

Cribl Stream provides a robust HTTP REST collector, with many features and options. Still, there are endless combinations that vendors can provide in their API endpoints. Sometimes you may need to take more extreme measures to unlock data stashed behind the API entry point. No worries! Cribl also allows you to run a script to collect that data, and can even help you scale it. In this blog post, we’ll cover how I completed this task for a recent interaction using Qualys.
Step 1: Credentials
Set-up a test account in the API authentication system. Preferably make it read-only, and with access to only the resources you will be monitoring. We want to minimize the potential blast radius of compromised credentials.
Step 2: Plagiarism Is a Compliment
Find previous art, if available. In the case of Qualys, the client pointed me to an old perl script that does what we need — mostly. In testing it out, I noticed it was retrieving all host detections based on an optional time filter. With 10s of thousands of hosts, even a very short interval proved to be a huge task, taking quite a long time to run.
Step 3: Docs Docs Docs (And Phone-a-friend)
Check the vendor for API docs. For Qualys, I found some API docs, and a blog post that helped me get on the right track to optimizing.
And don’t forget about my new bestie, Chad Gippity. Be warned that the answers are not always perfectly accurate, but most times I get a good starting point. I believe Chad helped me shorten the dev cycle quite a bit.
“Write a python script that collects detections from the qualys api”Chad: Roger!
Step 4: Set Phase to Discover
The primary way we’re going to improve the API pull is by breaking up the list of targets. The best practices blog linked above says we should first request a list of target systems, then call for the detections list in batches of 5000 (ish). The Perl script doesn’t do that. By multithreading the requests, we can parallelize the heck out of this beauty.
And this is one of the fantastic features of the Cribl Collector sources. Multi-threading scripts were never this easy.
There are 2 phases possible in each collector: Discover what work needs to be done, and do the work. For Qualys, we want to get the list of host ids that recently got scanned, then make multiple independent requests for subsets of that list. Rather than one big request for all 25000 IDs, we’ll make 5 requests with 5000 each. Or 25 requests with 1000 each. The more worker processes in our worker group, the more threads we can fire up.
Step 5: Design
