

It’s been less than 4 months since we released Cribl Search, the first federated query engine focused on observability and security data. The reception has been tremendous. Customers, partners, prospects, and even our internal teams were overjoyed by the initial offering but have been anxiously awaiting the promises of the next release. The wait is over! The latest release of Search launches today and is instantly available to anyone with a Cribl.Cloud account– this includes licensed and free tier users!
If you are new to Crib Search, here is a quick recap. Cribl Search flips the searching of observability data on its head; no longer are you required to collect, ingest, and index before you can search. Cribl Search dispatches the queries to where the data is located — still on the host or in an object store.
However, with all new things, customer excitement of the first release quickly went from – this is a great new tool for data validation to, what more have you got? This was a blessing to our ears as we saw we had hit on something customers needed and as Cribl is focused on a principles-first approach to solving observability challenges. So we quickly laid plans for additional capabilities, linking our engineering teams with our development partners, and most importantly our customers, to determine the next steps and where we should focus on the next release. Now we are ready to introduce the results of this effort.
At the highest level, the message was: Data is everywhere, in many different types and formats, and no one can afford the cost to collect and index it all before searching it.
The initial version of Search was great to access data not previously available, but to address customer asks, we needed to make this version reach even more data, connect to even more systems, and most importantly, improve the user experience by making it faster, simpler, and more flexible. And we’ve done just that. We’re delivering a solution addressing customer challenges and empowering enterprises with choice and control over their data.
So…What’s New in Cribl Search 4.1?
Cribl Search 4.1 delivers easier access to more data, more automation, and enhanced user experience via a simpler and more powerful UI.
A More Intuitive and Informative User Interface
The most noticeable new features of Search 4.1.0 are the improvements made to the UI — users now have a greater ability to work within the table view and get insights from the data they’ve brought back from Search.
Access to More Data and Automatic Datatyping
Customers wanted us to expand the data and data types users have access to. Previously, Cribl Search was primarily able to read text, compress text, and archive files. One big ask we addressed in this release was to include access to Parquet, which covers data written out in AWS’s new security lake data product as well as other applications.
A close second to Parquet was journald files, which Linux servers are using to replace the plain text files of syslog, so adding it was an easy fit within our continuing goal to build an entire library of data types.
Additionally, direct access to stored Splunk rawdata files allows users to search data without the need to thaw back into Splunk. Optionally, results from Search can be routed into Stream and then sent to any of the supported Destinations, including object stores or other analytic tools.
Automatic Datatyping
One of our customers’ biggest challenges is a pre-search requirement to identify different data types and formats– we heard you. Now just point Cribl Search to a set of data and automatically discover the types of data, apply parsing, and extract new fields on the fly as required. Parsers are now configured alongside datatypes, requiring less manual intervention. Additionally, regular expressions and Grok formats are supported for text-based parsing and field extraction.
Strong Integration between Stream and Search
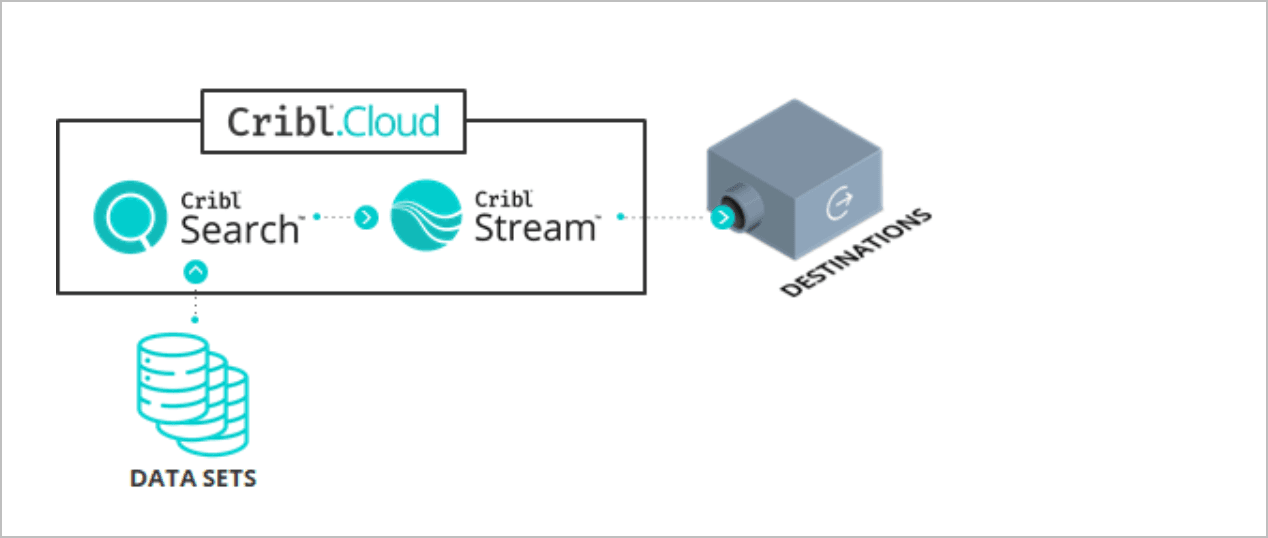
A continual request was for better integration between our flagship Cribl Stream observability pipeline and Search. So 4.1 added a Cribl Search-friendly S3 Destination in Cribl Stream. Using the send operator, users can Search and then forward search results back to Stream.
