
Normally I prefer to write a wittier headline for a release announcement, especially for a release this important. Three things are holding me back, however: a) I really want you to know we support the Universal Forwarder and Syslog, b) length of headline, c) it’s April Fucking 1st, and it’s possible this is so cool people will think we’re joking anyways.
Since we launched Cribl 6 months ago, we’ve known moving from supporting already structured events, like is sent from a Splunk Heavyweight Forwarder or a Elastic Beats agent, was just a matter of time. That time is six months as it turns out. But, we didn’t want to simply copy the ways of the past! We wanted to bring a fresh perspective and accomplish a goal which sounds simple but is difficult to accomplish: make getting data into log systems as easy as possible.

What makes supporting the Universal Forwarder and Syslog different than what we’ve been shipping the last 6 months is the ability to take a stream of bytes, break it up into events, and extract a timestamp. In Cribl, we pair these actions together, paired with a filter expression, that gives you supreme flexibility for identifying data which should be matched, including matching the content of the events themselves. In fact, we ship example content for AWS, Apache, Cisco, Palo Alto, and Bro logs which will break up events properly and extract their timestamps based on finding signatures of those log lines in the raw byte streams.
Supporting the Universal Forwarders also adds a really nice side effect: we can now deploy on Splunk’s indexing tier again. In Cribl 1.0, we discovered a problem when deploying on Splunk’s indexing tier that was difficult to work around. By taking over the parsing workload, once again its safe for us to deploy on indexers. For customers where hardware resources are limited, this can really speed time to deployment.
In addition to support for Splunk’s Universal Forwarder and Syslog, there’s also some other great new features: support for Confluent’s Schema Registry and Avro schemas in our Kafka Input and Output, support for Azure Blob Storage and Event Hub, support for writing CEF format events, and a new Dynamic Sampling function which controls sample rate based on data volume.
Cribl LogStream 1.5 is available for download today!
Event Breaking & Timestamp Extraction
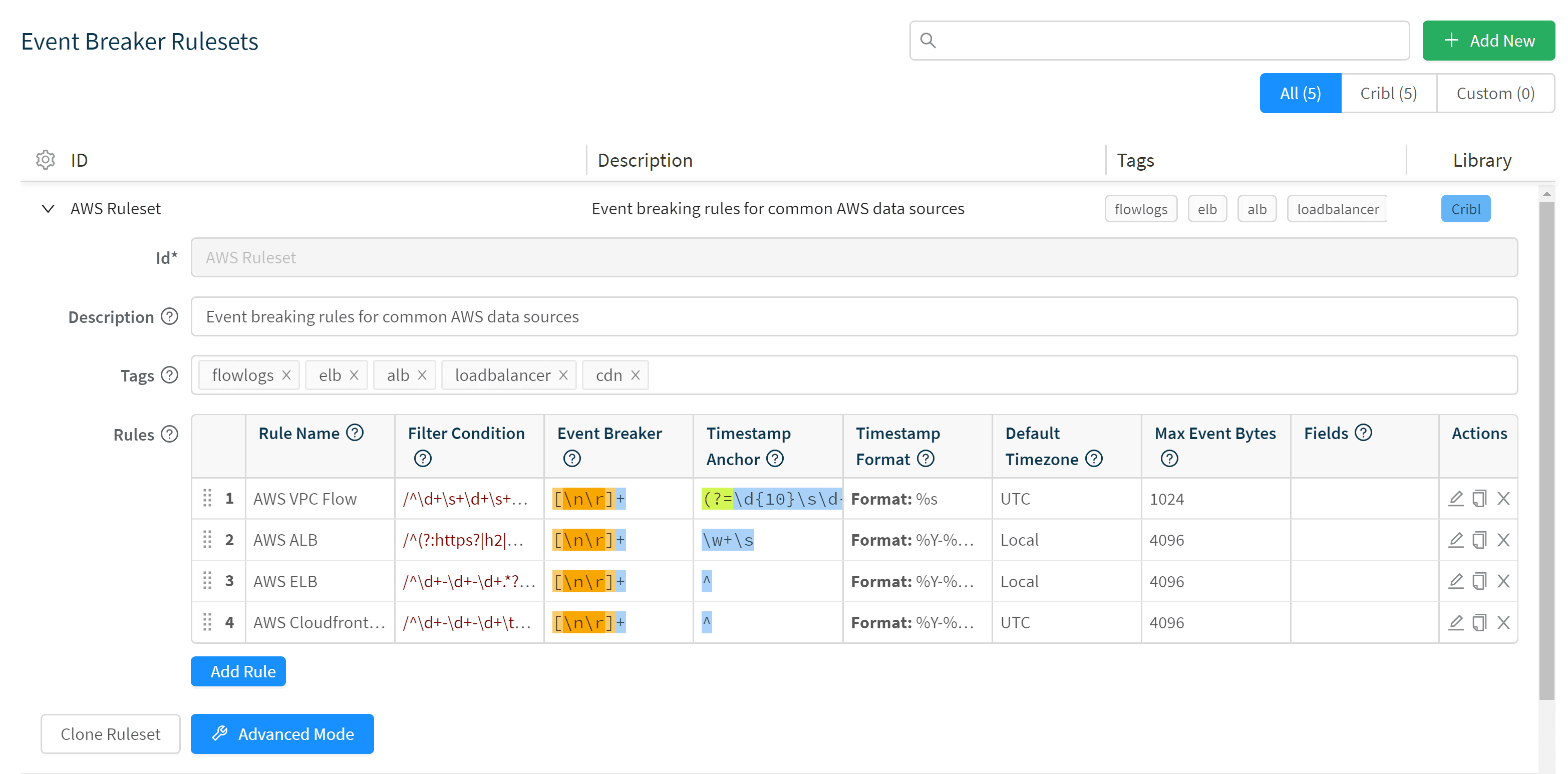
The first step in dealing with byte streams is to take a chunk of bytes and turn them into discrete events. Splunk’s Universal Forwarder does not do parsing; it simply lifts the new bytes being written to a file and throws them on to the indexing tier for parsing. In the log world, probably 80% or more of the data is simply a message per line, but as with all thing software engineering the remaining 20% is where all the hard work lies. Log systems need to support multi-line events, like Windows logs or stack traces. Cribl provides a new configuration primitive for configuring Event Breaking Rules.
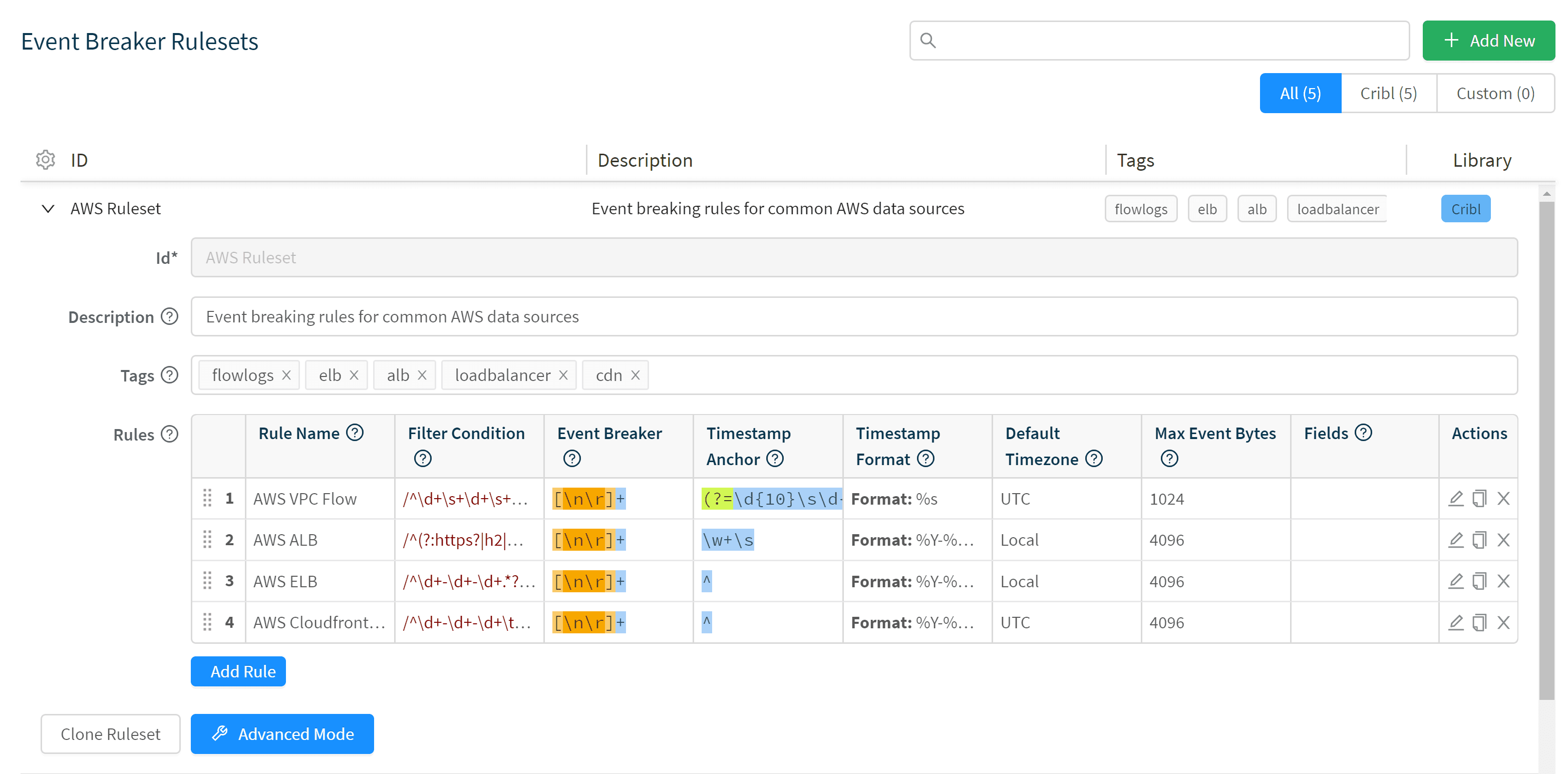
