

During our March Cribl User Group livestream, Cribl’s own Eugene Katz covered some of the updates we made to our documentation on Architectural Considerations for deploying Cribl Stream.
Topics included our guidelines for determining the ideal number of worker nodes, accounting for throughput variability, and preparing for system failure. The full video has more information on these and other things to consider when determining the right balance between cost and risk for your organization.
How Many Worker Nodes Should I Have?
When sizing your deployment, one of the first things to think about is keeping one worker available for maintenance purposes or in case another worker is down. Running at N-1 means there’s a backup available no matter what is happening with any particular machine or network.
Keeping that in mind, you can decide how many worker nodes are ideal for your particular setup. No matter which configuration you land on, remember that two virtual CPUs (vCPUs) per node are reserved by default for the API process and managing the system, as opposed to processing data.
You might be tempted to only have two worker nodes, with 30 worker processes each — but splitting up those worker processes over three or more worker nodes may actually give you more throughput per vCPU. Eugene walks us through the math here.

How to Account for Throughput Variability
The general guidance for throughput is to have one physical core with 400 GB per day IN+OUT, or 200 GB per day for vCPUs. With this as our guide, if you set up your vCPU to handle a daily throughput of 51 GB per day, 51 GB IN + 51 GB OUT, you would have a total of 102 GB. This design is under the 200 GB recommendation for a virtual core.
But throughput is highly variable, so there are a few additional things to consider. The first is that oftentimes, Cribl Stream is used to write some portion of your data IN to an object store for full fidelity and then reduce and send copies of that same data to another destination. Routing to multiple destinations alters the otherwise equal ratio of data IN:OUT, giving you a total throughput greater than 102 GB.
Another thing to consider is spikes of data IN. Even a small spike can increase average throughput enough to require another vCPU.
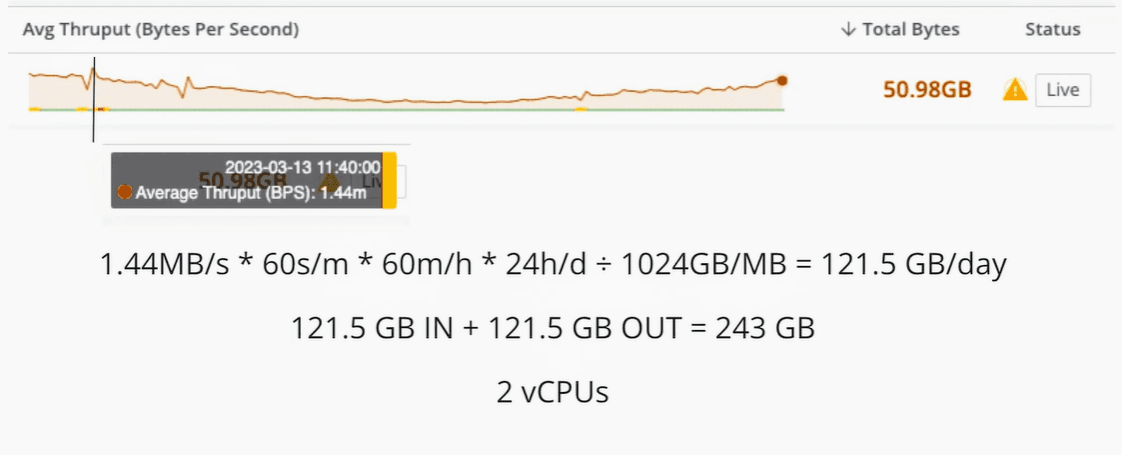
Sources like Office 365 pull data periodically, leaving you with large data spikes that can easily be 5x that amount.
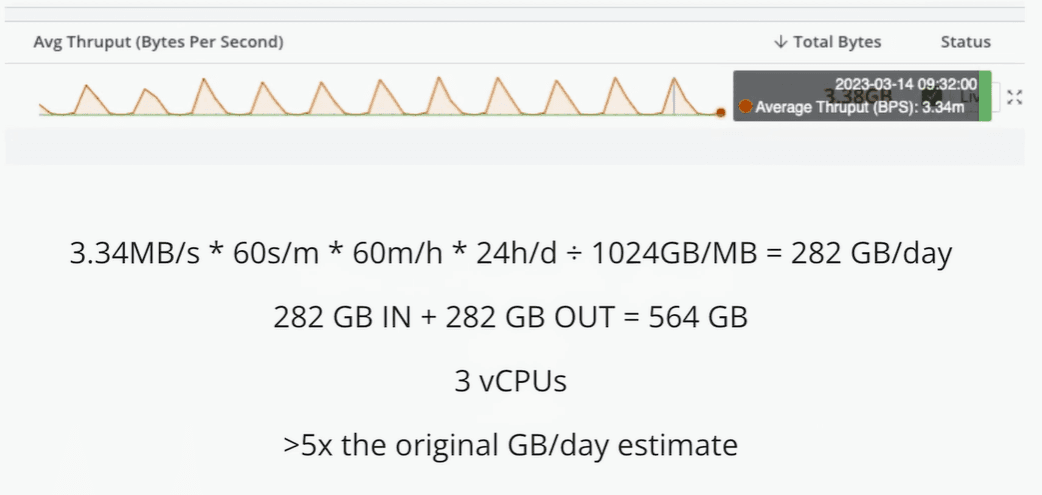
If everyone on your team has Windows events sitting on their laptops when they get to the office on Monday morning, your throughput graph will have a huge spike as soon as everyone logs on for the day.
Figuring out the actual behavior of any particular source is a challenge. You won’t have all these answers when planning your architecture, so you’ll have to make some best guesses. Once you start pulling the sources, some will start to average out — but keep one eye open for potential outliers.
Preparing for a System Failure
Because of all the variables that come with managing all of your observability data, including the risk of DDoS and other cybersecurity attacks, at some point you’ll probably end up with a spike in data that exceeds the capacity of your system.
You’ll have to know your organization’s risk tolerance and decide ahead of time how high of a spike you’re expected to be able to support. If you want to lower your risk, you’ll need to throw more money at a solution — in the form of additional hardware or separating your worker groups.
An all-in-one worker group might be sufficient for smaller organizations and under certain conditions. Still, there are a lot of situations when multiple workers may be worth the additional investment.
When to Consider Multiple Worker Groups
Keeping Workers close to their data to optimize syslog over UDP
Controlling egress costs by reducing and compressing data before it leaves your cloud provider’s region
Separating Push Sources versus Pull/Collector Sources
Geographical restrictions on data location, such as GDPR
Reducing or increasing the number of Workers connecting with a Source or Destination
Centralize certain processing that is dependent on external systems, such as Redis lookups
Reducing the frequency of Stream config deployments in cases where a deployment might disrupt data flow — such as triggering rebalancing among Kafka-based Sources
Be sure to check out the full livestream for more information on when to consider multiple groups, how to better prepare your architecture to handle both expected and unexpected spikes in data, and how to keep your data flowing as smoothly as possible.






