

Data is growing, and we are being asked to search larger and larger amounts of data. This puts larger and larger demands on Search resources. Reading all the data to find matching events is muscling through the data. Wouldn’t it be more efficient to be able to do filtering before reading the data? Cribl Search does precisely that by leveraging Parquet Pushdowns. Let’s discuss Parquet Pushdowns and look at a Cribl Search example where we see a 96% reduction in computing resources using Predicate and Projection Pushdowns.
Understanding Parquet Data Format
For those unfamiliar with Parquet, it is a popular columnar storage file format and offers efficient data storage and processing. It’s widely used with large data processing and is the file format used in Amazon Security Lake. The critical performance benefits result from the columnar storage that Parquet leverages. Let’s understand the key differences between columnar storage vs. traditional row-based storage (CSV, JSON).
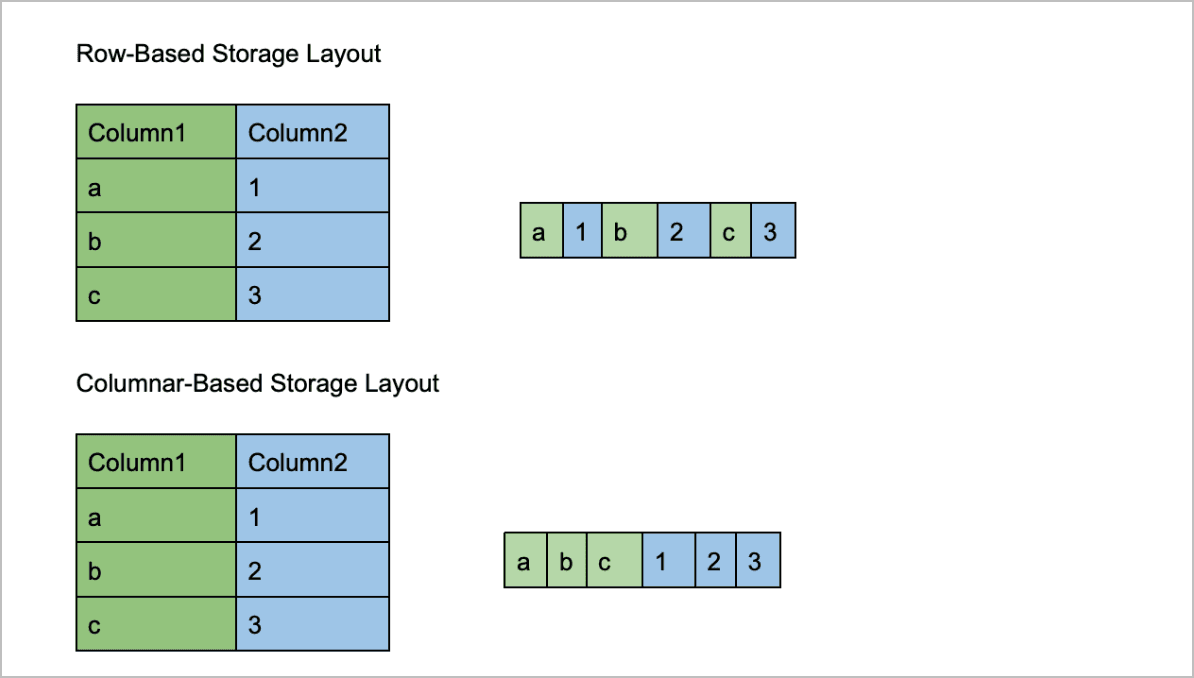
In row-based storage formats, the data for a single row is stored together on disk. In Parquet, however, the values for each column are stored together. With row-based storage, all the data for a single row must be scanned during a query. For many of the queries, we don’t require all the columns or fields to be involved. We can omit the unnecessary columns with these queries and only read the required ones. This reduces the amount of data read from the disk and dramatically impacts the query speed.
