

Log events come in all sorts of shapes and sizes. Some are delivered as a single event per line. Others are delivered as multi-line structures. Some come in as a stream of data that will need to be parsed out. Still, others come in as an array that should be split into discrete entries. Because Cribl Stream works on events one at a time, we have to ensure we are dealing with discrete events before o11y and security teams can use the information in those events.
Cribl offers intuitive and powerful event breaking management. In this post, we’ll review the basics of event breakers (EB), using the Cribl EB ruleset editor, how to handle multiple rules and rogue events, and the different types of EB rules. When we’re done, you should have a good idea of how to manage EBs across all your source types, whether you have 10, 1000, or more source types to deal with. You can also follow along by watching the video below.
Why Event Breakers?
EBs allow Cribl to define, or redefine, where one event ends and another begins, so Cribl Stream can process events accordingly. Sometimes this is obvious. For example, many Linux system logs write a single event per line: Each line starts with a timestamp, and each line is an event:
Jan 11 13:42:05 hp1 tailscaled[263820]: Accept: UDP{100.87.247.21:47164 > 100.85.176.20:53} 57 ok outJan 11 13:42:05 hp1 tailscaled[263820]: magicsock: disco: node [Bs3G5] d:09d6e66678e506ec now using 192.168.100.207:41641
That’s pretty easy, but also pretty limiting. Many modern apps log in JSON. Sometimes this JSON is all on one line, as with the previous example. Sometimes it’s ‘pretty-printed’ to be more human readable, spanning hundreds of lines. In theory anyway:
{"host": "web1","MemTotal": 16169300,"MemFree": 515888,"MemAvailable": 13949816}{"host": "web2","MemTotal": 16169300,"MemFree": 515888,"MemAvailable": 13949816,}
Some agents simply read data off the disk or network and send a stream of data at the analysis tier. Some will chunk the data into events automatically. Sometimes you’ll receive logs directly from applications. Still, there are times when you’ll want to further segment the data. Maybe the “event” is the result of an API call with multiple items contained in the payload. It may be more appropriate to break that block of text into separate entries.
Whatever the format of the incoming data, we need to define where one event ends and another starts before we can begin processing, and ultimately, analyzing the data.
We also need each event to have a time associated with it. Time formatting is a vital variable you’ll need to deal with as a log admin. It seems like everyone wants to make their own format. Time extraction is part of the event breaking step, and your rules can include specifications for the time format. Or they can rely on Cribl to automatically find and parse the timestamp. You can also specify the use of now() as the event time, if appropriate.
Let’s dig into how Cribl helps you manage and organize your EB rules.
Cribl’s Event Breaker Rulesets
Each Worker Group has its own EB Rulesets found under Processing > Knowledge > Event Breaker Rules:
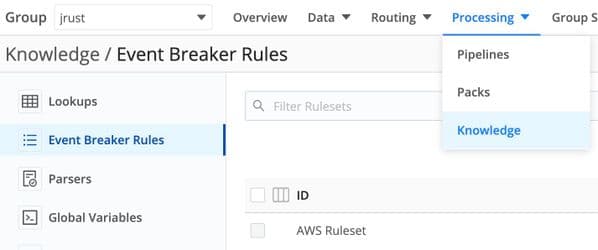
Each EB Ruleset can contain multiple rules. Each rule contains a filter that will determine if the rule’s EB policies should be applied to the current stream of data. Finally, you apply one or more rulesets to a source configuration. When data arrives for a given source, the EB Rulesets are processed in order. Each rule in the rulesets is also processed in order. The first rule in any ruleset that has a filter matching the data will win. No other rules nor rulesets will be checked.
Some sources are based on protocols that define inherently where event delimiters are. These sources do not have an Event Breaker option. You can still use an EB Ruleset from within a Pipeline further down the stack.
The ruleset and ordering structures allow an admin to create manageable lists of precedence-based EB definitions.
Working with Cribl Event Breaker Configurations
When I create or modify a rule, my first step is to get sample data into the preview pane. You can either paste directly into the window, or you can upload a file containing sample data.
Limit the size of the data you put into the preview pane to ~500 KB or less. This limit won’t apply to events in actual processing. It only applies here because the JS engine in your browser does not deal with a big chunk of data very well.
In the screenshot below you can see the config for the apache rule contained in the my-sourcetypes Ruleset. Sample data is on the right, with In selected. On the left are the configuration values for this rule.
