
Organizations with AWS footprint have many options to get data in to their log and event management platforms. So did we. Up until recently we were using a pull based solution supplied from one of our vendors. Data collection worked, until it didn’t and we were starting to run into problems:
We had to operate an instance to pull the data with. This added to our overall infrastructure and most importantly to our ops & maintenance cost. Ain’t nobody got time for yet another server in 2018!
Scaling out was starting to become an issue as the solution was not distributed or clustered. No clustering also means cursoring, resiliency and failover have to provided by external means or custom built. Some would say about scaling “That’s a good problem to have” but now that we have it, now what?
The solution offered very little data controlling capabilities. We needed volume control, data shaping, masking, filtering, enriching, sampling and routing capabilities to meet our business and technology requirements.
CloudWatch Logs was getting pretty expensive, at $0.5/GB ingested, for the latencies and the querying & controlling capabilities, or lack thereof rather, that it offers. (We’ll probably do a full blog post about our findings here)
Is there greener grass somewhere else?
We started searching for other options. We went on to explore and analyze alternative data collection solutions and a few patterns emerged:
They are typically either push or pull based. We’re trying to stay away from pull-based ones because of the problems laid out in 1) above.
Some are vendor supported and some open source. For the most part they’re both fine with us as long as they don’t have any of the issues above.
Some were simple or cost-effective some weren’t. Some required long running instances and we’re looking to minimize the cost of maintenance over time.
Nearly all of them provided very light capabilities with respect to controlling data.
F*ck it, we’ll do it live!
It was clear that most solutions were not going to check all the boxes for us – they were sub-optimal in a few fronts. They either lacked controls or were too complex or not cost-effective enough or some combination thereof. So, after we added support for HTTP inputs with our v1.1 release, we decided to implement our own solution based on AWS Lambda and Cribl to collect these sources from S3 driven S3 Event Notifications:
Amazon CloudFront Access Logs – used to track access to our public web assets.
AWS CloudTrail Logs – used to track AWS account/API activity.
Amazon VPC Flow Logs – captures network flow metadata in/out of our VPCs.
Elastic Load Balancing Access Logs – capture request information to our LBs