Parquet Dataset: NYC Limousine & Taxi Commission
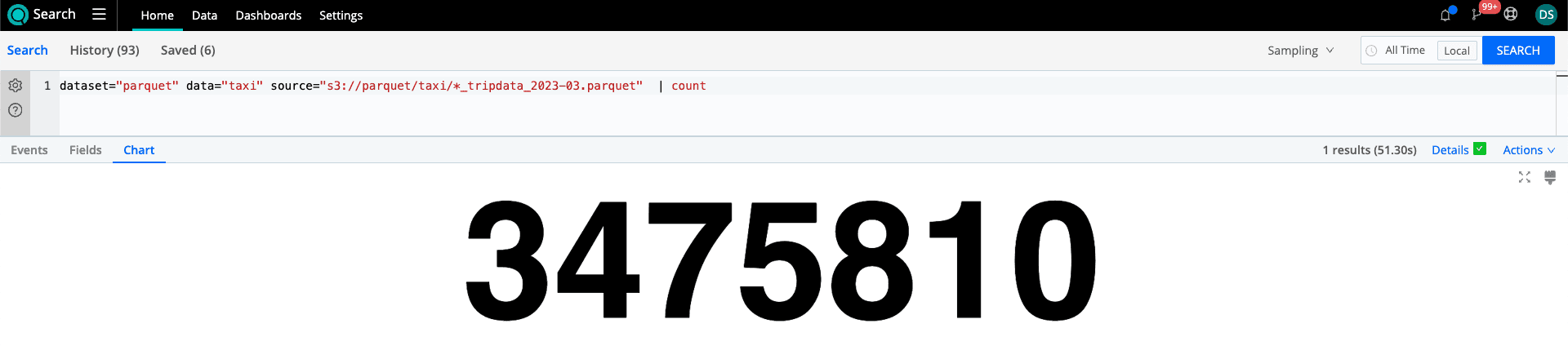
We’ll analyze the performance benefits using the NYC Taxi & Limousine Commission data. They provide trip data in the parquet format that can be accessed here. We’ll be using the Yellow and Green taxi datasets for March of 2023 to explore the performance gains of Projection and Predicate Pushdown. There are several fields in the dataset, and we’ll leverage searches focusing on the trip_distance field. The dataset includes over 3.4M taxi rides.
Projection Pushdown: Optimizing Data Access through Columns
Cribl Search’s utilization of Projection Pushdown optimizes data retrieval and process by selecting and reading only the required columns or fields. Projection