

Adding context with lookups is an awesome way to enrich your operational data. Whether you’re running simple searches or reporting on your events the more information they carry, the greater their utility. For example, if proxy or firewall logs indicate that an internal host is communicating with an external address that is known to be compromised, it would be great if this information was baked in as soon as possible.
Lookups are technically joins and many systems implement this type of enrichment at query time; i.e. when the information is retrieved or consumed. For the most part, this is a system design decision and works great in cases where lookup information is not available at ingest-time (load time) or the enrichment is fairly light.

Both, ingest time and query time lookups have their tradeoffs and they’re are not mutually exclusive. In fact, if the system allows for it, the best outcome is reached when both are used together.
Ingest Time vs. Query Time Lookups
Performance – Depending on the dataset size, the lookup size and its cardinality query time lookups can be quite expensive. Since the context is not baked in, every time an event is retrieved (i.e. every time users see that dashboard panel, or run that search etc.), a lookup/join operation must be performed. Ingest time lookups are also affected by size and cardinality but the enrichment is done only once (and permanently).
Temporal Correctness – Because query time lookups are done later in time, the data may have changed between when the event was emitted and when the lookup was done. For example, if you have a highly dynamic infrastructure and you need to resolve a resource name to its address you may not be able to do it as the resource and its records may no longer exist. Ingest-time lookups solve this by adding context as early in the event’s lifecycle as possible. Naturally, the assumption that is being made here is that we’re betting on information correctness at that time. (Which is a fair assumption – because we don’t want incorrect information at any time.)
Types of Lookups
Even though lookups technically join a dataset with another, from a functional POV, they can be binned in two categories:
Data Normalization lookups are the simplest. They are used to normalize fields names and values. For example, if you’re trying to understand network traffic in a hybrid infrastructure that is controlled by, say, Cisco ASAs and AWS VPC Security Groups you want to make sure that deny and reject mean the same thing. They are the smallest in size and cardinality and update rather infrequently.
Keeping/Tracking State lookups are the classic lookups/joins in the sense that they’re used in cases where an incoming data stream is truly enriched with data that is present elsewhere. Examples: adding a datacenter ID to an event emitted by a host therein, adding a flag that indicates whether or not a destination IP is on a watchlist, looking up username aliases in an identity list etc. These lookups can be implemented as:
Semi-Static: CSV files that are updated manually or automatically
Dynamic: Database tables, key-value stores, external scripts etc.
These types of lookups have the widest variance in terms of size, cardinality and update frequency.
Ingest-Time Lookups with Cribl
With Cribl you can lookup fields at ingest time by applying Lookup Function on any event that matches an arbitrary condition. Let’s take a look and see how we do it.
Let’s assume we have a lookup file cisco_sourcefire_severity.csv, and given both fields impact and priority in an event we would like to add a corresponding ingestion-time field called severity
impact,priority,severity
1,high,critical
2,high,critical
3,high,high
4,high,high
...
"*",medium,medium
1,low,medium
2,low,medium
...First make sure you have a route & pipeline configured to match desired events.
