

Enterprises have enough data, in fact, they are overwhelmed with it, but finding the nuggets of value amongst the data ‘noise’ is not all that simple. It is bucket’d, blob’d, and bestrewn across the enterprise infrastructure in clouds, filesystems, and hosts machines. It’s logs, metrics, traces, config files, and more, but as Jimmy Buffett says, “we’ve all got ’em, we all want ’em, but what do we do with ’em”. Sad, but true, is in many cases, nothing.
The Observability industry and its tooling have evolved to a point where we are now able to collect more data than we can effectively analyze, with some enterprises reporting utilizing less than 2% of collected data. The other 98% typically gets routed directly to storage to review later, but in reality, this data is deteriorating in value as it sits. Its ability to answer critical security, performance, and system state questions quickly fades.
A key reason for this is that today’s IT architectures allow data to live anywhere, and as a result, it’s distributed across platforms and becomes too complex and/or too costly for teams to integrate all the data. And trying to search it all using legacy analysis tools is a struggle, if not impossible due to silos — data in different locations, on different systems, and in different formats. A better solution is needed.
Cribl Search is that solution– it compliments your existing systems with a new “search-in-place” capability, allowing administrators to search data where it sits, with no movement required. The primary use case we see at Cribl is providing visibility into the huge volumes of collected data, typically dumped into Amazon S3 buckets or the like.
How It Works
It all starts with the data; as mentioned in many cases it is already stored in one or more S3 buckets, this is often the overflow of what didn’t fit within the ingest license. You know there are probably some good nuggets of information in there, you just need a simple, cost-effective way of getting eyes on it. So, let’s start there.
Start by defining a dataset in Cribl Search — this is the data you want to take a look at, first give it a name, maybe something like ‘SIEM data”, then identify the AWS bucket name and finally the authentication information. On that note, we strongly recommend using the AWS Assume Role option, then start the search and you’re off and running.
It is really as easy as that and should take you less than 5 minutes to launch your first Search. I did it in 2, see if you can beat me. Oh, by the way, if you forget a step or two, no worries as we have a built-in wizard to help you along. By default, the search will look for everything so you will need to prune it down a little, and with a few simple filters, you can focus your search. Maybe you’re looking for an IP address, hostname, location, time range, data type, or just a term… starting to get the picture? It gets even better once you have defined your search and validated the results returned. You can then simply append the operator ‘Send’ to your query and send the results anywhere using a regular HTTP Source URL.
Even better, by default the Send operator forwards the results to your Stream Cribl HTTP Source. Now with the data going to Stream you can clean it up, shape it, enrich it, and then forward it onto an existing system of analysis or even back into a new S3 bucket(s). Partitioned out with a structure to handle different types of data, this will greatly simplify managing and retrieval for future use.