is selecting only certain columns or fields from the Parquet file. Pushdown is the concept of having this work done at lower code levels. This filtering takes place where the data is read. Contrast this with JSON or CSV files where the entire row must be read, the field found, and then additional processing can be done. The Parquet format with Projection Pushdown has significant performance improvements focusing only on the fields that matter.
Let’s take a look at a simple search example to see what the performance gains are. We’ll look at the search where we want to find trips under 0.1 miles with and without Projection Pushdown.
dataset="parquet" data="taxi" source="s3://parquet/taxi/*_tripdata_2023-03.parquet" trip_distance<0.1 |count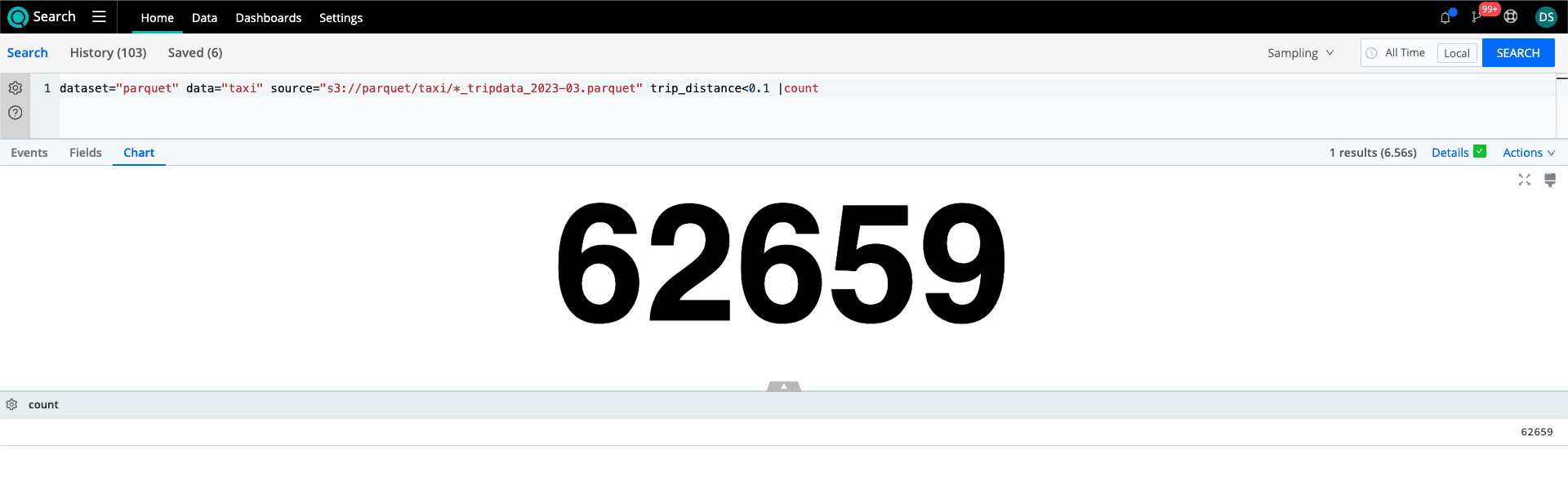