With AWS Lambda we get:
The simplicity that we’re looking for. No instances to operate and maintain.
The effectiveness of an event-driven solution. Runs only when needed.
And the auto scaling capabilities that we need. Supports spikes/bursts just fine.
Cribl LogStream provides for:
Data masking and volume control capabilities to meet our business needs.
Sensitive data is obfuscated and high noise sources are trimmed down to acceptable levels.
Data shaping, enriching, and routing capabilities to meet our technology needs.
Some of the events are custom-shaped, converted into metrics and some are routed to required destinations.
If you’d like to see how we did it, please read on.
For the impatient: GitHub repos with the Lambda function, or the Cribl S3 Collector Serverless App alternative, and Cribl pipeline configurations that we built and use to normalize, filter and sample our AWS events.
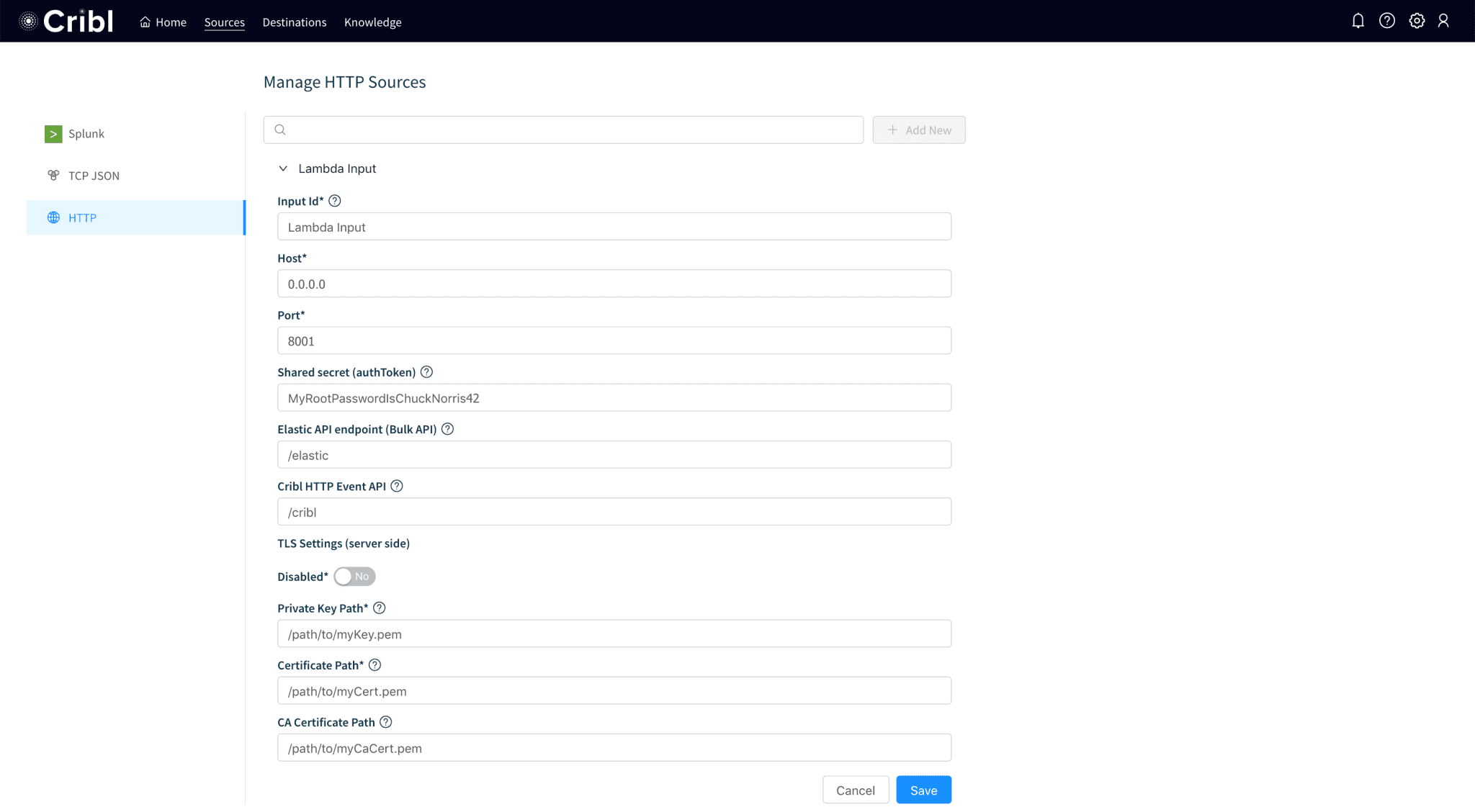
Step 1. Configure Cribl to receive events over HTTPS
We configured our deployment to accept events over HTTPS using the Cribl Event API.
While in Cribl, click Sources from the top menu and select HTTP on the left.
Enter an Input name and set Host to
0.0.0.0(i.e. listen on all interfaces)Supply a Port number that the firewalls allow inbound traffic.
Enter a Shared secret string. This will be the authentication token that Lambda will use via its
CRIBL_AUTHenvironment variable (see below).Toggle TLS Settings and fill in the fields as required. Save!
Step 2. Configuring the Lambda function
How does it work: The Lambda function, available on GitHub, or as a Serverless App, will first get invoked by S3 Event Notifications. Next, it check the objects passed by S3 against patterns that match the following supported services logs: CloudTrail, VPC Flowlogs, CloudFront Access Log and ELB/ALB Access Logs. CloudTrail events are in JSON format and will be handled as is. For the rest, fields will be extracted given the information present in the file header, or via a list manually. Event will then be sent to Cribl. As you notice very light processing is done in Lambda. The goal is to get the events as fast and as efficiently as possible and express a more thorough processing logic in Cribl instead.

