
The Problem
It’s not uncommon for machine data systems to send and receive duplicate or repeated events. This could be due to a variety of reasons, for example;
Misconfiguration (a.k.a layer-8 problems) on the source, intermediary or aggregation systems may cause duplicate data to be sent out.
Bugs or software defects may cause a data source to occasionally (or worse, frequently) send duplicates.
Unreliable networks or connectivity issues may force sources to resend data.
Using certain protocols (e.g., UDP) may also cause out of order events or duplicates.
Repeated, low value events that indicate fast cycles or loops (e.g., network device interfaces flapping rapidly).
The functional impact of duplicates will depend on the situation and use cases being served by the system. For instance, a relatively low number of dupes may be insignificant when the system is mostly used by humans for troubleshooting. On the other hand, a large number of dupes can throw off security & operational analytics. Especially when they depend on summarization and/or statistical aggregations.
From a system perspective, a large number of dupes can impose a significant stress on performance and storage. Searches, queries, dashboard views etc. all will be impacted due to the added number of events to sift through. This can and will affect end-user experience. Storage will also be consumed faster. Which means higher value data will likely be unnecessarily/prematurely aged out.
Solution
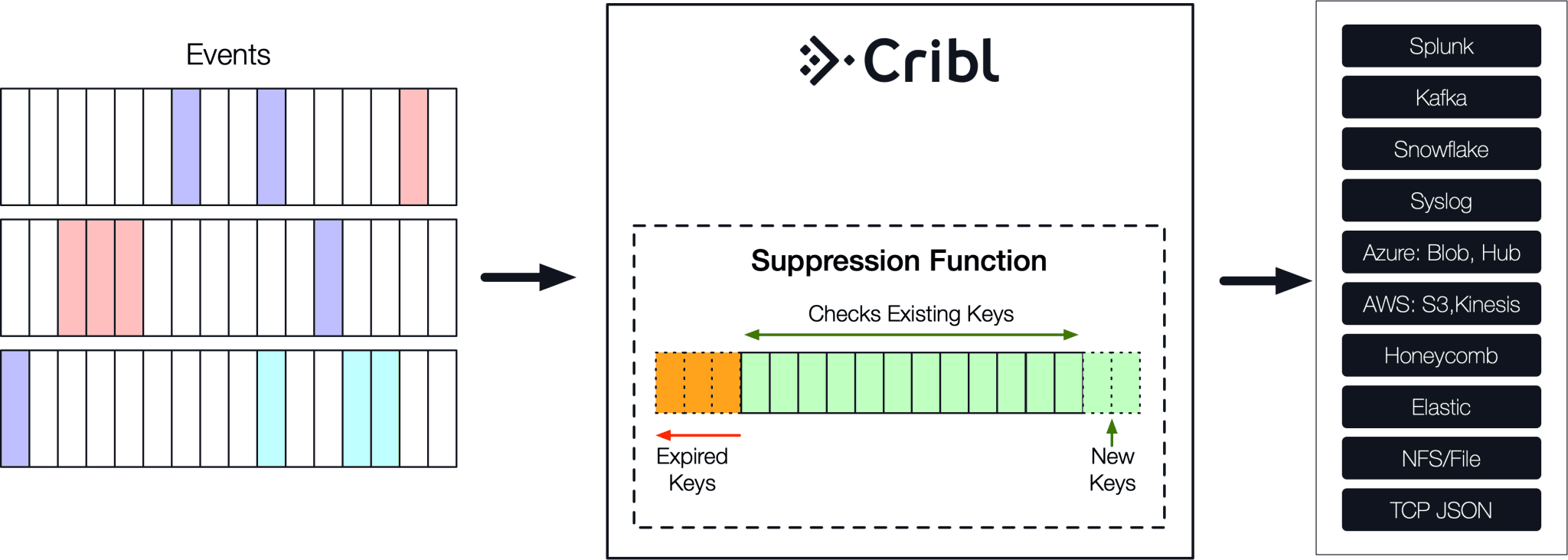
It is clear that when dupes occur it becomes necessary to eliminate them. Cribl puts the machine data administrator in control of the flow and provides functionality to reduce dupes inline before forwarding to a downstream receiver.
