

What new dataset providers can you search?
Cribl Search 4.2 adds Amazon S3, Azure Blob Storage, and Google Cloud Storage as dataset providers, so your cloud flow logs are one query away. Cloud storage is widely used and distributed across providers, which is why your search tool needs to access all of it. With Cribl Search 4.2, navigating flow logs across platforms works with commands like:
dataset="aws_s3_flowlogs" earliest=-1h | limit 1000
This query selects from the AWS S3 flow logs dataset, restricts the search to the most recent hour, and returns up to 1,000 records.
To query Azure or Google Cloud, swap the dataset name. Replace
dataset="azure_blob_flowlogs" earliest=-1h | limit 1000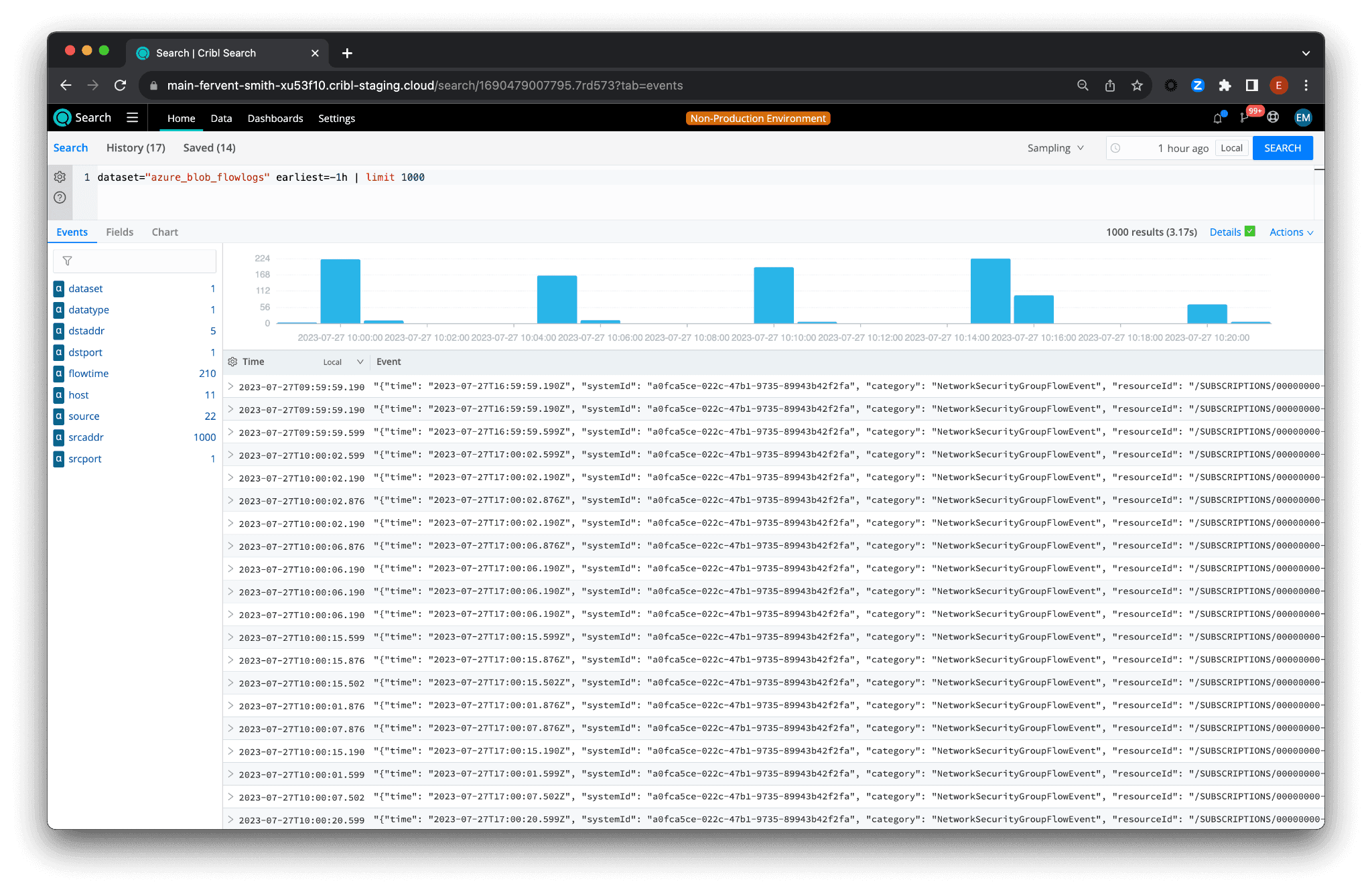
Or:
dataset="google_gcs_flowlogs" earliest=-1h | limit 1000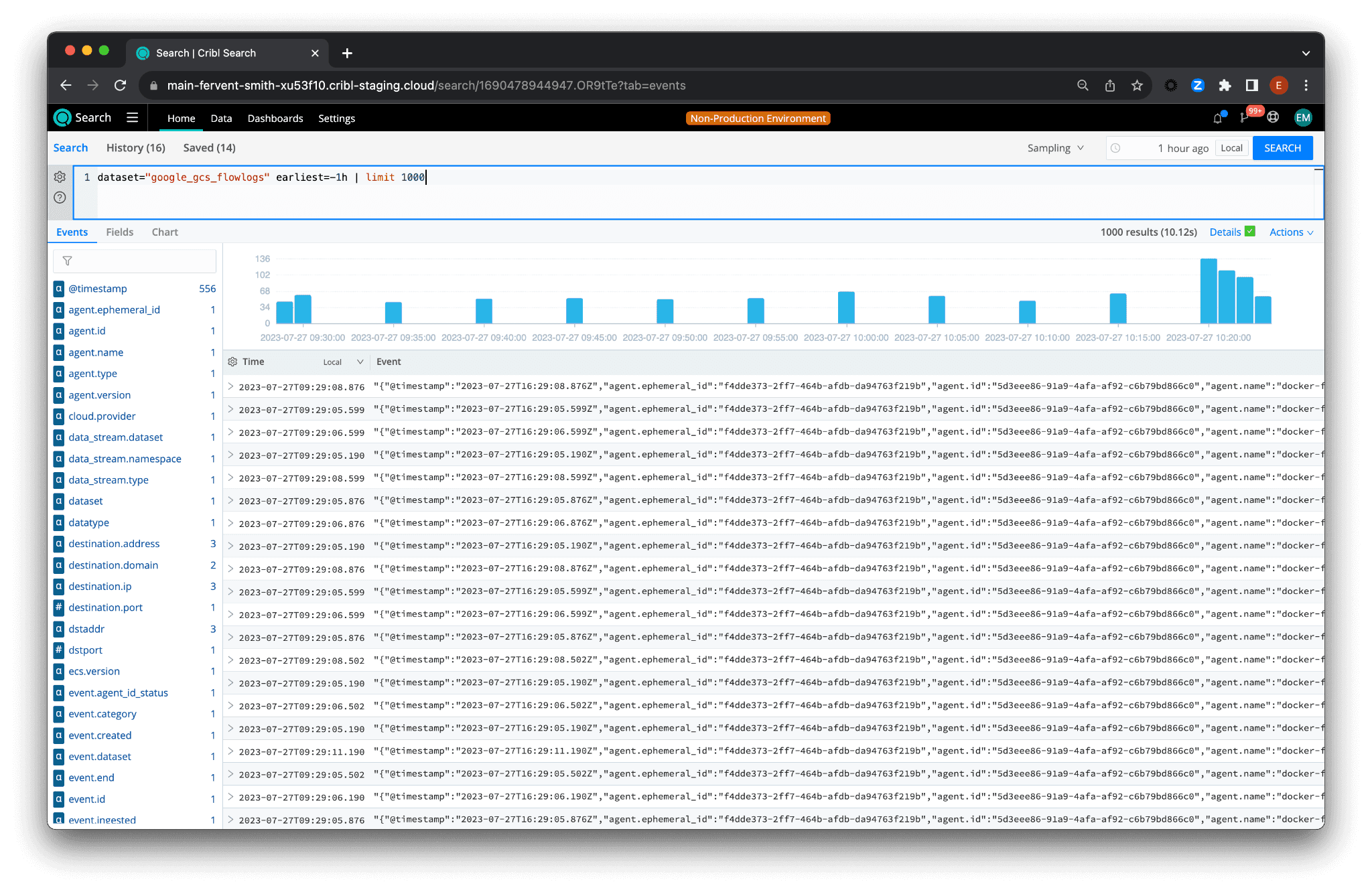
Same syntax, different cloud. You do not need new tools or to move data.
