

A recent survey showed that over a third of companies use more than thirty different data monitoring tools[1] for their observability data, spread across infrastructure and operations, DevOps, and SecOps teams. Each tool has deep awareness of its own narrow domain, but that source of truth doesn’t translate to neighboring areas or tools. Teams often introduce new data monitoring tools as a response to new architectures or changes in operations. This uncontrolled tool sprawl drives up costs and complexity, but it also leaves teams with a fragmented and confused monitoring environment.
To deal with this tool sprawl, many enterprises chase after a “single pane of glass” strategy, where a single tool offers all the capabilities various teams need. According to 451 Research, 83% of enterprise companies prefer buying as many monitoring tools as possible from a single vendor.[2] While this sounds like a great strategy, there are several reasons why a single-vendor strategy doesn’t work:
No tool exists that does everything your teams need, spanning application performance management, security operations, and infrastructure monitoring.
Deployment environments and infrastructure change faster than annual budget cycles can react, forcing teams into reactive, tactical tool acquisition outside the scope of annual or triennial contract negotiations.
Enterprises typically use between 2-3 public clouds, each with its own monitoring tooling and data sources. While it’s possible to have a third-party vendor in each of those clouds, that leads to…
Vendor lock-in. No CIO or CISO wants to be locked into a given vendor for multiple years. Things change too quickly and long-term agreements limit options going forward. Single-platform advantages around integration are outweighed by the need for enterprises to preserve their options as long as possible to react to changing markets.
A single pane of glass means centralization of control over, and access to, data. That centralization slows things down in increasingly distributed companies. The rigidity of a single source of truth at the destination is one of the factors that contributed to the growth of Shadow IT in the first place.
