


Data is born at the edge, and the traditional approach is to collect it, then ingest it into one or more systems of analysis — or at least as much as you can afford to. And now the deep dive analysis begins. This might be the perfect solution for some datasets, but what about all the other data being collected on the edge? All the logs, metrics, and state information you seldom (if ever) retrieve? This data might be valuable but lacks the explicit value to justify the cost in time and money to retrieve and analyze it. How about taking a page from a maritime playbook using optical systems for reconnaissance, surveillance, and target identification? It all starts with Cribl Edge, a powerful and intelligent agent designed to manage data collection at scale.
Edge auto detects both OS and application telemetry, determines what portions are valuable or require additional processing, and then chooses whether to forward the data to Cribl Stream or other destinations. For example, debug logs– why move these voluminous files to an expensive analytics store if their value only lasts a very short period? Edge enables administrators to interact directly with the endpoints and explore and discover actionable data before deciding whether to move it. Additionally, Edge assists with agent consolidation efforts by providing robust centralized management for collecting, transforming, and forwarding data to various destinations, all while taking advantage of unused capacity on the endpoints.
Edge is even better in conjunction with Search. Cribl Search is an innovative new approach to finding and accessing data regardless of where it has landed and in what format. As users embrace tiered data strategies and the reality of multiple analytics and security tools, Search provides a federated solution built to separate the system of analysis from the system of retention. In this case, it allows you to search the node’s data via Edge.
Searching the Edge
Cribl Search has several Cribl Edge datasets built in, allowing you to search hosts quickly with Cribl Edge installed. Out-of-the-box Cribl Edge datasets include Edge logs, system logs, metrics, state information, application logs, and Appscope events and metrics. This includes comprehensive information about a node’s (hardware or virtual) processes, software, applications, and Kubernetes info. You can edit these built-in datasets or create new ones to specify other logs Edge can read anywhere in the filesystem. Once identified, you can shape and forward this data to Cribl Stream or destination(s) of choice.
Here are a few real-world scenarios where searching the edge would be invaluable:
Monitor Memory Usage: Are you concerned with memory usage across your network of Edge Nodes to identify potential issues? Just query the cribl_edge_metrics dataset, maybe with (node_memory_Used_percent). It calculates the average percentage of memory each host uses and identifies hosts consistently utilizing a high percentage of memory.
Detect Traffic Bursts: Want to identify high-traffic events across all Edge Nodes to detect potential issues and ensure optimal performance? Query the metrics dataset with
node_network_receive_bytes_all_total and node_network_transmit_bytes_all_total, then filter to hosts with >1 MB of traffic.
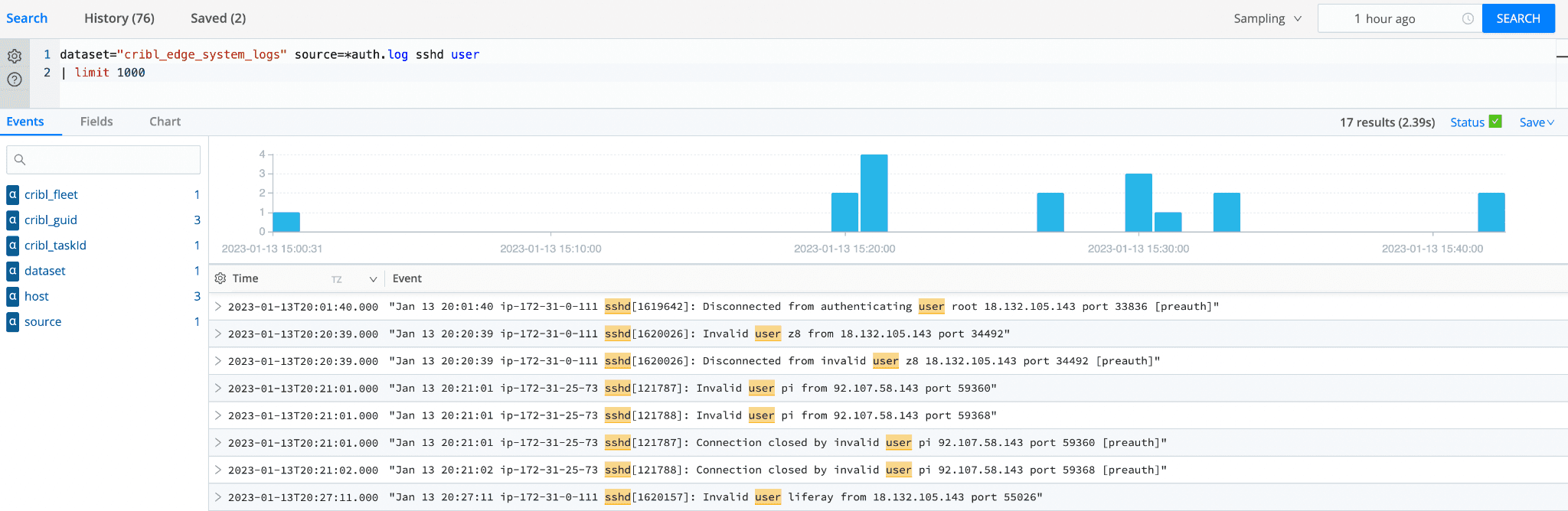
Checking SSH Login attempts: Do you suspect unauthorized SSH login attempts and want to examine the auth.log files for any suspicious activity across your entire network? Just query
system_logscontainingsshdand user in auth.log files and analyze all login attempts to detect unauthorized access.
Note: You don’t need to collect this data in advance, and you don’t have to move it, pre-process, or ETL it in any way! The search is executed in real-time, at rest, directly on the edge. But if you want to collect and/or shape this data, store it, or forward it to a system of analysis, append |send it to the query, and it will automatically forward it to Cribl Stream for additional processing.
Kubernetes Log Collection
Cribl Edge uses a DaemonSet approach, allowing it to launch on every node in the Kubernetes cluster, connecting directly to the Kubernetes API and collecting logs and metrics from all pods. Cribl Edge metrics also support disk spooling, enabling Cribl Search to query data collected. Cribl Edge provides a purpose-built-for-Kubernetes collector to receive batched data from Prometheus targets.
And if you discover anything of special interest, one click and Cribl ‘teleports’ you into that system. Here, you can explore the metrics and log data that the Node has auto-discovered and can always explore and manually discover other data of interest. You can use the discovered data to analyze the root cause, troubleshoot, and restart the host.
All of this only scratches the surface of what Cribl Edge and Cribl Search can accomplish!
Conclusion
Data volumes are huge and growing, but budgets are not. The percentage of data being analyzed will continue to drop due to the complexity and costs associated with having to ingest into the analysis system before knowing if there is any value. Cribl Edge and Cribl Search are game changers for ITOps, SecOps engineers, data observability enthusiasts, and really anyone who wants to know what’s happening at the edge without having to collect the data first. Cribl Edge simplifies the process of discovery and troubleshooting, while Cribl Search enhances your data search efficiency, irrespective of the location of your data. By leveraging Cribl Edge and Cribl Search, administrators can quickly view, monitor, and troubleshoot an instance’s health.
Check out our Solution Brief to learn more about Edge use cases.
Ready to go deeper?
Data is born on the network edge, and the traditional approach is to collect, route, and ingest, and only then does the deep dive analysis begin. Now, in some cases, this might be the perfect solution, but for the enormous volumes of data you cannot ingest, might there be another option? This blog discusses how you can know what’s happening at the edge without collecting the data first. Check out this training session from myself and Sri Kotikelapudi, Director, Product Management of Cribl. Watch now.





