
At the beginning of November, we announced the availability of a Helm chart to install and run a LogStream worker group on Kubernetes. That was the first of a few things you’re going to see from Cribl with regard to Kubernetes. The next one is the availability of a Helm chart to install and configure a Cribl LogStream master instance on a Kubernetes cluster, and I’m happy to announce that that is available now in our helm-charts repository.
TL;DR – What Is the Cribl LogStream Master Helm Chart?
The logstream-master helm chart is a simple way to install and do basic configuration on a Cribl LogStream master instance. It allows you to, with a single command line, spin up a master node, install a license key, configure one or more worker group configurations, and set the instances’ admin password and master authentication key. If you wanna just skip to the Helm chart, take a look at the Helm Chart repo.
Persistent Storage
Unlike the logsteam-workergroup helm chart, this chart has a requirement for maintaining state. In the 2.3 release of LogStream, there are four directories where state is maintained:
/opt/cribl/local – where all of the local configuration for the master lives
/opt/cribl/state – where LogStream keeps internal state information, including data collection job status and artifacts.
/opt/cribl/data – where all global sample data, and lookup files, are kept
/opt/cribl/groups – where configurations for worker groups are staged and managed.
We looked at two different mechanisms for maintaining the state information – 1) use an external git repository to “rehydrate” the instance upon creation, or 2) use persistent storage that can be mounted on the master pod as part of its lifecycle. For the helm chart, we chose the persistent storage approach for simplicity. Also, this way the helm chart does not require a LogStream Enterprise license (remote git access is an Enterprise feature).
Due to this requirement for persistent storage, you’ll need to set up a (preferably default) storage class. The implementation details will be different for each Kubernetes cluster, but in our case, we’re using AWS’s EKS service, the EBS CSI driver, and a default storage class called ebs-sc. Make sure to understand the limitations and challenges for the storage driver you use. (For example, with EKS and EBS as the storage class, it’s very important that your cluster is “AZ aware”, or you’ll run into problems with nodes not being able to mount the storage volumes.)
Preconfiguration
While LogStream is typically configured in the UI, the logstream-master helm chart provides a few options to “preconfigure” the instance. These can all be configured either by creating a values file and giving helm install the -f <filename> option, or via the --set argument. The overridable values for “preconfiguration” are:
0 to Distributed in About 5 Minutes…
The combination of both the logstream-workergroup and logstream-master helm charts gives us a very simple and quick way to deploy a distributed LogStream environment. Let’s say that we want to create a complete distributed environment with one worker group (named all-logs), and we want to use a generated UUID as our authentication key,
We also like using namespaces to achieve a modicum of isolation, so let’s start out by creating a logstream namespace, via the kubectl command:
kubectl create namespace logstream
And, we’ll use the uuid command to generate an auth key:
helm-charts% uuide448c60a-2d24-11eb-a601-c78b7f337b04
Now, we’ll use the helm command to install the master instance:helm install ls-master cribl/logstream-master --set config.token="e448c60a-2d24-11eb-a601-c78b7f337b04" --set config.groups=\{all-logs\} --set config.license="<license key>"
Now, if you look at the output from kubectl get all -n logstream, you’ll see something like this:helm-charts% kubectl get all -n logstream
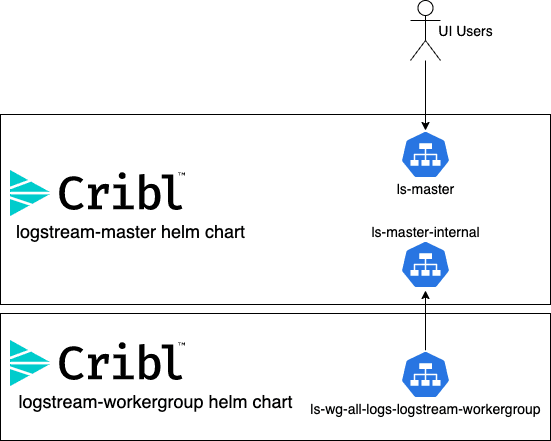
You may notice that there are two services defined:
ls-masterls-master-internal
Those services are named after the helm chart “release” that was specified in the helm install command. Since we used ls-master, the primary service is the ls-master service. This service is intended for end-user access to the LogStream instance, and exposes the 9000 TCP port. The other service is ls-master-internal, which exposes the 9000 AND the 4200 TCP ports, and is intended as the endpoint for worker groups to connect to.
Now, to create our worker group, we simple run the helm install command for the logstream-workergroup chart, with a couple arguments:
So, if we run:
helm install ls-wg-all-logs cribl/logstream-workergroup --set config.token="e448c60a-2d24-11eb-a601-c78b7f337b04" --set config.tag="all-logs" --set config.host=”\"ls-master-internal" -n logstream
…this sets up the worker group and connects it to the master. Looking at the output of kubectl get all -n logstream again, you should see something like this:
helm-charts kubectl get all -n logstream
You’ll notice that we have a new service ls-wg-all-logs-logstream-workergroup – this is the load balancer that you’ll need to point all your sources to. After just a few commands, you now have a working distributed deployment of Cribl LogStream!
The Journey Continues…
As I mentioned when I announced the logstream-workergroup chart, this is not “fire and forget” – we’re learning as we go, and would love feedback at each step (via the #kubernetes channel in our Slack community). Please try the charts, and let us know how we can make them better and easier to use.