Despite the hype around a single pane of glass, the reality is enterprises will be living in a best-of-breed scenario for the foreseeable future. This is likely a controversial approach to managing observability data, but it reflects the reality most teams are coping with today and into the future.
Now that we’ve accepted that reality, we have to deal with it. We’re faced with two challenges, each pulling in opposite directions. First, we have multiple data monitoring and observability tools, each used by different teams and serving different outcomes. Those teams like the tools they’ve chosen. Getting rid of their preferred tooling can disrupt operations, impact SLOs, and make for a grumpy team.
The second challenge is reconciling how these disparate tools exist in the worlds they monitor and observe. Your log analytics platform will have a different view of the world than your APM platform, for example. Both views are correct in context, but both are also incomplete. Figure 1 illustrates the current state of many monitoring and observability environments. Each destination has its own source, and that source is locked into that destination.

This is where shifting the source of truth from the platform to the data becomes essential. By providing a central abstraction between the sources of data and their destinations, you can share data across platforms, creating a universal source of truth that exists upstream from the tools your teams know and love. Figure 2 illustrates what this concept looks like.
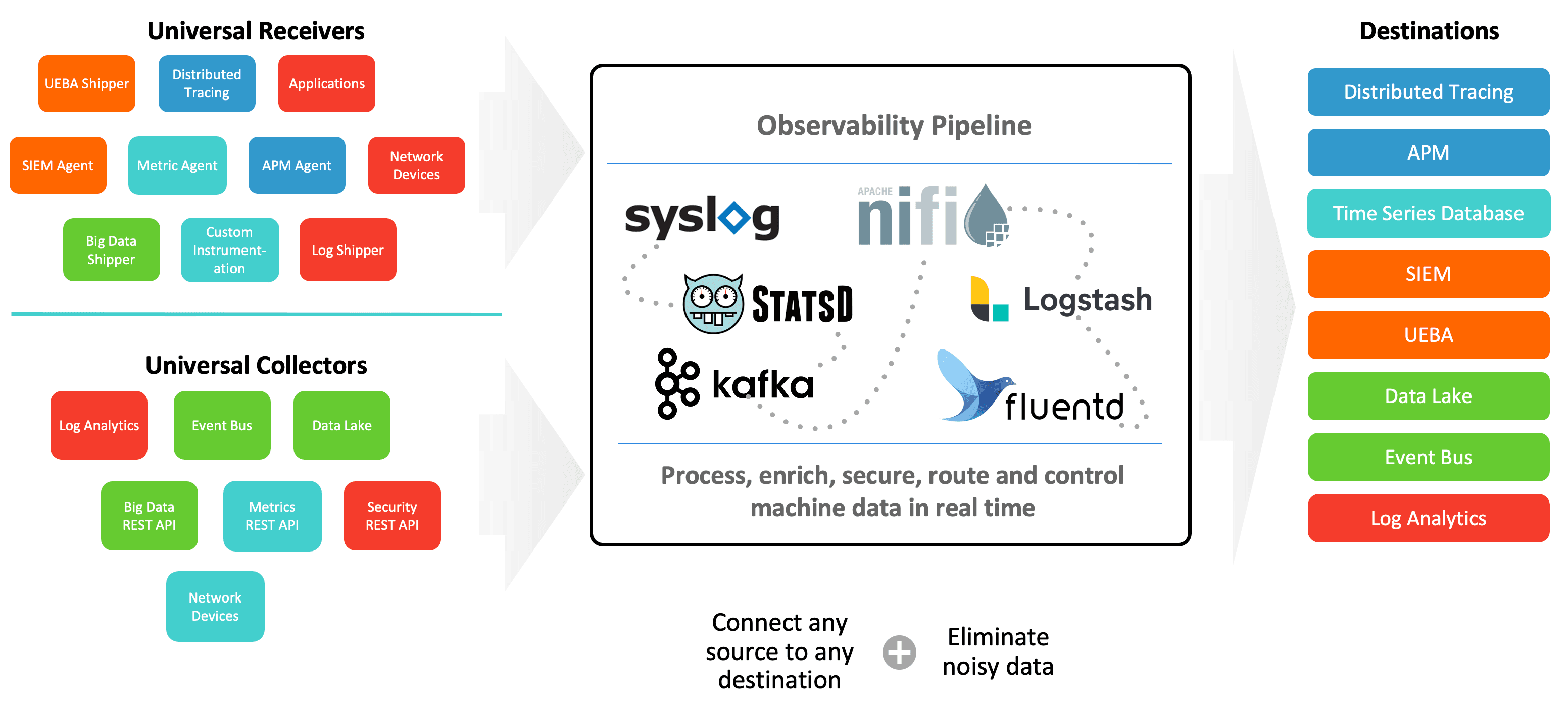
There are three advantages to using an observability pipeline as your source of truth:
Teams aren’t disrupted and continue using their preferred tools. If they later decide to add new tools, upgrade existing ones, or deprecate platforms, the observability pipeline insulates the rest of the environment from those changes. That keeps your options open longer.
The observability pipeline becomes a central, logical, point defining data routing, filtering, enrichment, and redaction, rather than spreading that across dozens of tools. This also means simplified maintenance, faster troubleshooting, and less duplication of work across teams.
Data sharing across tools is possible, giving teams access to more insight across complex environments. This strategy also allows you to separate your systems of analysis from systems of retention, applying relevant optimizations for each.
