

We’ve had a number of customers ask us about running LogStream in Kubernetes, and we’ve not really had an easily consumable answer. We love Kubernetes, and it’s pretty much our default approach running anything internally at Cribl these days, but we wanted to make sure that we could provide a mechanism for running LogStream in K8s that didn’t overcomplicate things, and that was reliable. After a lot of trial and error, we’re making available our Helm chart for Worker Groups. Eventually, we’ll be making a LogStream Master Helm chart available, but it’s a bit more complicated, and we want to get it right before releasing it.
What is Kubernetes?
If you’re not familiar with Kubernetes (often referred to as K8s), it’s a container orchestration system that makes it relatively easy to deploy container-based applications in a scalable, manageable way. It uses a declarative approach that promises to let you tell the system how you want it to end up, and let it figure out how to get there. As is often the case, that simple goal becomes incredibly challenging when it hits the real world, so K8s ends up being a very complex system.
One of the tools out there that has sought to minimize some of that complexity is Helm. Helm is a package manager for K8s. Think something analogous to YUM or APT on the Unix platform – a way to distribute largely automated software installs.
The Worker Group chart is designed to provide a simple, adaptable, and configurable way to deploy a LogStream Worker Group in K8s with an easy and clean service interface and autoscaling capability.
For those who just want to get to the “bits”, the Helm chart, and its associated documentation, can be found here.
TL;DR? Here’s a brief overview of the Helm chart – It provides a simple way to deploy a worker group via a single command on your existing K8s cluster. It’s been built on AWS EKS, but *should* work on any K8s cluster, as any AWS specific customizations are done via annotations.
Managed Distributions
Though we tried to make this as general as possible, the state of K8s is such that there are still differences “around the edges” in the managed stacks out there. As such, we chose the stack we run on internally, AWS EKS, as our baseline. While we expect that the Helm chart *should* run on any K8s stack, things like load balancing configuration, persistent storage, and cluster autoscaling may vary heavily between services.
Cluster Details & Prerequisites
At Cribl, our K8s clusters are running on AWS EKS. After trial and error, we’ve settled on using the C5 instance types, and we tend to use a mix of spot and on-demand instances. (We’ve found that the “burstable” T3 instance types tend to not work consistently with the horizontal pod autoscaler, but your mileage may vary.)
This Helm chart is intended to be deployed on clusters with node autoscaling enabled – because autoscaling pods on fixed hardware can cause resource contention. For EKS, the documentation here does a good job of explaining how to configure that. For other stacks, please refer to their respective documentation.
Deployment
In the Helm chart, we create 4 K8s objects:
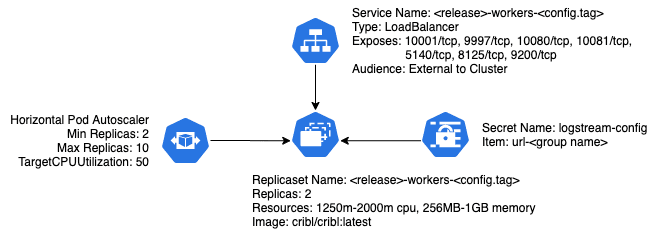
Service – The service is how your sources will connect to the Worker Group. It provisions a load balancer, listening on all of the ports specified in the `service.ports` value (overridable via the `values.yml` file), which balances traffic across all running pods.
Secret – This secret contains one value for each Worker Group deployed. This is the connection string each pod in the Worker Group will use to connect to the LogStream Master.
Deployment/ReplicaSet – This is the set of pods that get deployed.
Horizontal Pod Autoscaler – This component manages the autoscaling of the pods, based on CPU utilization. The minimum/maximum replicas, as well as the Target CPU Utilization for scaling, can be overridden via a `values.yml` file, or via the `–set` argument to `helm install`.
Service Management
One of the complexities in this deployment is managing inbound tcp/udp ports. While the K8s service abstraction makes this much easier, it doesn’t solve things like ensuring that firewalls/security groups have the ports available via the service open to the proper audiences. Nor does it solve the problem of configuring a source in LogStream and having it automatically represented in the service itself.
We did try to simplify it as much as possible, and defaulted it with what we think are the most common ports. But if you add a Source to your LogStream config, you will need to update your Helm release. This process is documented in the Helm chart Readme.
Wrap up
Often, publishing something is the end of the effort, the chance to clap your hands together and say “done… next!” That is not the case here – we’re learning as we go, and would love feedback at each step (via the #kubernetes channel in our Slack community). Please try the Helm chart and let us know how we can make it better and easier to use. We have plans to build other Helm charts for running a LogStream Master, as well as running LogStream as a Daemonset; we see K8s as a very important deployment option for our product.






