

Syslog is a very common method for transmitting data from network devices and open systems servers data to analytics platforms like Elastic and Splunk. As adaptable as syslog is, it still has significant constraints, which is a pain for most companies that lack the resources to scale their capability needed for syslog. Cribl Stream is purpose made to help businesses simplify syslog management so its engineers can spend more time on delivering business value projects and less time moving data around the enterprise. Let’s look at integrations with Cribl Stream and syslog. If you missed the first part of our Syslog series, check out this previous two blogs:
Common Struggles with Syslog Management
Data Velocity and Volume
Many organizations struggle to scale systems to handle the velocity and volume of data syslog devices like firewalls can generate. Single firewalls can generate hundreds of millions of events per day. Single servers with open source tools like rsyslog will only scale to a point and not provide high availability (HA) much less make administration easier. In addition, who can manage your syslog servers can get very limited. Every team has the syslog guy who knows how it all works and other people on your team can struggle to make config changes or provide support during an incident.
Timestamp Struggles
Timestamp management can be a huge struggle since not every vendor creates RFC compliant event timestamps and the device timezone is almost never present. Anyone that manages gear in multiple timezones knows the pain of the timezone offset. Most syslog timestamps have no timezone and with many enterprises home running logging back to the same syslog destination it can be hard to find your events in a time series visualization tool like Splunk. You ask your analytics tool to give all the events in the last hour, but any gear that is one timezone away or more be slotted one hour off and you will not see the events that are expected. It can be very frustrating and lead to slow incident resolution and general confusion.
UDP Data Delivery
“I’ve got a really good UDP joke to tell you, but I don’t know if you’ll get it”
This joke is older than I am, but still incredibly true. The UDP protocol is very light weight at the expense of any sort of delivery guarantee. Too many enterprises try to home run syslog data from remote offices and data to central syslog servers and do not realize how much data they are losing every day. In addition, high volume syslog requires horizontal scaling and load balancers which can be a struggle for many organizations. Another fun UDP fact is many routers and firewalls will drop large UDP packets and don’t even get me started when talking about local syslog server buffers to handle high traffic syslog.
Cribl Stream can help solve your challenges
Cribl Stream can resolve a number of Syslog challenges with a lot less effort. But how, you ask? Here’s how:
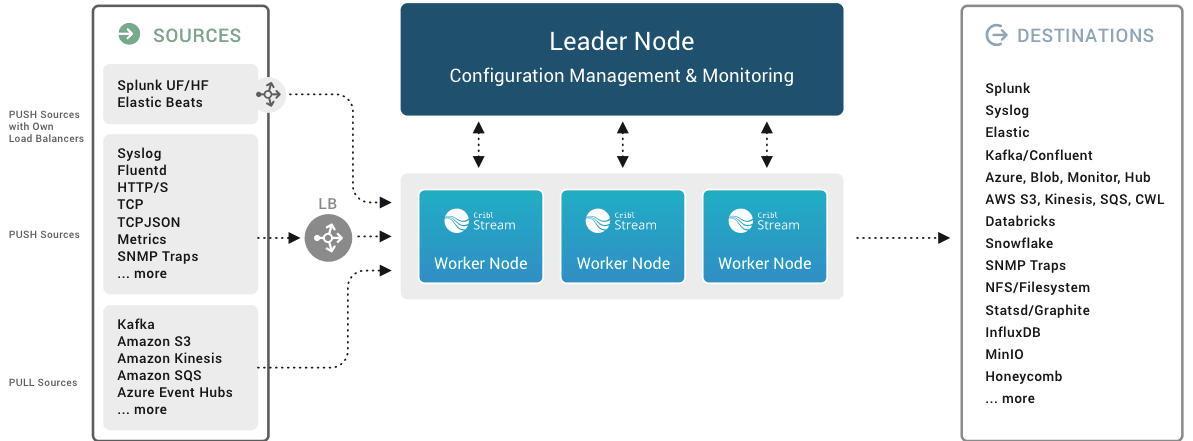
Scale to handle data Velocity and Volume
Stream gives admins several options to handle both data velocity and volume. Horizontal scale is a must and Stream offers easy scale by default. Its leader design makes it very simple to deploy as many workers as required with each having the exact same configuration. In addition you can monitor and manage all of your workers in the same UI. Adding workers is as simple as starting a container and pointing it at the leader with the right tag. The leader sees the new worker and assigns the config based on the tag. Your new worker is fully configured and monitored in a matter of seconds. Don’t forget to deploy a load balancer to spread the load across your workers for scale and high availability. Also break up your traffic by type across different pools to get the best results. Stream makes it super easy to add new listening ports to make syslog management approachable for the entire team and get away only the “syslog engineer” knows how to add ports.