Enhanced User Experience
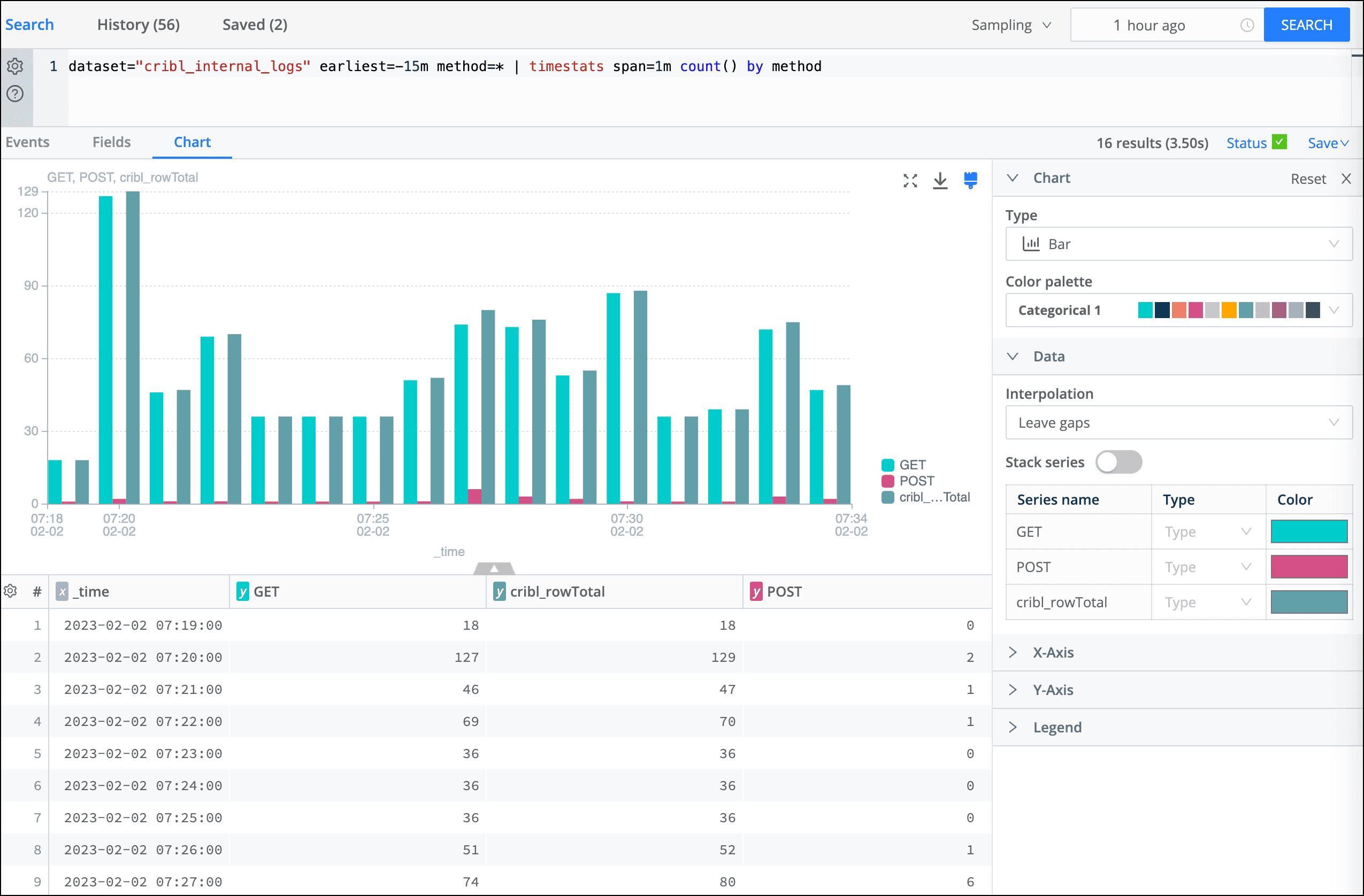
What about shaping query results at the browser level, what a great idea. Once the results are displayed, we’ve added the ability for column control: formatting, special settings, plotting, and data control: Filtering, coloring, and formatting – all accomplished locally. Additionally, local Operator Preview for query-time iteration allows analysts the ability to continuously improve their search syntax without incurring either the cost or time of resending the search to the destinations and waiting for their response.
And We’ve Only Just Begun
Cribl Search is revolutionizing data analysis by enabling insights without the need for data transport or ingestion. As a newly developed product, there are many exciting directions we plan to explore. Innovation is an iterative process, and we will continually seek input and feedback from our customers and the market, quickly iterate our solution and stay focused on delivering value to customers as quickly as possible. More capabilities are already scheduled for later this year, and if you are wondering what comes next, just check out our Cribl Community.
And remember, all of our products are complementary to customers’ existing tools and investments. We don’t seek to rip and replace. Rather, we seek to provide value to our customers, no matter what tools and solutions they have in place today.
For more information about Cribl Search, please attend our launch webinar on 3/22 and visit our Search product page






