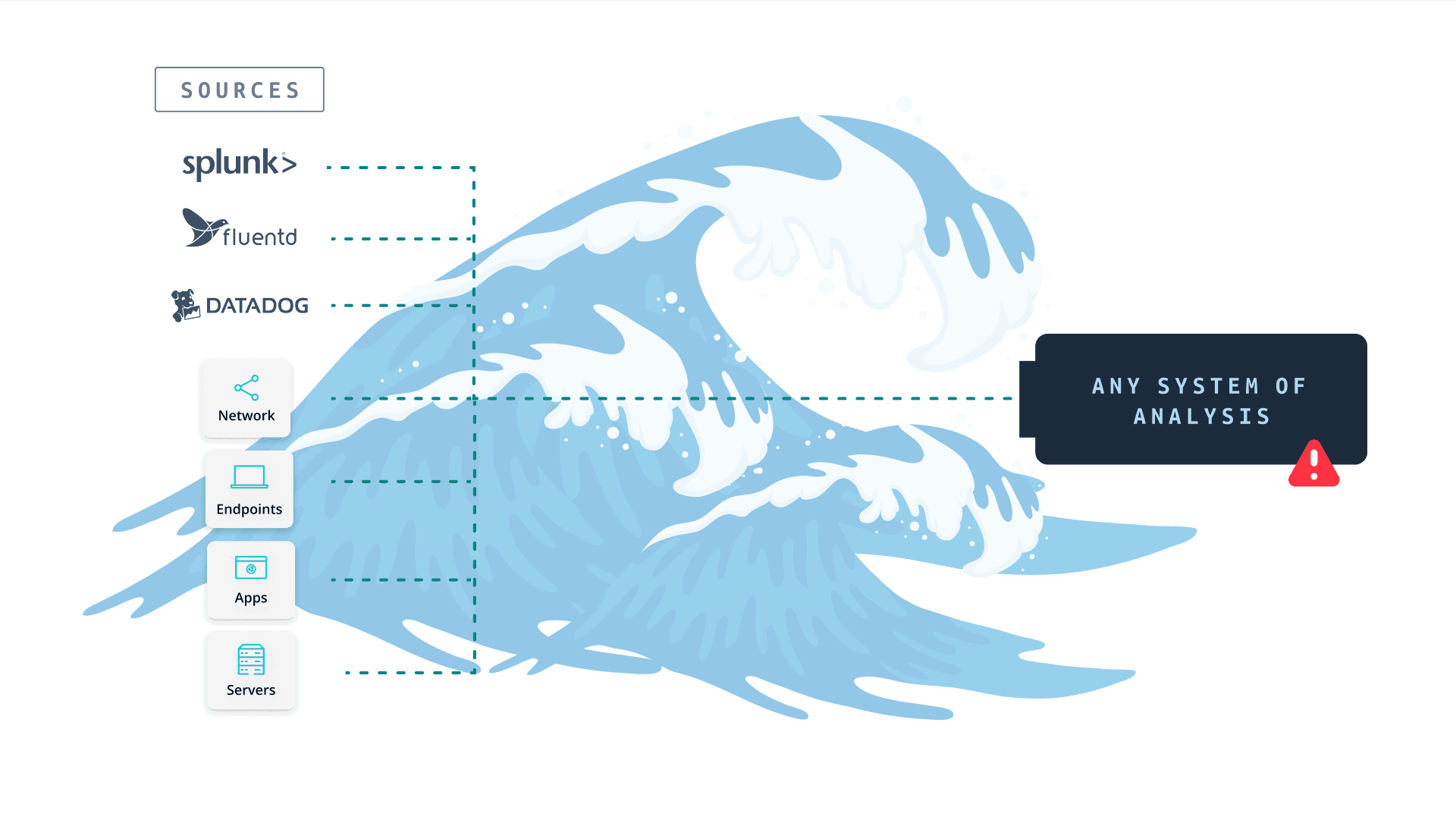
Today’s analysis systems are overwhelmed with data, the tributaries. They aren’t changing, and they aren’t going away. In fact, they will continue to grow in number and volume of data generated. This data then flows into one or more systems of analysis (SOA), where it is ingested, indexed, and then queried.