We now have an idea of what we’re going to do:
Get logged in
Request the (long) list of targets in a timeframe
Break the list into smaller chunks and print it on
stdout, 1 chunk per lineGet the detections for each batch
Print the detections to stdout
Step 6: Dev and Test
Well, this part may not be so exciting. I rolled up my sleeves and got to work on authenticating, requesting the list of hosts, and printing out the list in chunks of 1000. Each line of output had 1000 entries separated by spaces. Then I added a separate mode to the script: If it’s called with the list of ids, run the detection piece.
By checking for the $CRIBL_COLLECT_ARG environment variable I can determine if we’re in Discover mode (the variable doesn’t exist), or Collect mode (it’s there). I also added a few more environment variables: time, max size of threads, username, and password.
I’m no Pythonic expert, so it took me a few hours to sort it all out. Eventually, I could run the script in list mode and have it output a segmented list. Then I could take a sample from that list and run in detect mode to get the detections for that sample list. I used the Python requests module, so that will need to be available on each worker node. So far all the testing was done on the command line.
Step 7: Deploy in Cribl
We’ve got a working script. We’ve validated its 2 run modes, Discover and Collect. Let’s get it into service.
Go into the Leader and make a new Scripted Collector:

And the settings:
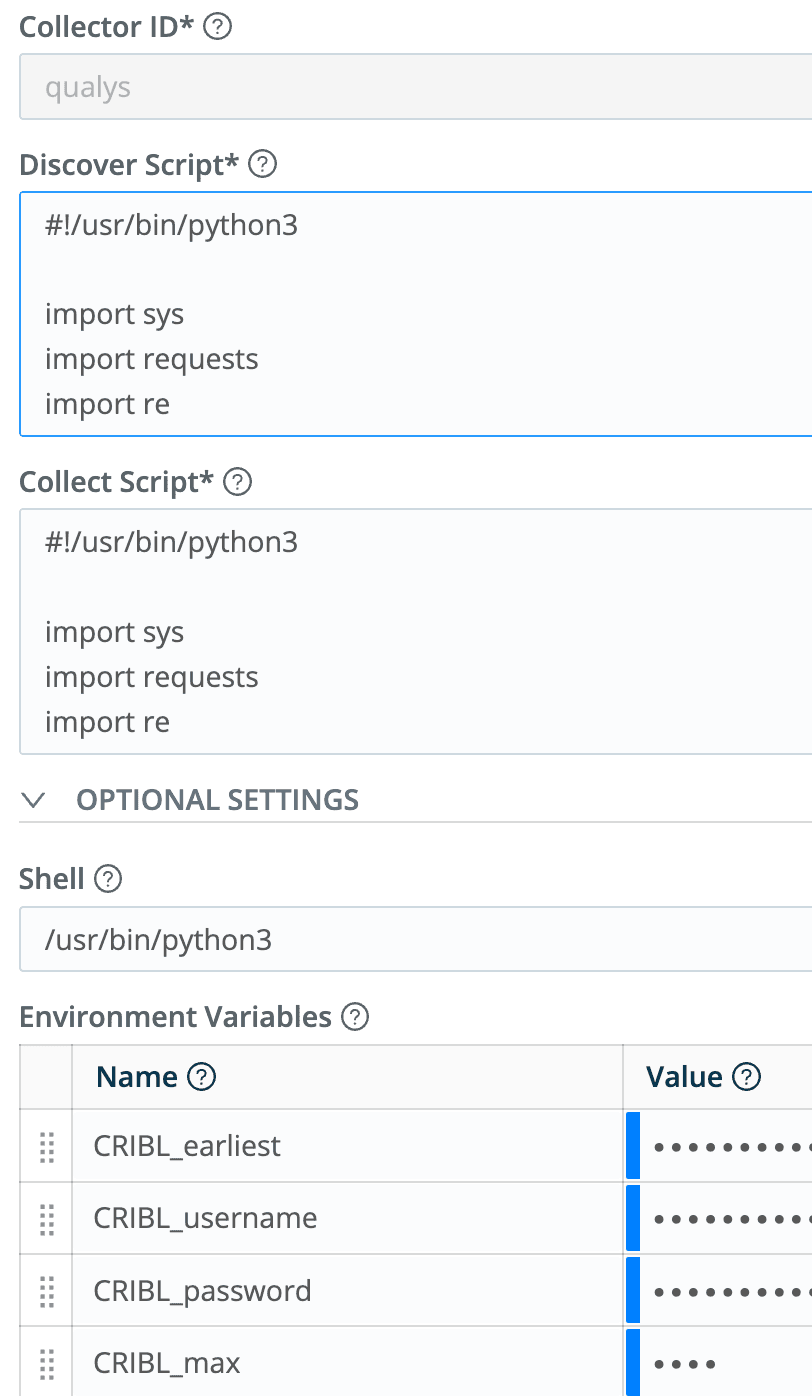
The Discover and Collect Script entries are identical copies of the entire python script, and the value of the CRIBL_earliest environment variable is:
C.Time.strftime(Date.now()/1000 - 300,"%Y-%m-%dT%H:%M:00")Meaning, 5 minutes ago, in the format Qualys expects.
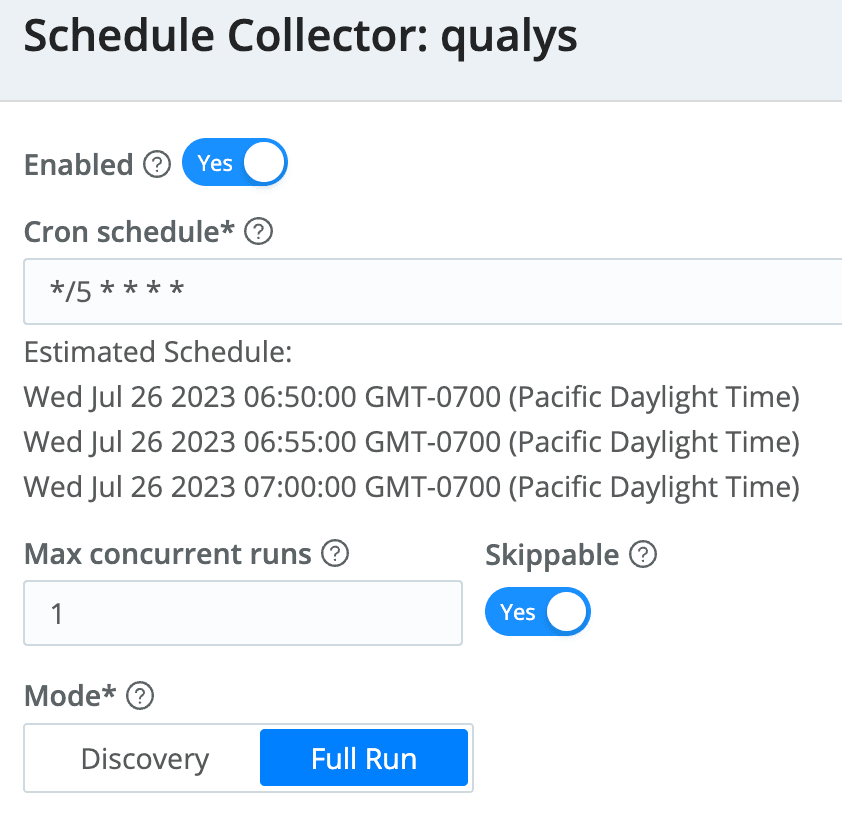
Finally, I scheduled it to run every 5 minutes:
Step 8: Wrap It Up
Using samples captured from test runs, I created the Event Breaker to unroll the events into manageable sizes, and a pipeline to transform XML into JSON. You can see the final product in the Cribl Dispensary.
Conclusion
Cribl’s built-in sources are flexible, but sometimes there are edge cases that just don’t fit. By offering features like Scripted Collectors, HTTP, raw TCP, and raw UDP, Cribl gives you the flexibility to get almost any data source ingested into your event pipeline. What have you done “outside of the box” with Cribl? Join us in our Slack community and share! Ready to get started? Head over to Cribl.Cloud to create an account and get 1 TB/day for free!