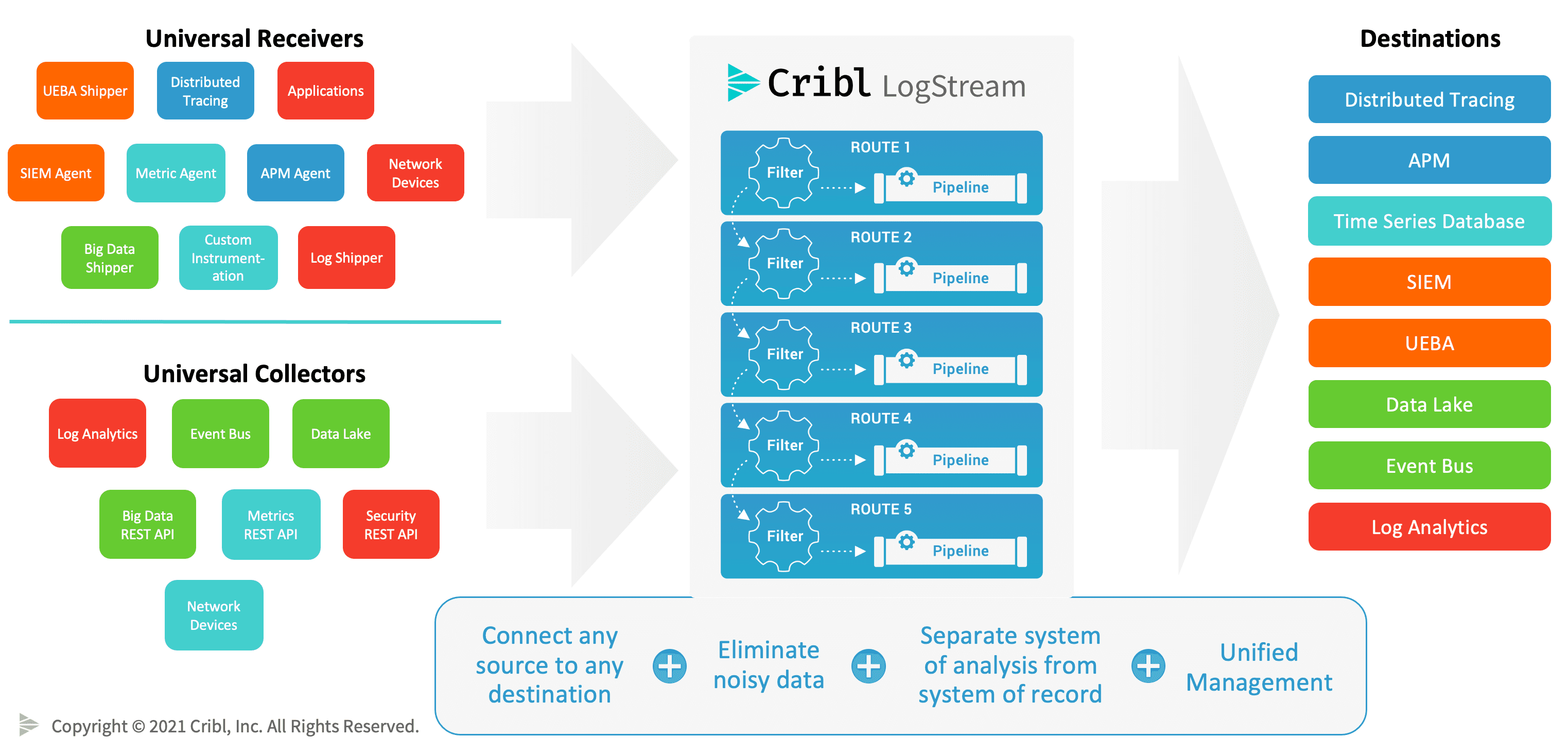
An observability pipeline, like Cribl LogStream, realizes each of these benefits (Figure 3).
Conclusion
In most circles, a single source of truth is envisioned as a large repository of data at rest that is continuously processed, normalized, and aligned with multiple enterprise systems. That can work when you’re making offline decisions on data, like the kinds of results you’d get from a data warehouse. It doesn’t work for observability data.
Observability data is orders of magnitude larger than business data in every enterprise, and it has orders of magnitude more data shapes and types of analysis. Observability requires fit-for-purpose data stores like time series databases (TSDBs), object stores for bulk log storage, and log indexing engines. Unlike in business intelligence circles, there are no successful companies building observability on top of data warehouses. The needs of observable systems are simply too diverse for one platform to manage. Introducing an observability pipeline, like Cribl LogStream, into your environment gives your teams the freedom to choose which tools they use and enables data sharing across those tools.
The good news is you don’t have to take my word for it. I encourage you to try out LogStream in our sandbox to see what shifting the source of truth can do for you and your enterprise. If you have questions, feel free to jump into our community.