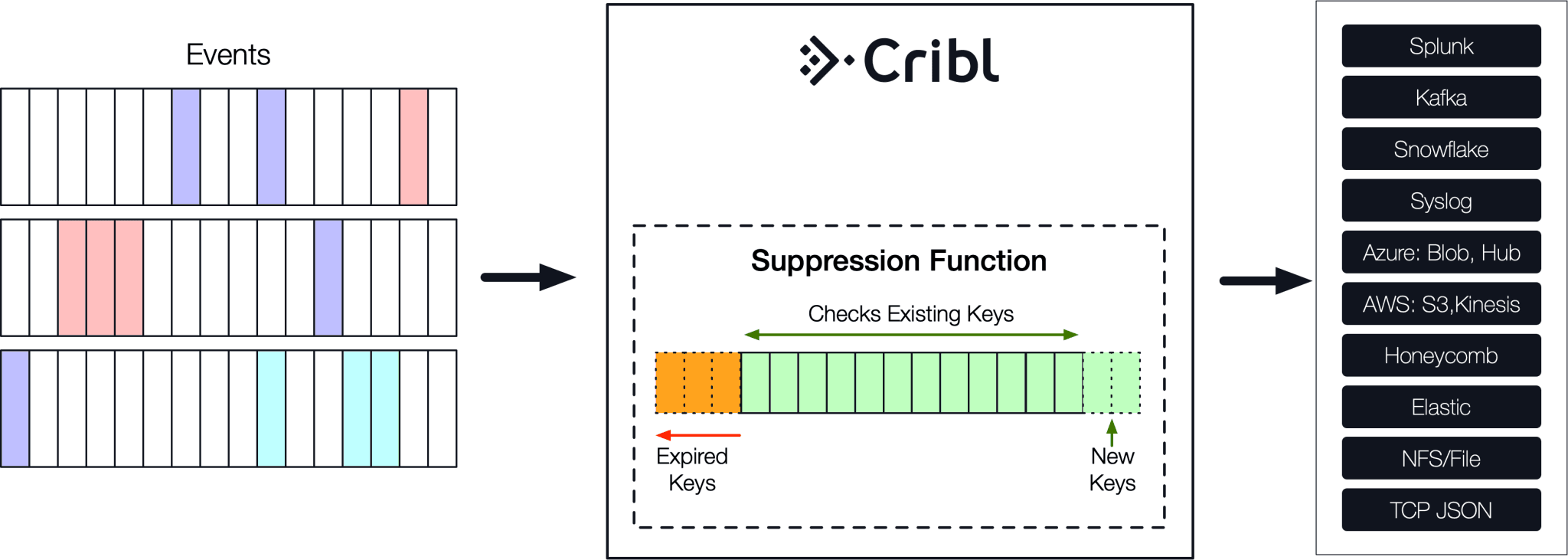
The Suppress function plays a central role here. The way it works is the following: First, users define a key expression to uniquely identify events in a stream. Next, the function checks if that key has been seen before. If yes, the event is dropped. Else, it is allowed through. In pseudo-code:
for each event e:
if haveWeSeenThis(e.key):
drop(e)
else:
letItThru(e)Data deduplication keys are not stored for all time. Instead, they work on a user defined time window. As the window moves forward in time, new keys are inserted and older ones are expired.
The key expression allows the administrator to surgically articulate how to uniquely identify events. This can be as coarse as the entire event content or as fine as a very specific combination of event’s fields.