Without Projection Pushdown, every column is returned. However, in this search scenario, we only need a row count. We see that impact and benefit with 1.3GB being scanned without Projection Pushdown compared to 114.79MB when used. That’s a 91% reduction in the amount of data read.
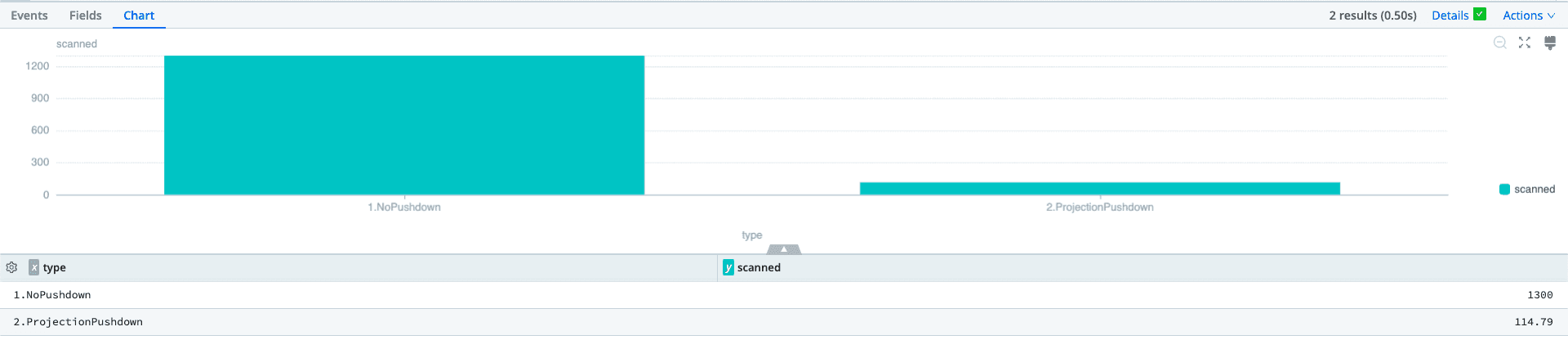
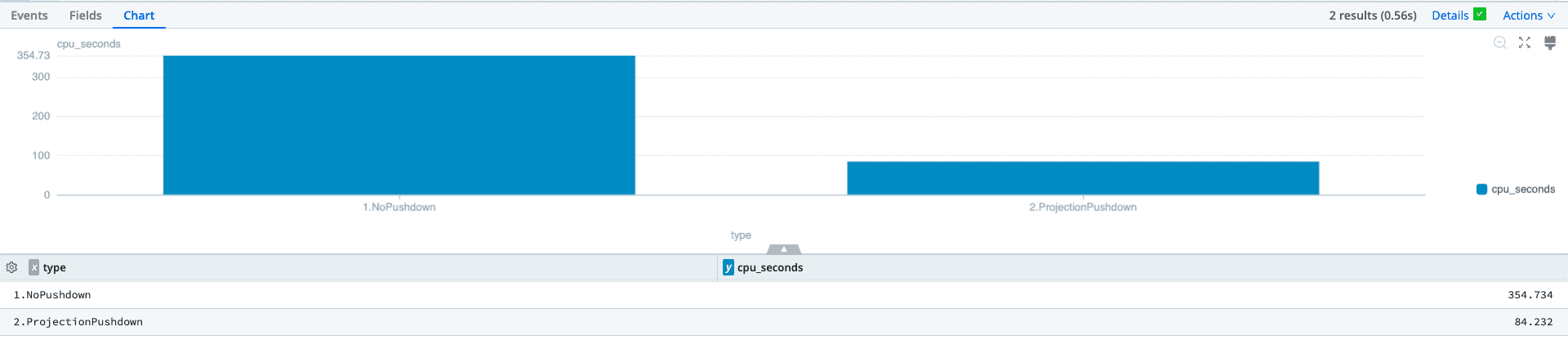
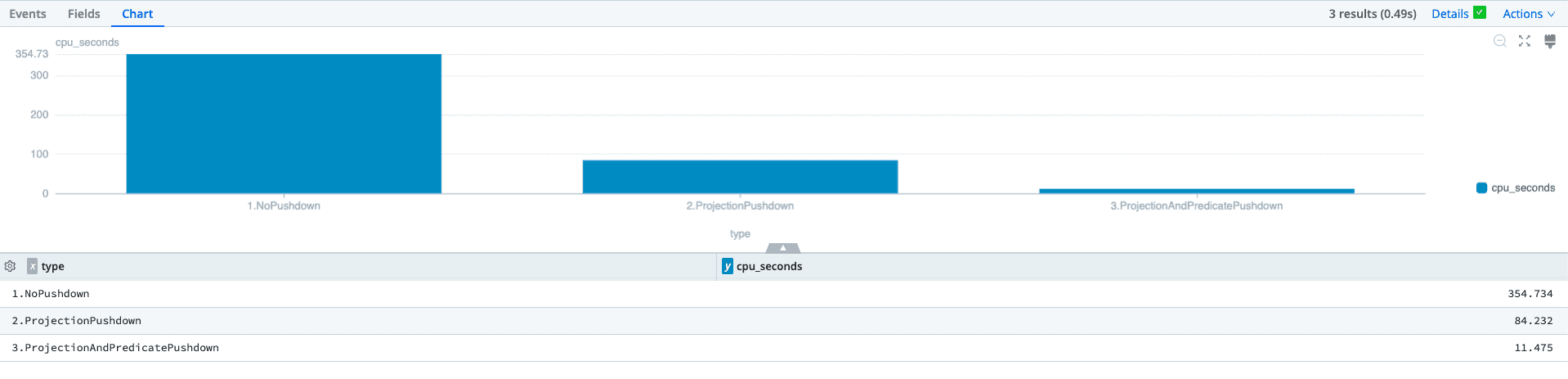
The benefits of optimizing data access and the columns read translate directly into the computing resources required to complete a search. When looking at the CPU Seconds required to run with and without the Projection Pushdown, we see a 76% reduction in compute time from 354.734 seconds to only 84.232 seconds.