Fix your Timestamps on the Fly
Stream makes it easy to detect timestamps and assign the correct time zones to syslog data. Ideally, you have deployed Stream workers as close as possible to your syslog sources so the default timezone assignment will be the timezone of the worker, but if that is not possible Steam makes it easy to assign the timezone of your choice to the syslog data source.

You can also fix bad timestamps or configure Stream to detect custom timestamps. Stream has a nice visual editor that makes it much easier for the engineers to manage timestamps.
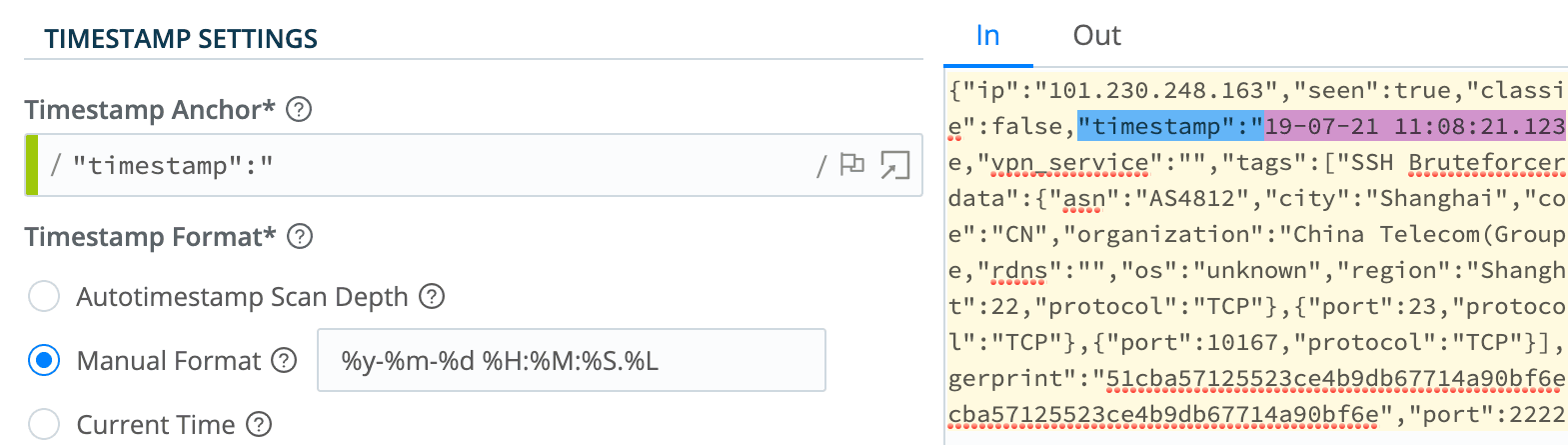
Cribl Stream gives you control over your event timestamps to get the best possible results. It offers easy to use options so your entire team can work on timestamp management and expand who can support Cribl.