How does federated search work across all three clouds?
Federated search in Cribl Search means one query can target multiple datasets at once, regardless of which cloud holds the data. By appending _flowlogs to each dataset name, you can use a wildcard to search across them simultaneously:
dataset="*_flowlogs" earliest=-1h | limit 1000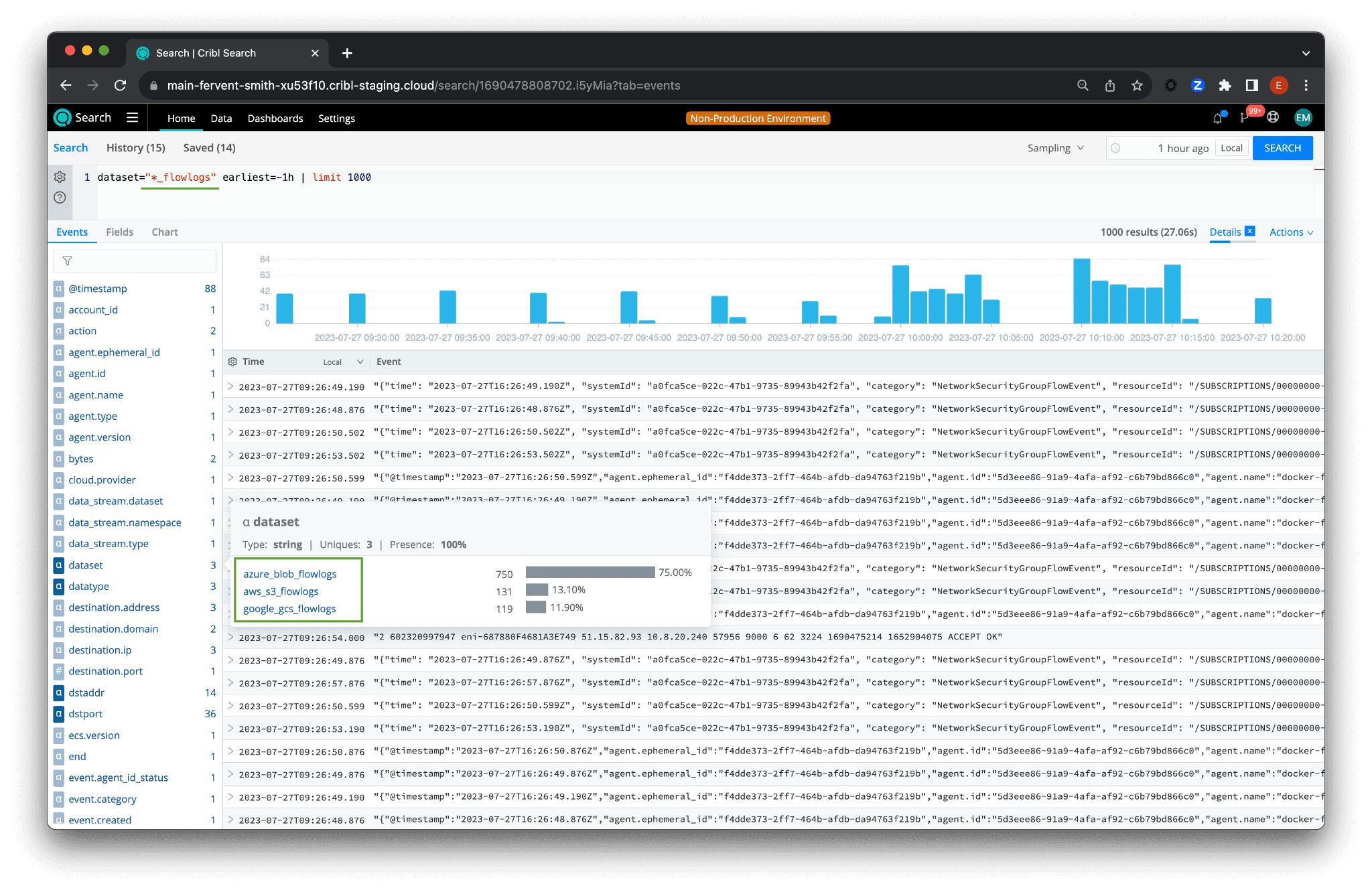
For example, to identify traffic patterns across ports and datasets within the last hour, use:
dataset="*_flowlogs" | limit 1000 | summarize flowcount=count() by dstport, dataset | extend port_and_source=dstport + ":" + dataset | project port_and_source, flowcount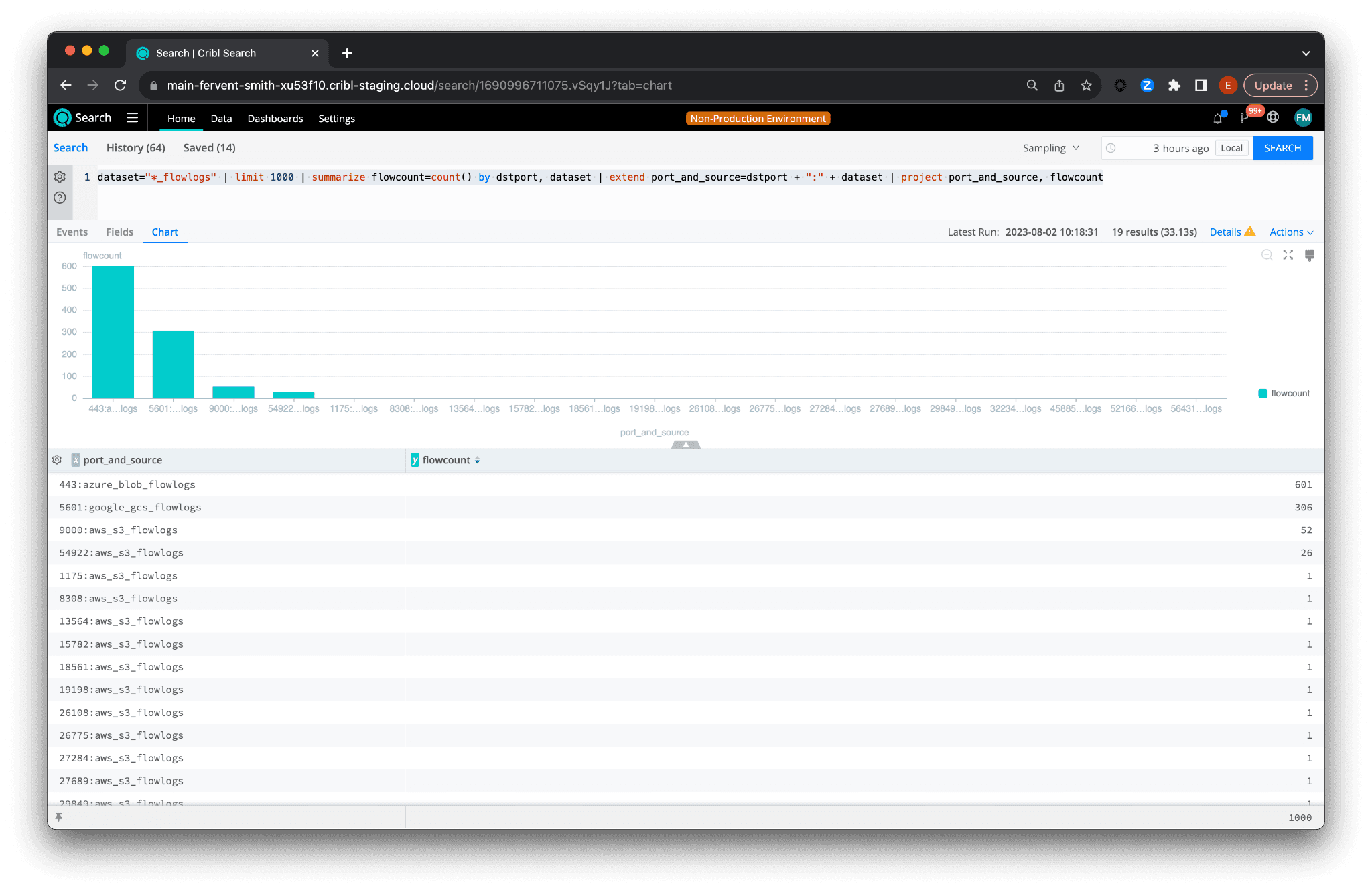
What each step does:
dataset="*_flowlogs"selects every dataset ending in _flowlogs, letting an administrator analyze traffic across all relevant clouds at once.| limit 1000restricts the pull to the most recent 1,000 records to keep the query responsive.| summarize flowcount=count() by dstport, datasetcounts traffic by destination port and dataset, showing volume per port per cloud.| extend port_and_source=dstport + ":" + datasetcreates a column that combines port and dataset into a single string.| project port_and_source, flowcountdisplays those two columns for a concise view of traffic patterns.