You can also use the project operator within Search to determine what fields to include. This will limit the columns being returned as you project the columns desired. You can learn more about the project operator here.
dataset="parquet" data="taxi" source="s3://parquet/taxi/*_tripdata_2023-03.parquet" trip_distance<0.1 |project trip_distance, tip_amount, _time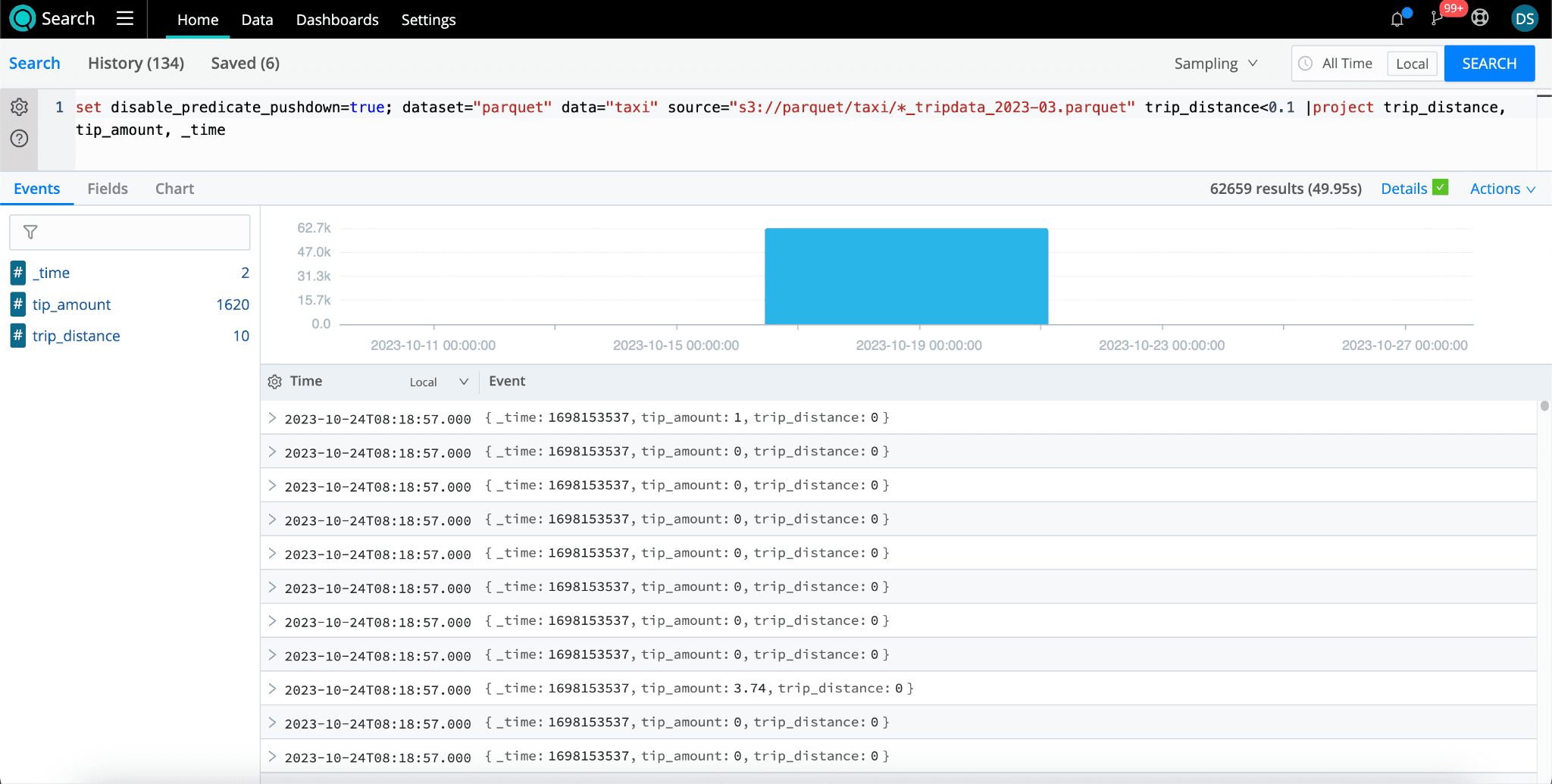

Reducing the amount of data read impacts the rest of the search processing and provides for more efficient use of resources. While Projection Pushdown gives us tremendous gains in performance, Predicate Pushdown can help us get additional benefits.
Predicate Pushdown: Further Optimizing Data Access
A predicate is a condition or filter you use in a query. Using our sample dataset and the search for the trip count under 0.1 miles, Predicate Pushdown takes that filter and pushes it down to the code that limits the data being read from the Parquet files. Our desired result is only to read the data with trips under 0.1 miles. To understand how this works with Parquet, we need to look at Parquet column metadata.