The overall approach is to route the output from Cribl Stream back into an S3 or compatible storage location. The output may just be the raw data from one or more sources, being saved just to meet compliance requirements, other data may be processed (filtered) based on any specific requirements. The data is then routed into separate partitions in your bucket(s), as shown in the graphic below, simplifying any future investigations.
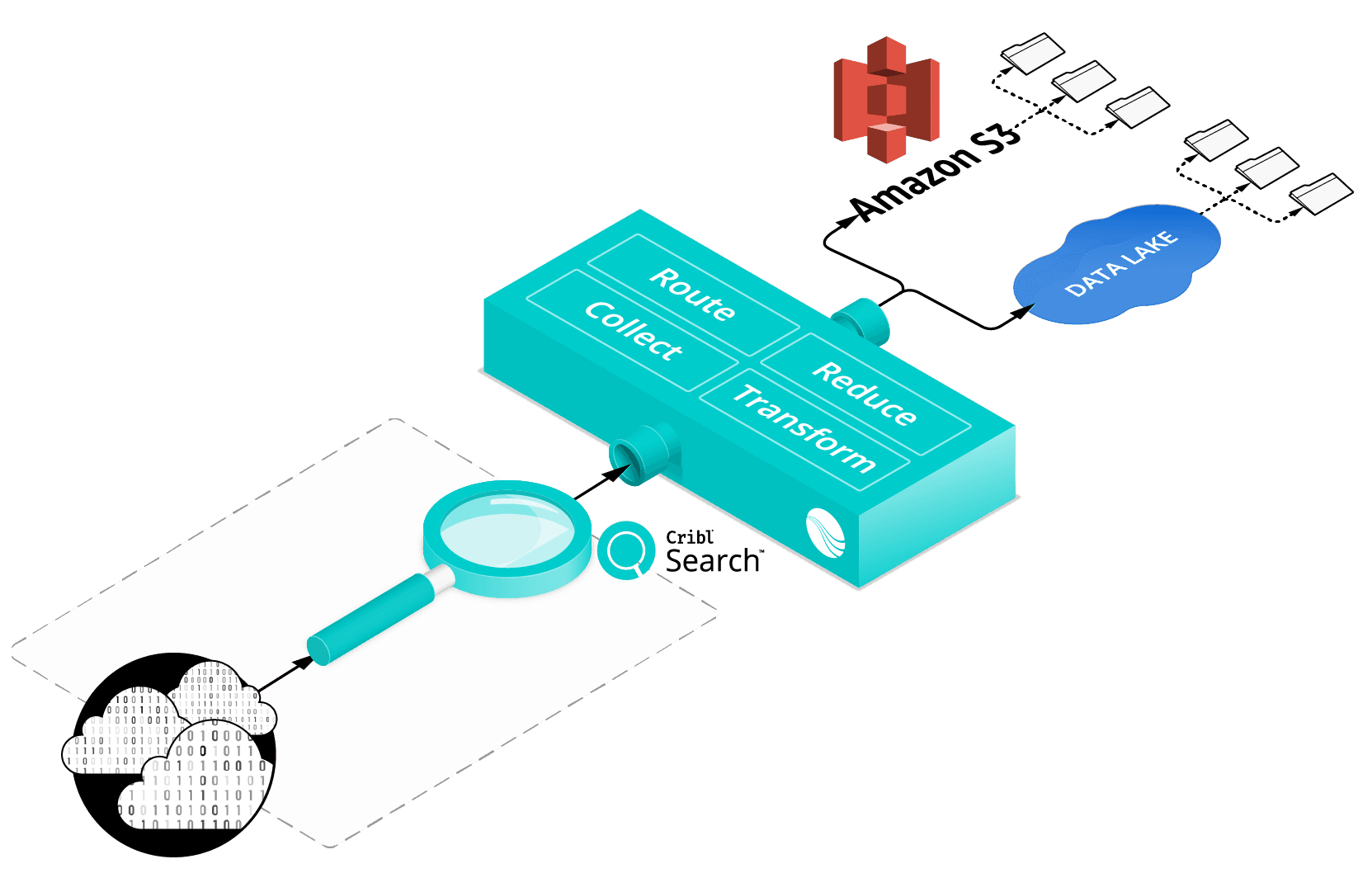
Diving a little deeper, we searched our data ‘dumpster’, shaped and segregated the data, and created separate partitions for the following sets of data:
A Forensic Bucket – All data, still in raw format, will be maintained for compliance.
Data Lake – similar to above, but all data is saved in NDJSON format for ease of access.
Restricted Data Lake – similar to above but with corporate restricted access rights.
Sensitive Data – access is restricted due to HIPAA / PII / GDPR rules.
Specific Data- unique filters, maybe based on sources or even potential value of data.
Tagged Datasets – data assigned ‘tags’ (for any reason) as it transits’ the pipeline.
Time-managed Datasets – 365 days retention / 18 months / 7 years / xx years.
Really, almost any unique category/grouping is required!
Ok, but what about data not already in an S3 (or compatible bucket)? It’s still reachable, searchable, and actionable. Taking advantage of Cribl’s suite of products, Stream, Edge, and Search, you can reach into any stored data you have access to. In some cases, you can search it directly as referenced above, in other cases, you can leverage our Cribl Stream Observability pipeline to collect, shape, and then route the data to the bucket of your choice. So, no matter the starting or ending locations, Cribl Search has the solution to your data overload problem.
In either case, the result is the ability to create collections of specific datasets from huge volumes of data, then segregate them based on specific organizational, departmental, and security requirements. The segregated data streams are then routed to specific partitions within your object store. Ultimately eliminating the costs of dumping all raw data into multiple systems of analysis.
Final Thoughts
Data volumes are huge and growing, budgets are not. The result is the percentage of data actually being analyzed will continue to drop due to licensing costs. There are only two options to address this issue: get a bigger budget or be smarter about how data is processed prior to ingesting into a system of analysis:
A separate system of analysis from the system of retention
Store raw data in low-cost data stores, not in expensive analysis systems
Query data in-place (data stores), to identify only relevant data (wheat from chaff)
Forward just the relevant data to the system of analysis (lower the ingest license)
Use Cribl Search to front-end and complement your existing analysis tooling
Test drive Cribl Search today, FREE on Cribl.Cloud!
For more information, visit our Search page.
If you want to keep track of what’s coming next, make sure to follow Cribl on LinkedIn, Twitter, or via our Slack Community.