Next, let’s add a Lookup function to it with these settings:
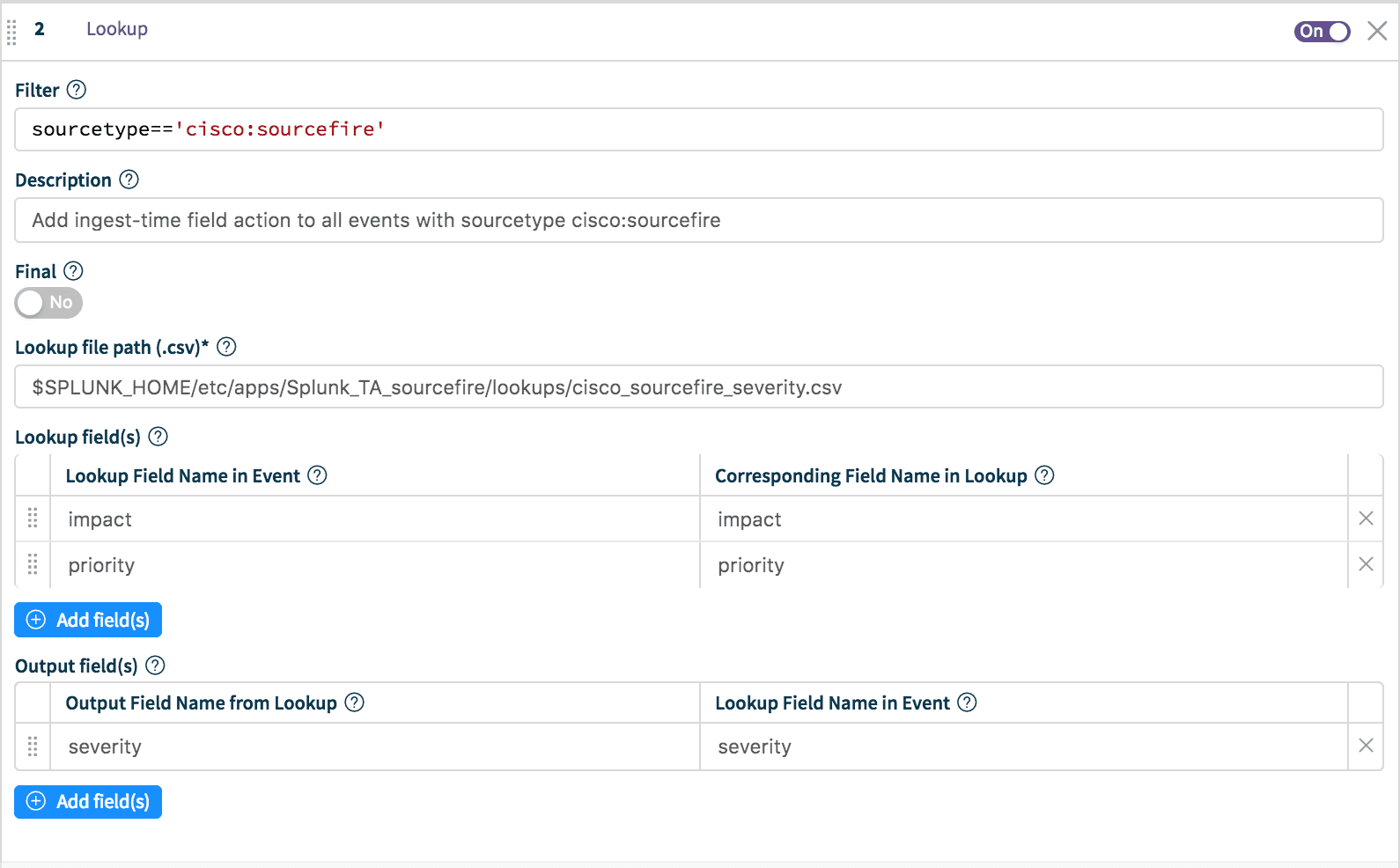
Lookup file path:
/path/to/lookup/file/cisco_sourcefire_severity.csvEnvironment variables are also allowed in pathLookup Field Name(s) in Event set to
impactandpriorityCorresponding Field Name(s) in Lookup set to
impactandpriorityOutput Field Name from Lookup set to
severityLookup Field Name in Event set to
severity
To confirm, verify that this search returns expected results: sourcetype="cisco:sourcefire" severity::medium. (Change severity value as necessary.)
Conclusion
“Precision beats power, timing beats speed” — Conor McGregor
Whether it’s to normalize field names/values – because good luck convincing developers to change those in code 😉 – or cross-correlating with a tracker/state table, lookups are one of the best ways to enrich data in motion. If you have strict performance and temporal correctness/relevancy requirements, ingest-time lookups may make more sense than query time lookups.
If you are interested on or excited about what we’re doing, please join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to hear your stories!