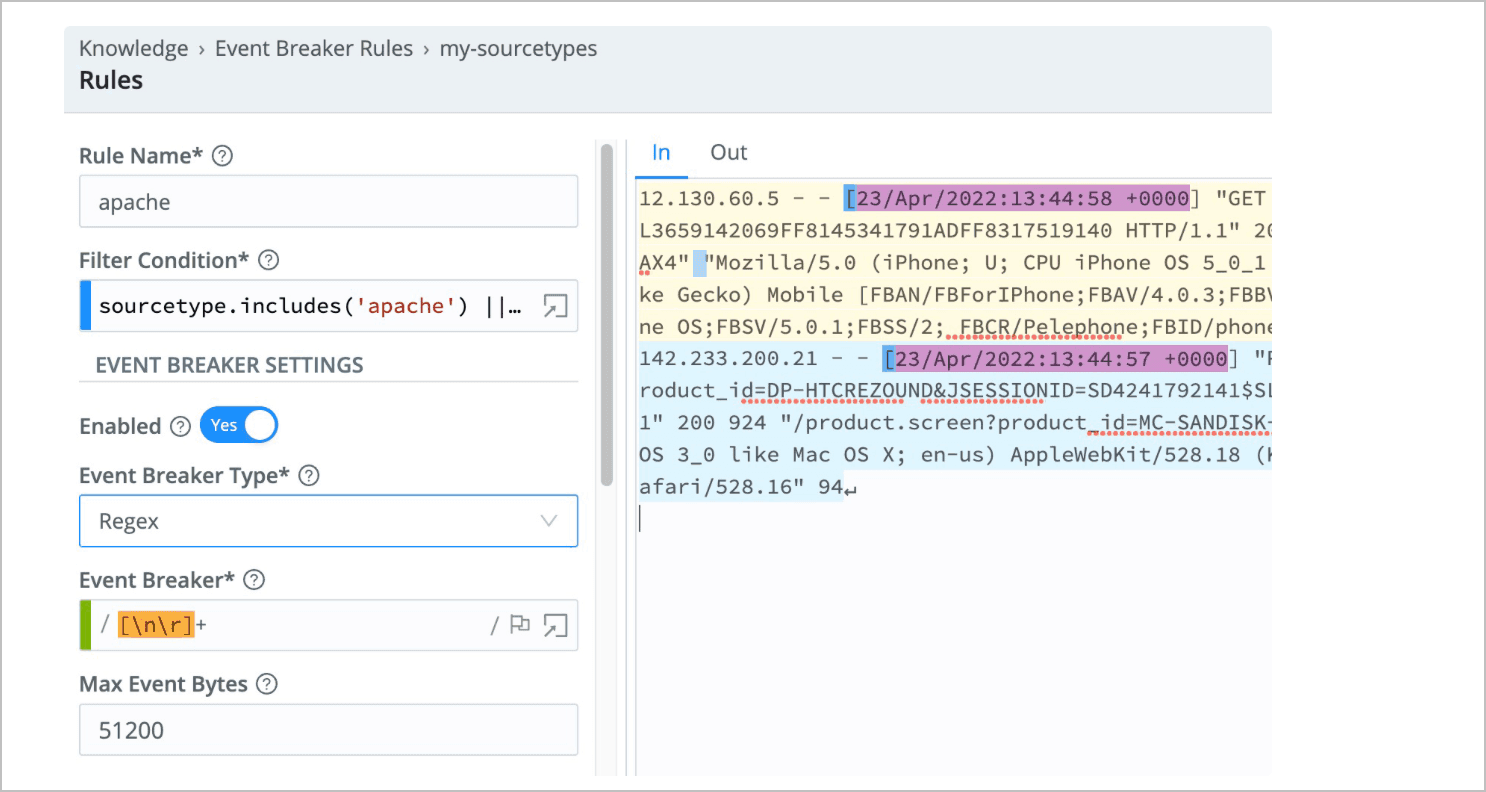
Clicking the Out tab will reveal the impact of the EB configuration on sample data:
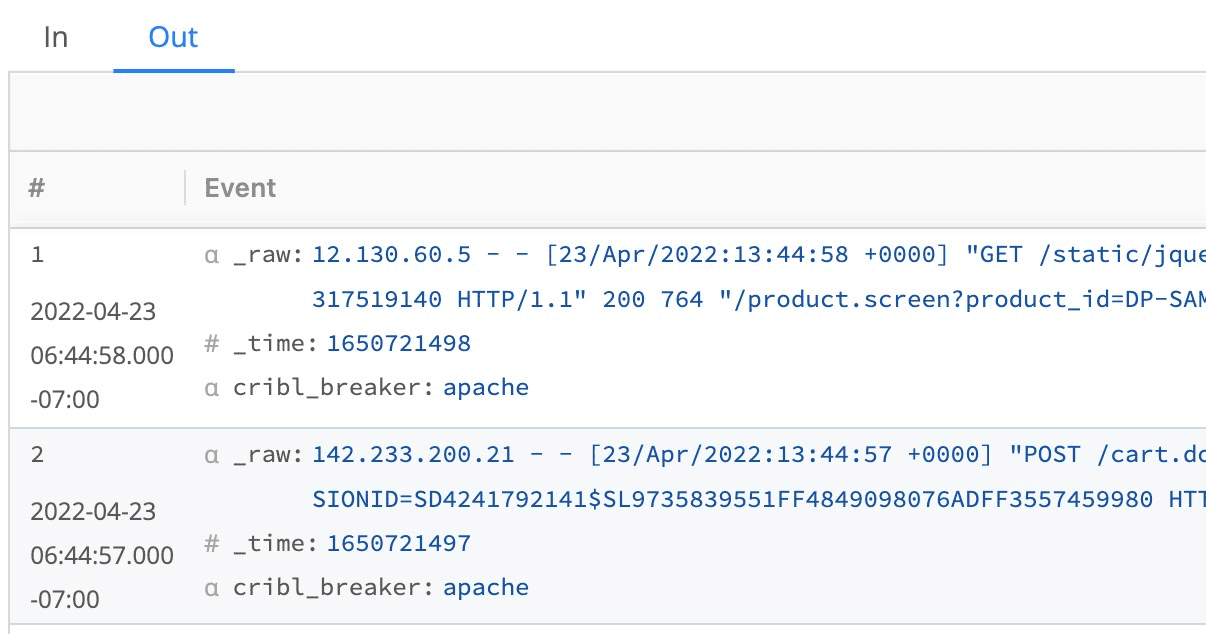
The Out tab allows the administrator to verify the events are broken properly. Also, note that the leftmost column shows the extracted time for the event. This is vital to verify. Compare what you’re seeing here with what is in the event text.