While Parquet stores data in the columnar format, it does not store all of the rows in a column together. Instead, it uses column chunks. Let’s oversimplify this for an explanation. Let’s assume our dataset has 20 rows. Parquet might break that up into 2 column chunks with ten rows each. For each column chunk, Parquet creates metadata, including statistics such as the maximum and minimum values for each column. You might envision it looking something like this.
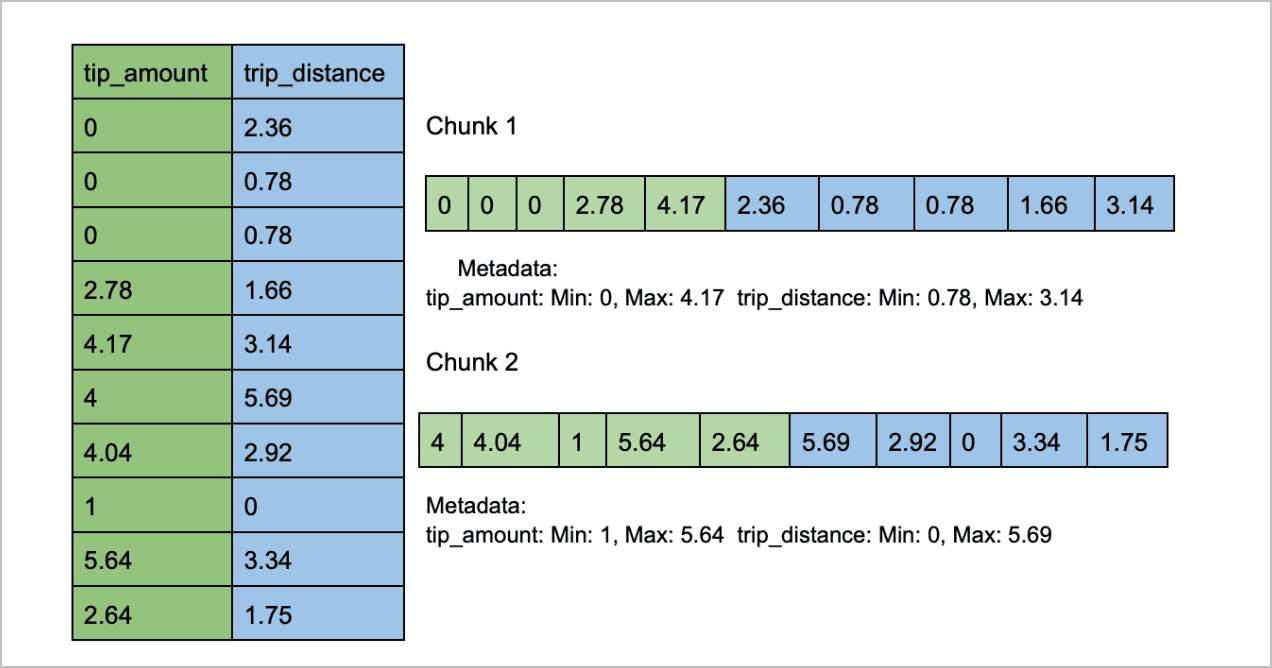
Cribl Search pushes down the predicate and reads the column chunk metadata to determine whether or not the chunk needs to be read and processed. With our search example we are looking for trips under 0.1 miles. Using the sample chunks above, Cribl Search would skip the first chunk because the minimum value in the trip_distance field is 0.78, above our predicate of trips under 0.1 miles. The second chunk matches our predicate, which would be read and processed. With large files, Predicate Pushdown can have a big impact. Let’s look at our example search and the impact of Predicate Pushdown on Cribl Search performance.