This produces cross-cloud traffic analysis in a single query. You do not need to export data or use spreadsheets. This example shows one way federated search simplifies analysis.
What does native support for Amazon Security Lake mean?
Cribl Search 4.2 queries Amazon Security Lake directly, without ingestion. This integration uses the Open Cybersecurity Schema Framework (OCSF) and the Parquet format, so security data remains standardized and searchable at the source.
For example, to access the Amazon Security Lake stage and return the 100 most recent records:
dataset="amazon_security_lake_stage" | limit 100
To categorize and summarize data by disposition using projection and predicate pushdown:
dataset="amazon_security_lake_stage" category_name="Network Activity" | summarize count() by disposition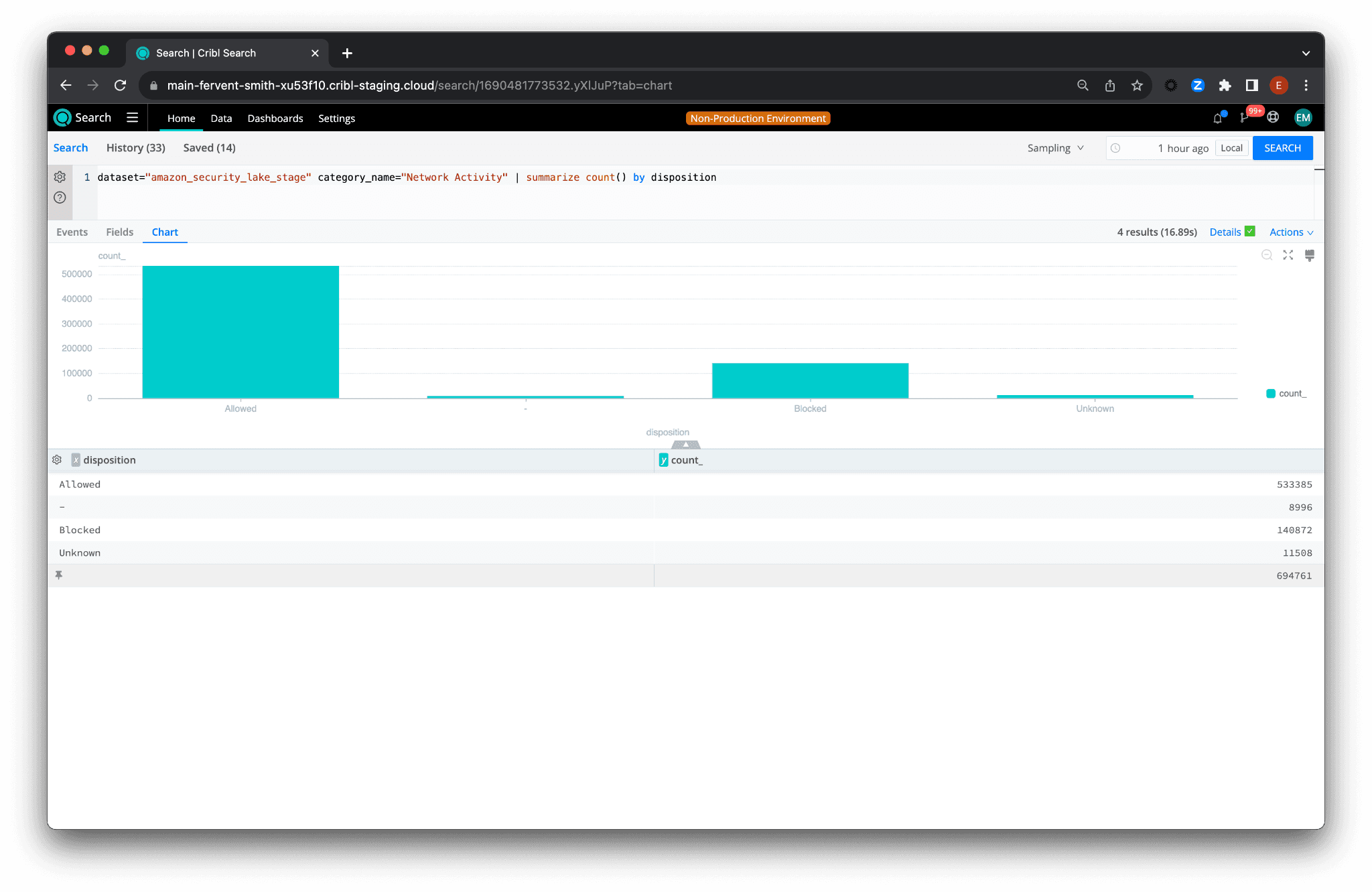
Only the data required for the query is processed, which reduces latency and cost. This is search-in-place.
How Cribl can help with federated search across cloud providers
Cribl is a platform for telemetry built on the idea that data should serve teams. When telemetry is scattered across clouds, formats, and tools, IT and security teams lose time and miss signals. Cribl Search removes those barriers by bringing federated, search-in-place queries to data where it lives, whether in Amazon S3, Azure Blob Storage, Google Cloud Storage, or Amazon Security Lake.
Because Cribl's platform is vendor agnostic, you are not locked into a single cloud, storage format, or analytics tool. Search data at the source, forward only the critical results to your analysis systems, and avoid the ingestion and egress costs of moving everything first. Combined with Cribl Stream for routing and transformation and Cribl's other products, you get control and flexibility over telemetry.
Extracting actionable insights from data lakes is possible regardless of cloud platform or security solution.