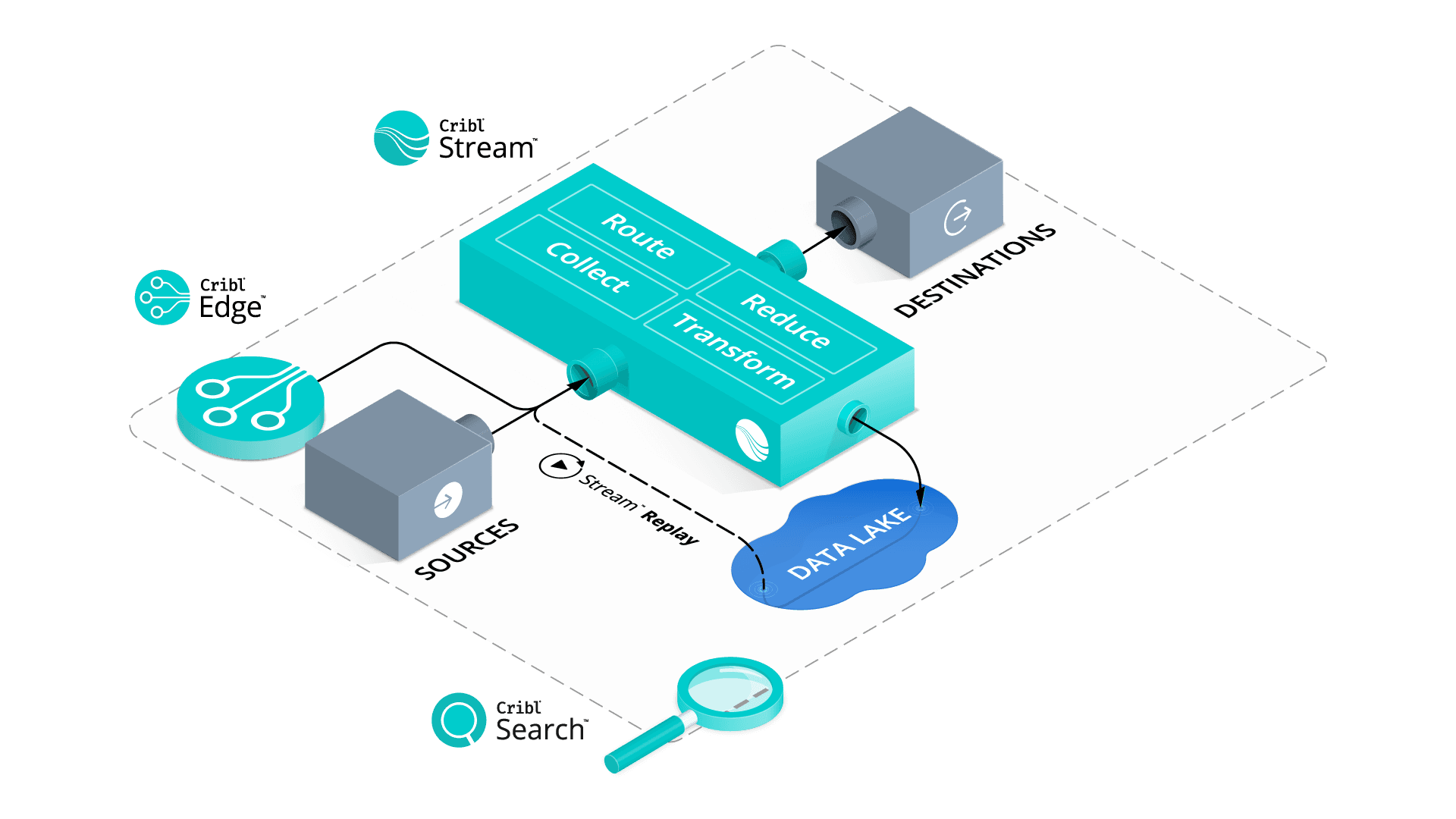
Collect all of your UDP data
The Cribl edge-focused deployment model offers a near-infinite capacity to process metrics, log, and trace data in real-time by moving processing for telemetry streams closer to the source, ensuring you are going to get all of your syslog data and be able to deliver it anywhere. Management overhead typically limits how legacy syslog servers are deployed, but Cribl Stream’s advanced leader/worker model eliminates the overhead and make it possible to get your workers as close to your syslog sources as possible while keeping your administrative head as low as possible.
YouTube Live Streams
Over the past year, we’ve also hosted two live streams on our YouTube page discussing how to scale syslog as well. I’ve embedded both of them below.
Bottom Line
Try Cribl’s free, hosted Stream Sandbox. I’d love to hear your feedback; after you run through the sandbox, connect with me on LinkedIn, or join our Cribl Community Slack and let’s talk about your experience!