Rulesets allow you to configure Filter Conditions, which can include a match against raw bytes or any metadata that come in the event. Once we’ve identified which rule to use, you can configure a regular expression for breaking up the bytes into discrete events and a configuration with regex and strptime to extract time. By default, Cribl will use newlines and automatically extract timestamps, so back to the 80% case, usually we’ll work fine without any configuration at all.
Deploy on Splunk Indexers
Another important change with taking over the parsing workload is that we can now safely be deployed on Splunk’s indexing tier. Universal Forwarders are pointed to Cribl and Cribl sends data to its local indexer. For customers where they do not have a Heavyweight Forwarder tier or find it difficult to provision new capacity, this change allows us to move to production on their existing hardware footprint.
More Sources, Destinations & Samplers
In addition to making it easier to just drop into your existing environment and making it easier to deploy, we’ve also added support for Confluent Schema Registry to put data easily onto Kafka in Avro. We added support for Azure Blob Store and Event Hub to bring our Azure support on par with our AWS support. Lastly, we’ve added support for Dynamic Sampling, which allows the system to choose how much data to bring in and give you a reasonable distribution of data at a fraction of the volume.
That’s it for release 1.5.
If you like what we’re doing, come and check us out at Cribl.io. If you’d like more details on installation or configuration, see our documentation or join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to help you!