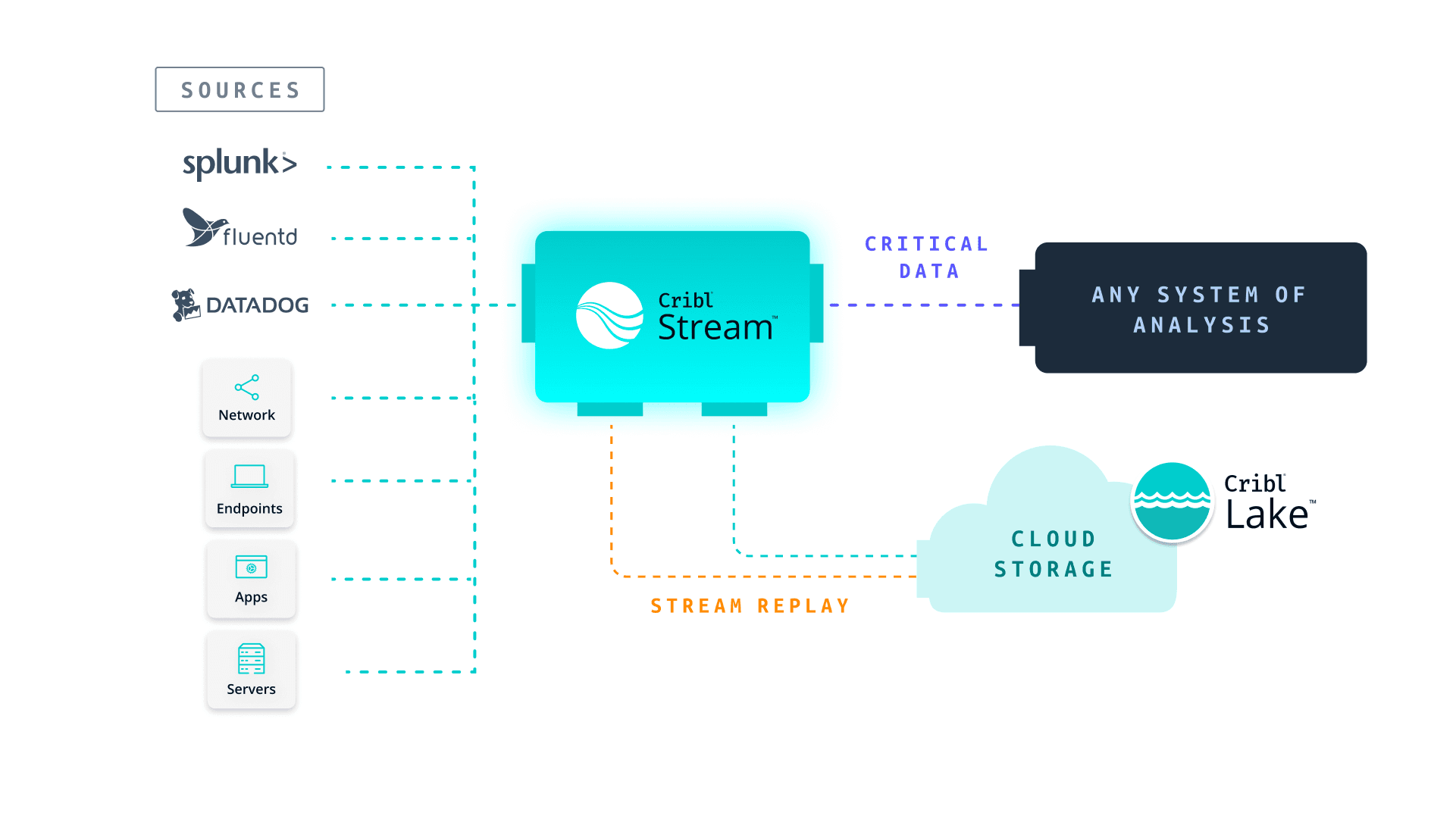
To address this deluge of data threatening to overwhelm storage or license limits, some administrators have front-ended their SOA with some form of data management pipeline, like Cribl Stream, to provide pre-ingest filtering, shaping, and routing of the data. Now only critical data goes to SOA while the remainder is offloaded to cloud storage, similar to how Glen Canyon Dam and Lake Powell control the flow to Hoover Dam. These datasets are then routed to your cloud storage of choice. I selfishly and shamelessly recommend Cribl Lake, but the choice is yours. Our lake, your lakes, or even a hybrid mixture of both, where we integrate your storage within the Cribl Lake infrastructure, abstracting all the management and configuration headaches of your AWS S3 buckets.