Sign up for a free Cribl.Cloud account to process up to 1 TB per day at no cost, or try a Cribl Sandbox.
Federated search across all major cloud providers FAQ
What is federated search in Cribl Search?
Federated search lets you query multiple datasets across different storage locations from a single interface, without moving or ingesting the data first. In Cribl Search, you can run one query across Amazon S3, Azure Blob Storage, and Google Cloud Storage simultaneously and return unified results in seconds.
Which cloud providers does Cribl Search support?
Cribl Search supports Amazon S3, Azure Blob Storage, and Google Cloud Storage. It also supports Amazon Security Lake, so you can search security data formatted in the Open Cybersecurity Schema Framework (OCSF) in place.
How do I search across multiple cloud datasets at once?
Give your datasets a consistent naming convention, such as appending _flowlogs to each dataset name, then use a wildcard in your query. For example, dataset="*_flowlogs" earliest=-1h | limit 1000 searches flow logs across every connected cloud provider in a single pass.
What is Amazon Security Lake, and how does Cribl Search work with it?
Amazon Security Lake is a data lake that centralizes security data in the Open Cybersecurity Schema Framework (OCSF) using the Parquet format. Cribl Search queries it natively. Cribl Search uses Projection and Predicate Pushdown to filter and summarize datasets at the source, so you only process the data you need.
Do I need to move or ingest my data before searching it?
No. Cribl Search is a search-in-place engine. Your data stays in its original location, whether that is an object store, a security lake, or an edge node. You avoid egress fees, duplicate storage, and ingestion costs while getting fast responses.
How much does it cost to try Cribl Search?
Free to start. Cribl offers a free tier through Cribl.Cloud that processes up to 1TB per day with no license required, plus hands-on Sandboxes and free training through Cribl University.