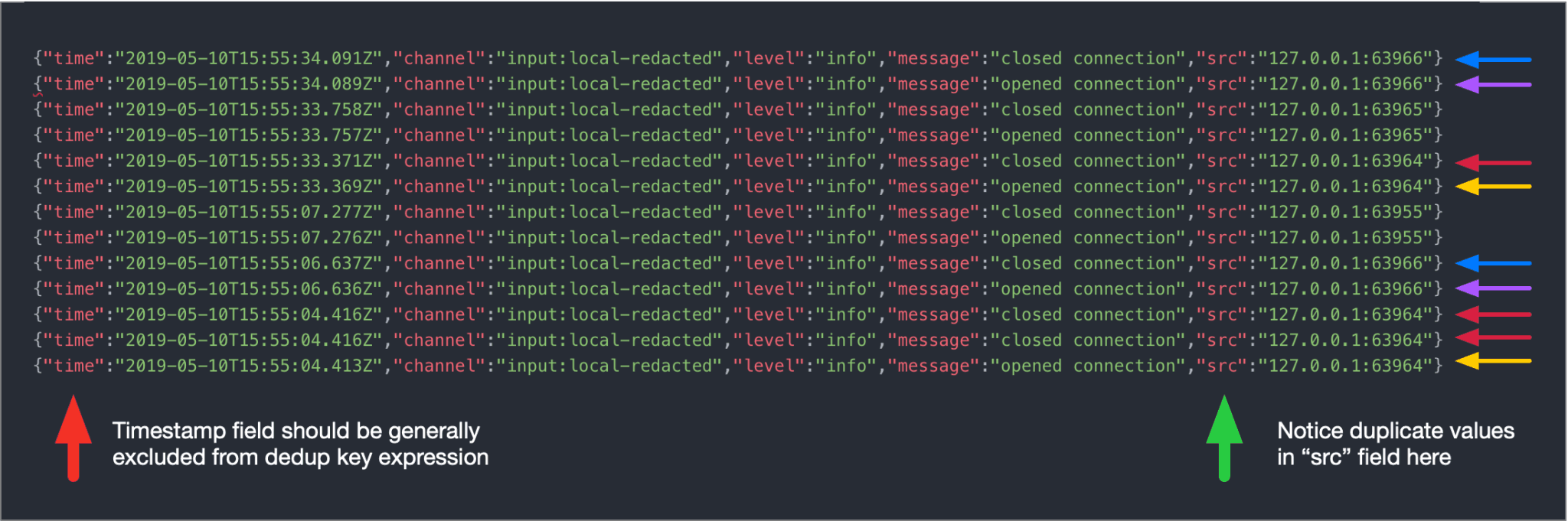
The nuanced benefit that the key expression brings about is critical. For instance, in the sample above, even though some events look identical you can’t actually deduplicate them based on their full content because time is different in each one. In fact, given the nature of the timestamp field (i.e. typically monotonically increasing) it should be excluded from all your deduplication efforts. For this particular source here we can construct a key expression that targets only relevant fields for a more precise basis for deduplication. For example, this expression will compose a key using the values of channel, message and src fields:
`${channel}:${message}:${src}`Suppress Function
The Suppress function offers a few configuration options that can be tuned to precise customer data deduplication requirements. Let’s take a look.

Key Expression: This is used to build a key to uniquely identify events to suppress. For example in our case:`${channel}:${message}:${src}`Number to Allow: Number of events to allow per window. Typically this will be 1.Suppression Period: This is the time window, in seconds, to suppress events after ‘Number to Allow’ events are received. It is recommended to keep this down to a reasonable number, say, less than 60s or so. The greater this number the larger the corpus of keys to store and compare against.Drop Suppressed Events: This control can be used to indicate if suppressed events should be dropped or just decorated with suppress=1. This is useful when other functions down the pipeline need to be invoked on duplicate events or to assist downstream systems if they are to remove duplicates.