Different Types of Breakers
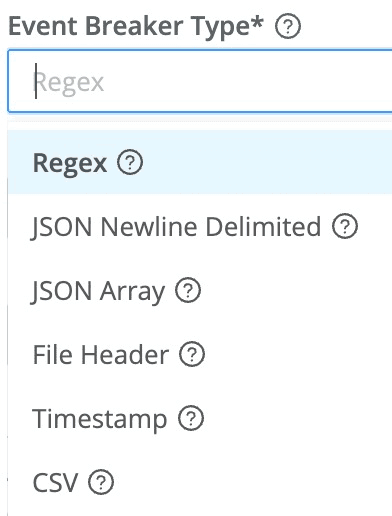
Cribl’s docs detail the six different styles of Event Breakers currently supported. Briefly:
Regex: Define a regex to identify the start and/or end of events.
JSON Newline Delimited: Cribl’s default data format. Each line is a single, valid, JSON object.
JSON Array: The stream presents as events grouped into JSON arrays. (Amazon CloudTrail is a common source that would use this method.)
File Header: Allows you to consume data defined by the first line in a file, extracting the fields defined as the file is read. (IIS logs from Windows servers are good examples.)
Timestamp: For any new line presented, Cribl will look 150 bytes into the line (by default), checking for a timestamp. If one is found, the entire line starts a new event.
CSV: Similar to the File Header option, but dedicated to CSV. You can choose the delimiter, quote, and escape characters.
Where to Use Event Breakers
The most common place to use EBs is in source definitions. For sources that support EBs, the setting is listed on the left side of the configuration modal. You’ll be able to “stack” several rulesets into a list, which will be processed in order. The first rule that has a matching filter will win, and no other rules or rulesets will be checked.
There are always exceptions. Some sources don’t include the option for an event breaker because the protocol involved strictly defines that already. And sometimes you’ll need more than one opportunity to break or unroll, events from your original data. For these cases, you can use EBs from within Pipelines with the Event Breaker function. The result will be multiple independent events processed by your Pipeline after the EB function fires.
Best Practices
A typical logging estate could see dozens, hundreds, or even thousands of log styles. By grouping similar use cases or log styles into rulesets, you can make the management of these rulesets easier. Here are some best practice recommendations.
Every source that can have an Event Breaker should have one assigned to it. Don’t rely on the fallback breaker. This way you can spot suspect logs by searching for
cribl_breaker == 'fallback'Create two types of rulesets. One should contain very specific filters, like source and sourcetype matches. The other ruleset should contain more broad, pattern, and/or regex-based rulesets. Place the specific ruleset first in processing order. This way we process the easy rules early and only land on the more complex rules later.
On the other hand, if you have one log style that makes up the lion’s share of your volume, it might be best to parse that rule first.
Be thrifty about including regex, especially complex regex, in your breaker rules and filters. Using
.startsWith(),.includes(), or.indexOf()are all much faster alternatives. That said, sometimes you just need regex.Choose the right breaker type for the job. It’s easy to just use the regex hammer for everything that even vaguely resembles a nail. Sometimes there are better ways. Explore how the other breaker types work.
Don’t neglect the Add Fields to Events section at the bottom of the EB config window. This is incredibly handy. For example, you could extract a field at EB time that can more easily be referenced in routing and pipeline work later. It’s like a mini, Eval-only pre-pipeline.
Know your time parsing variables. If you can rely on a particular time format, specify it. This will save cycles vs letting Cribl try to figure it out automatically and make your time extraction more reliable.
Understand the data you paste (or upload) into the preview pane. Where are the event boundaries? Is this the exact shape of data Cribl will receive off the wire? What time zone is represented?
Conclusion
“Clumped” together events, truncated events, and bad timestamp extractions can throw up massive impediments to investigations, putting your organization at risk. By leveraging event breaking, teams can ensure Cribl Stream works on events in a way that streamlines response. I hope I’ve shed some light on how powerful Cribl Event Breakers are. They give you more flexibility than ever before, while also making management straightforward.
If you have an interesting use case, hop into Cribl Curious or the Cribl Slack channel to share!