dataset="parquet" data="taxi" source="s3://parquet/taxi/*_tripdata_2023-03.parquet" trip_distance<0.1 |count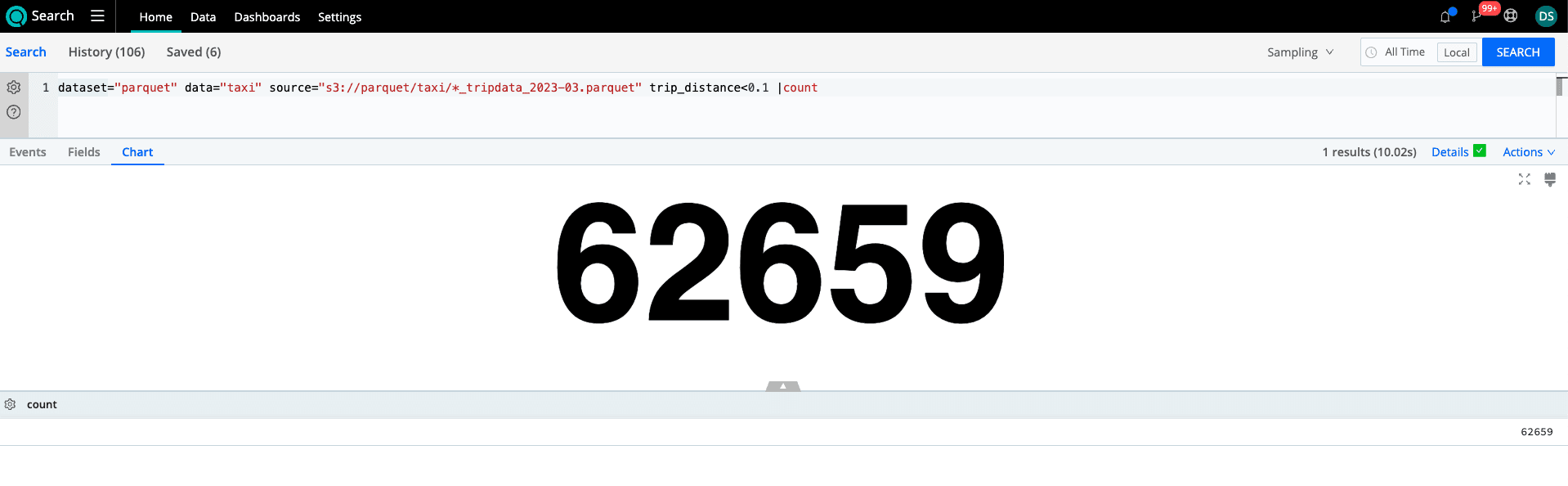
With Predicate Pushdown and the ability to skip sections that don’t meet the query parameters, we’ve reduced the data needed to read further. It is reduced by over 98% from the Projection Pushdown, with only 1.94MB read. That’s a massive reduction from the original 1.3GB.
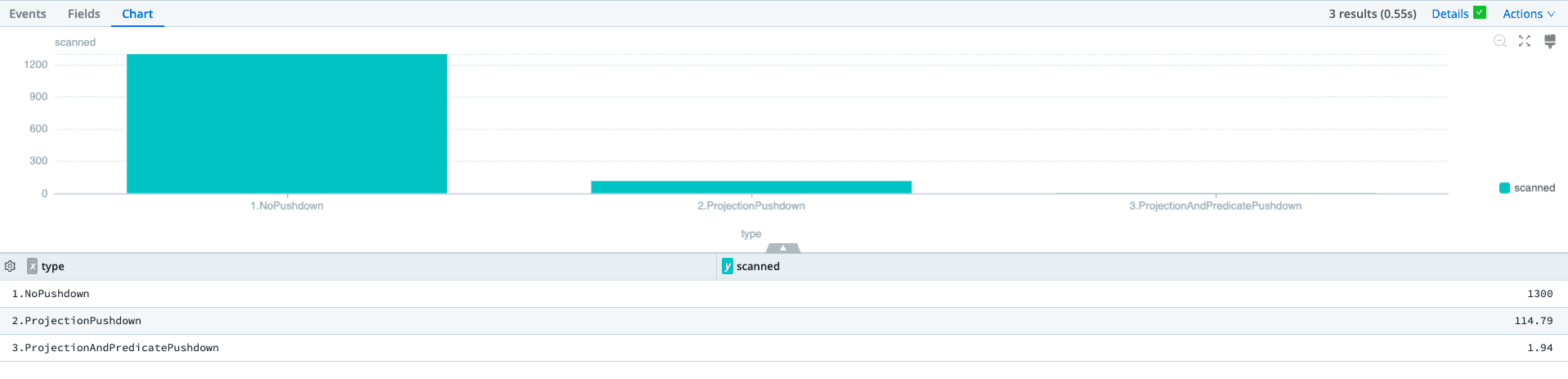
The CPU resources were reduced by over 86% as well. Up to 11.475 seconds, we have an extremely performant search that searches over 3.47M events.