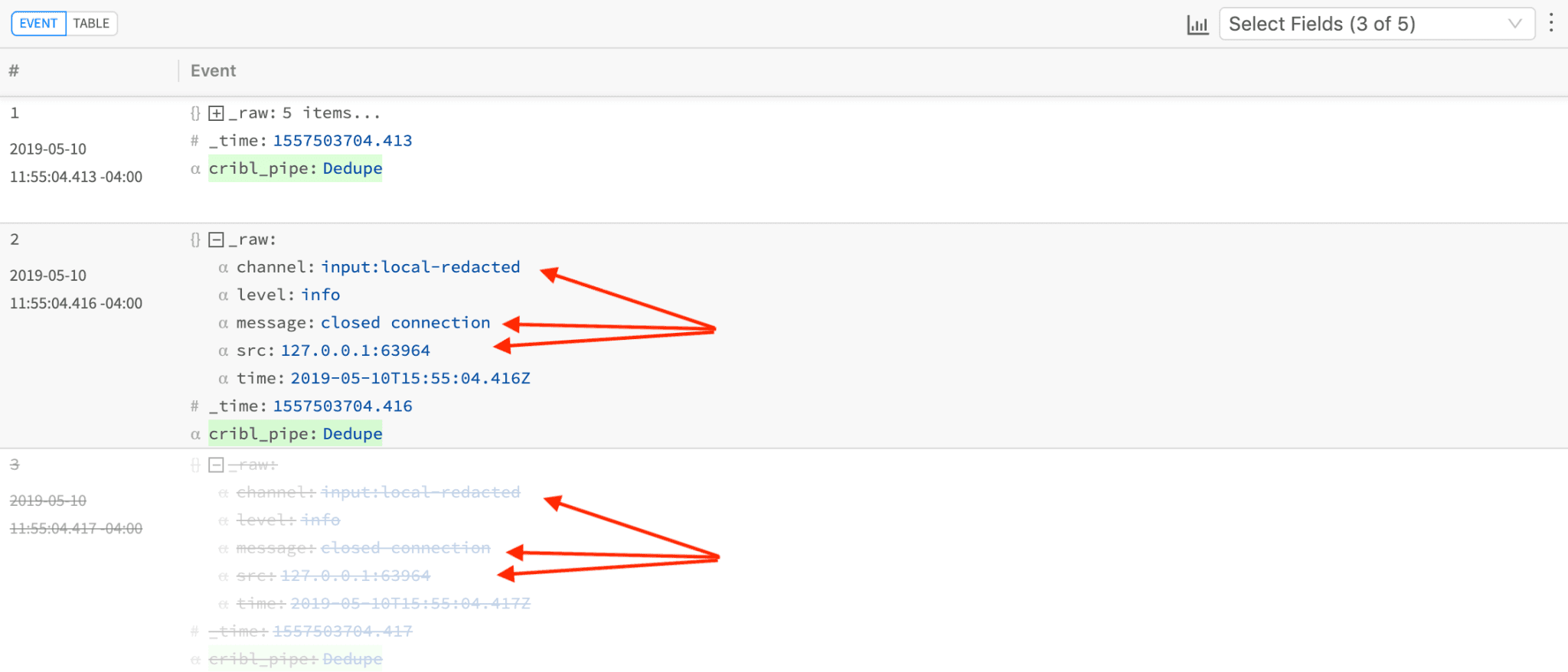
Notice how in this sample events #2 and #3 have the same key (see expression above) and #3 has been dropped as indicated by strikethrough/greyed-out styling.
Indicating the number of events dropped is always done in context. I.e. no more of those loose, separate “Last message repeated N times” events. The next event that is qualified to be allowed through will be decorated with suppressCount=N where N represents the number of events dropped in the previous time window.

Depending on the key expression the number of identified duplicate or repeated events can be quite significant.

Many Possibilities
Removing or minimizing duplicates results in a better experience across the board; the analytics/end system performance will increase, fewer CPU/Storage resources will be wasted and overall user experience will improve. Cribl makes the process of dealing with duplicates in real-time easy. Powerful articulation of key expressions allows for custom and fine-grained targeting of repeated patterns. Give it a try today!
—
If you’d like more details on configuration, see our documentation or join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to help you!
Enjoy it! — The Cribl Team