Option A: Deploying the function from scratch:
Get the Lambda function. It’s open source under an MIT license.
In your AWS Lambda console create a function via Author from scratch
Give it a name and select Node.js 8.10 as your runtime
Next, select an IAM Role with read permissions on S3 Buckets from which this function will receive events.
Copy the function code inline into the Editor.
Allocate 256MB of RAM and a Timeout of 10s.
Option B: Deploying the function as a serverless app:
In your AWS Lambda console create a function via AWS Serverless App Repo
Or, click here to get started.
Search for
cribland select Cribl-S3-Log-Collector. Proceed as instructed.Select an IAM Role with read permissions on S3 Buckets from which this function will receive events.
In both cases, there are two environment variables that you’ll need to supply:
CRIBL_URL: This is the receiving endpoint where the function will deliver events and it should look like this:https://<host>:<port>/cribl/_bulkCRIBL_AUTH: this defines the token string that Lambda will use to authenticate against Cribl receiving endpoint above.

Configuring S3 to trigger Lambda:
In your S3 Console, go the bucket(s) where your logs are stored.
Note that triggers can also be configured in Designer section in Lambda, too.
Select the Properties tab and locate Events under Advanced settings
Click on Events, then click on + Add Notification.
Enter a name and select All objects create events under Events
Enter a prefix that indicates the location of the logs of interest in this bucket.
Select Lambda Function under Send to.
In dropdown find and select the Lambda function from above. Save!
Repeat this for each log type/prefix.

After configuring S3 Events the Lambda function screen looks like this. Note the S3 trigger box on the left hand-side.

3. Configuring Cribl Pipelines
Once you have Lambda sending data into Cribl, proceed to install and configure the pipelines.
Get them on our GitHub repo.
Go to Pipelines and click on + Add Pipeline. Click on Advanced Mode.
Select Import to import a pipeline or paste its JSON config. Change name as necessary.
Select a Destination from the top right. Save!
Before you associate pipelines with Routes, please check their functions and change them to meet your needs.
Let’s take a look at one of the pipelines: VPC FLOW LOGS
VPC flows are extremely voluminous but we all want to eat the cake and have it, too 🙂. We wanted to keep all the data but we wanted to be selective with what we ingested. We also want day to day querying to be as fast as possible. This pipeline allows us to keep all data in S3 and ingest ~60% less of the total events resulting in very significant storage savings and incredible search speed improvements via |tstats.
Function #1 (Eval) sets a sourcetype and index. This is used in our downstream system (Splunk) for searching, tagging/eventtyping and access control.
Function #2 (Sampling) samples
ACCEPTevents at a 5:1 ratio. These are the events that contribute to the majority of the volume.Function #3 (Comment) comment function.
Function #4 (Eval) normalizes field names by mapping native field names, extracted in Lambda, to Splunk Common Information Model name.
Function #5 function (Eval) remove VPC Flowlogs native fields names and leaves event/_raw intact.
Using last two Eval functions:
To send to Splunk as-is (as delivered by Lambda), disable both Function #4 and #5 Evals.
To send to Splunk with index-time CIM fields, enable Function #4 Eval and disable Function #5. Index-time CIM fields allow for fast
|tstatsquerying.To send to Splunk only raw events and extract search-time CIM fields, disable Function #4 Eval and enable theFunction #6 .
Note: you can add more functions to this pipeline. E.g., you can Filter/Drop out events from certain IPs (e.g., known chatty IPs), or Sample on protocol numbers, or port numbers for even greater storage savings and performance improvements.
Done!
Using Cribl with Lambda is an effective and scalable way to effortlessly collect and process AWS logs. Please check us out at Cribl.io and get started with your deployment.
If you’d like more details on installation or configuration, see our documentation or join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to help you!
Enjoy it! — The Cribl Team