Stream’s replay functionality can then reach into that cloud storage and ‘replay’ the data back into the SOA if/when required. But this only gets administrators halfway. They need the ability to offload data volumes yet still maintain complete, real-time visibility of the data.
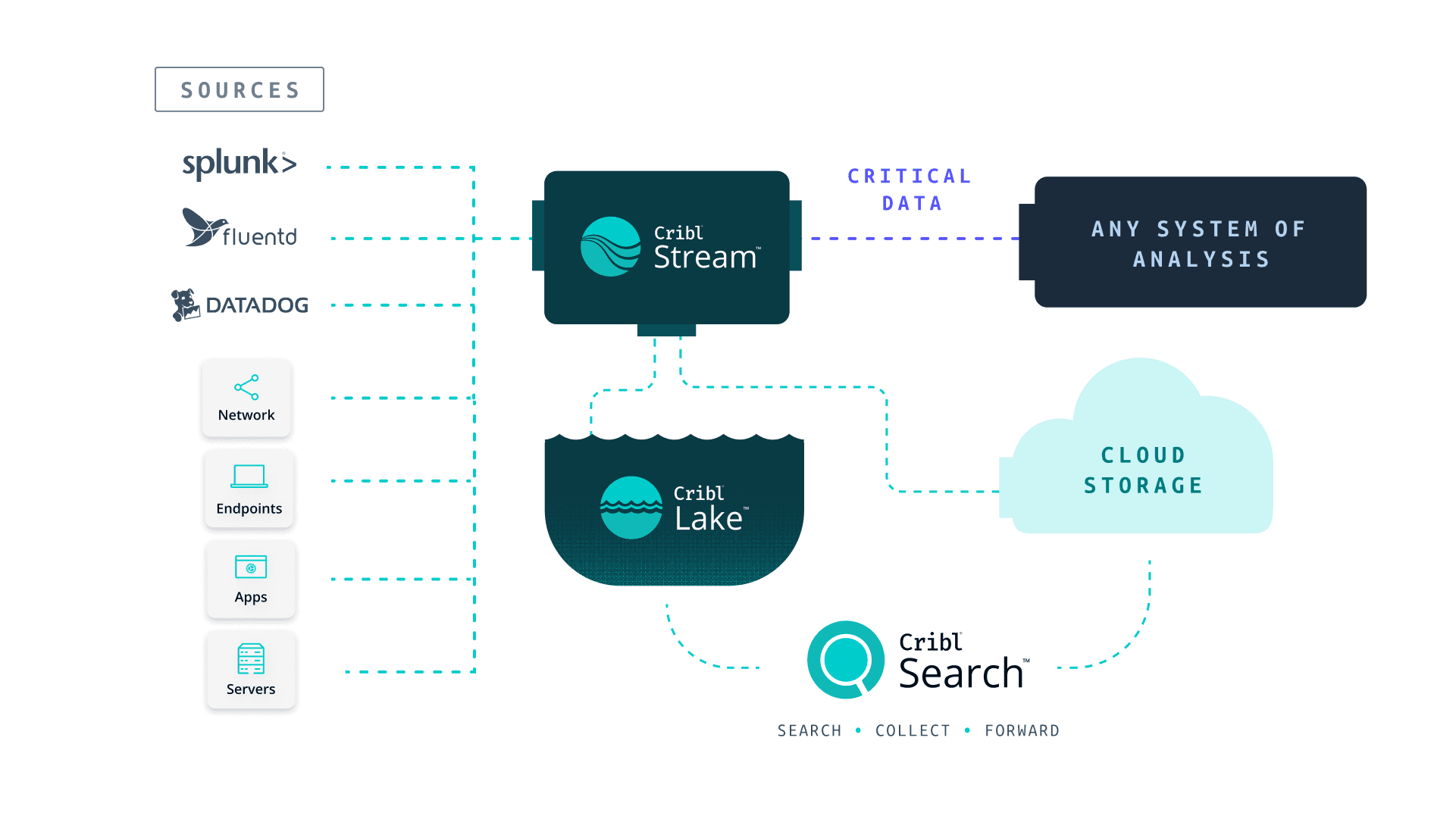
Now, there is even a better option: leverage the capabilities of Cribl Search. This provides the ability to search the data search-in-place, using a processing engine that accesses data from any source or storage medium in any format via a single, intuitive query interface. When a specific dataset needs to be reviewed, Search can surgically locate the required data, and simply route that data to your existing analysis system for deeper analysis.
With this approach, Cribl delivers a turnkey solution by integrating Cribl Stream, Edge, Search, and Lake to provide additional routing, shaping, searching, and storing IT and Security data.
A similar approach is also available to control data that age out of an SOA. Instead of allowing your SOA to move the data to an inaccessible frozen state and losing visibility, Cribl can route it to low-cost storage, where Cribl Search will still have full visibility and search capabilities.
What is Cribl Search?
Cribl Search is an innovative new approach to finding and accessing data regardless of where it is landed and in any format. As users embrace tiered data strategies and the reality of multiple analytics and security tools, Search provides a federated solution built to separate the query engine from a storage medium. This delivers a unified query interface in a familiar and ergonomic pipe-delimited language that reaches into existing object stores filled with messy, unstructured, or structured datasets and retrieves data without moving it or having to index it first. In addition, the same interface can also connect to APIs, databases, or existing tooling and join together results from all these disparate datasets in comprehensive dashboards, scheduled searches, and alerts.