Performance: Scale Without Compromise
Thus far, we’ve looked at some searches returning counts with just two files. The March 2023 Yellow and Green taxi data files. Let’s scale this up to a much more extensive search across existing 2023 data (January-July) and all the 2022 data. We’ll search across a total of 38 parquet files containing the data.
dataset="parquet" data="taxi" source="s3://parquet/taxi/*.parquet" trip_distance<0.1 |count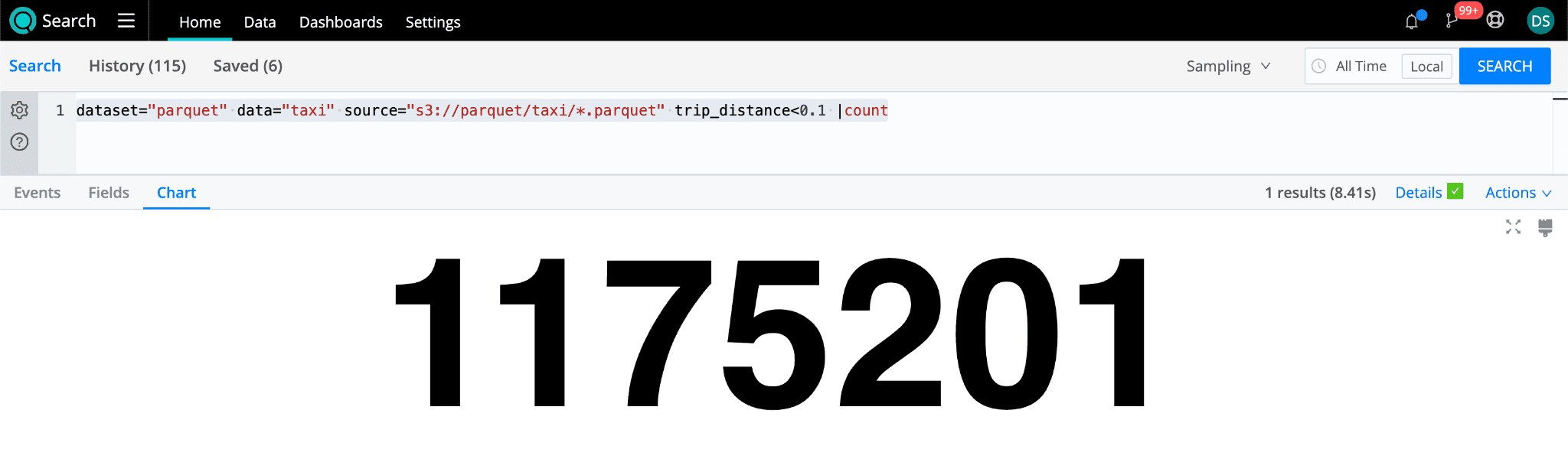
Even with the large data set, where we find 1,175,201 rides, the search returns in 8.41 seconds. Cribl Search only had to scan 36.46MB of data.

Summary
As data grows, we’re facing challenges regarding efficient search capabilities. We’ve looked at some of the Parquet data format benefits and how leveraging Projection and Parquet Pushdowns helps reduce the amount of data that needs to be read and processed to return search results. By default, Cribl Search leverages both pushdowns when searching files in the Parquet format to help customers get the most performant search experience.