The power of Cribl Search lies not only in what datasets it can reach but also in its ability to discover and forward critical data to your systems of analysis with surgical precision. Targeting specific datasets helps avoid the cost of expensive storage inside a system of analysis. Thus increasing users’ scope of analysis without needing to ship, ingest, and store the data first. Plus, providing relevant, valuable data that are only routed for further analysis if necessary.
What is Cribl Lake?
Cribl Lake is a turnkey (have you noticed we like to make things easy for you?) data lake solution that enables organizations to easily store, manage, enforce policy on, and access data. Cribl Lake leverages open formats — no pre-defined schema required, unifies security with rich access controls, and centralizes access to all IT and security data. Cribl handles the heavy lifting so data can easily be usable and valuable to the teams and tools that need it.
Conclusion
Data volumes are huge and growing, but budgets are not. Due to licensing costs, the percentage of data being analyzed will continue to drop, giving organizations only two options to address this: get a bigger budget or be smarter about how data is processed before ingesting into the analysis system. Leveraging Cribl Stream, Edge, Lake, and Search is a true game changer.
You can now effortlessly shape, route, store, and query your data, wherever it is. Where it was generated or where you store it, your lake or ours. Then, you have real-time visibility and access, allowing you to collect specific datasets and forward them to any of your systems for advanced analysis, audit, and compliance. It’s of tremendous value for anyone managing digital exhaust data at scale. By separating your system of retention from systems of analysis, you can optimize your budget in ways not previously possible. And, since the data is archived in the format of your choice, you’re free to use it however you’d like.
Want to know more about Cribl Search?
Check out the Search Sandbox
Create your own Cribl.Cloud Service- It takes 2 minutes and is FREE!
See how easy it is to use Cribl Search & Cribl Lake
Check out Cribl U, where training is always free






