
The author of a log has very different motivations from the consumer of that same log. For the author, they must conceive of all the use cases this data may be useful for and include information which will be relevant both now and in the future. The author must ask a number of important questions to build the most relevant log possible:
Is this log going to be used for operations, security or both?
Should we be selective about what to log or simply serialize this whole object in memory?
Are there future use cases I should plan for now and go ahead and include more data?
Should I make it more machine or human friendly to read?
The end result is often logs which are least common denominator: work for 0ps and security, including all potential information for now and for any use cases the author may have considered for the future. Vendors are often in the worst position for this. Who knows what customers may want 2 or 3 years down the road, and changing formats is expensive, so best to include everything up front. Cisco eStreamer for example has 94 fields in every log entry.
As the consumer of log data, often only a fraction of the information is relevant for your given use case. You may only be interested in security data while the performance information is irrelevant for you, or vice versa. Fields your developers wrote out may be of interest only to them and not for your operational use case. Fixing overly verbose events has historically required going back to the developer to ask them to log less, or in the case of vendor data, just ingesting it and being forced to live with it. Cribl puts the log administrator in control to give you the ability to easily reshape data to meet your needs.
In this post, we’ll show how to use Cribl’s Parser function’s Reserialize mode to easily read structured data and write it back with less information to minimize ingestion volume and avoid storage and processing costs.
That’s a lot of JSON!
In today’s world, the most common example of over verbosity is with structured, JSON logs. JSON logging provides us a huge advantage in that we no longer have to guess at how to parse our log entries. It makes it easy for developers to write, as nearly all languages have the equivalent of JavaScript’s JSON.stringify(). However, because serializing objects to JSON is so easy, developers tend to do little reshaping or trimming before that call to JSON.stringify(), leading to overly verbose logs. Here’s an example of a log entry I pulled at random from a log in S3 in our account, which was originally used in an open source application we were running:
{
"resource": "/done",
"path": "/done",
"httpMethod": "POST",
"headers": {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"CloudFront-Forwarded-Proto": "https",
"CloudFront-Is-Desktop-Viewer": "true",
"CloudFront-Is-Mobile-Viewer": "false",
"CloudFront-Is-SmartTV-Viewer": "false",
"CloudFront-Is-Tablet-Viewer": "false",
"CloudFront-Viewer-Country": "US",
"content-type": "application/json",
"Host": "jef18742ajw.execute-api.us-west-2.amazonaws.com",
"origin": "https://cdn.foo.com",
"Referer": "https://cdn.foo.com/bugger/index.html",
"User-Agent": "Mozilla/5.0 (Linux; U; Android 2.3.5; zh-cn; MI-ONE Plus Build/GINGERBREAD) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Via": "2.0 nb7CCG2p7MZ5igcMI58VkqWRlxUQTrCap.cloudfront.net (CloudFront)",
"X-Amz-Cf-Id": "pV3t3VVKegwwv5sRvVrfX9UgHsXiC9weFGmKSOOkWUCbUE9gbHepDjoV",
"X-Amzn-Trace-Id": "Root=aD2sYM7atV811DKgTMxMmp6UZuZg7sky3v",
"X-Forwarded-For": "130.253.37.97",
"X-Forwarded-Port": "443",
"X-Forwarded-Proto": "https"
},
"multiValueHeaders": {
"Accept": [
"application/json, text/javascript, */*; q=0.01"
],
"Accept-Encoding": [
"gzip, deflate, br"
],
"Accept-Language": [
"en-US,en;q=0.9"
],
"CloudFront-Forwarded-Proto": [
"https"
],
"CloudFront-Is-Desktop-Viewer": [
"true"
],
"CloudFront-Is-Mobile-Viewer": [
"false"
],
"CloudFront-Is-SmartTV-Viewer": [
"false"
],
"CloudFront-Is-Tablet-Viewer": [
"false"
],
"CloudFront-Viewer-Country": [
"US"
],
"content-type": [
"application/json"
],
"Host": [
"jef18742ajw.execute-api.us-west-2.amazonaws.com"
],
"origin": [
"https://cdn.foo.com"
],
"Referer": [
"https://cdn.foo.com/bugger/index.html"
],
"User-Agent": [
"Mozilla/5.0 (Linux; U; Android 2.3.5; zh-cn; MI-ONE Plus Build/GINGERBREAD) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"
],
"Via": [
"2.0 4H2N7SZPy76JchKSA42VLdO0Go5deev92.cloudfront.net (CloudFront)"
],
"X-Amz-Cf-Id": [
"biqnKVhl5vIsanuR3M2tGYfXbWoA34ZGcKsX34eBFbGGF2tMHZLolR9c"
],
"X-Amzn-Trace-Id": [
"Root=uwdK8lRoaEFFo1FZmzIBQJn1dKYbFvB9uW"
],
"X-Forwarded-For": [
"130.253.37.97"
],
"X-Forwarded-Port": [
"443"
],
"X-Forwarded-Proto": [
"https"
]
},
"queryStringParameters": null,
"multiValueQueryStringParameters": null,
"pathParameters": null,
"stageVariables": null,
"requestContext": {
"resourceId": "mwPK97",
"resourcePath": "/done",
"httpMethod": "POST",
"extendedRequestId": "uoYMpT7pQeiwpMTj",
"requestTime": "22/Apr/2019:15:02:56 +0000",
"path": "/prod/done",
"accountId": "718298359019",
"protocol": "HTTP/1.1",
"stage": "prod",
"domainPrefix": "jef18742ajw",
"requestTimeEpoch": 1555970576,
"requestId": "3070f015-8f93-4bc0-a06a-89ab501b0178",
"identity": {
"cognitoIdentityPoolId": null,
"accountId": null,
"cognitoIdentityId": null,
"caller": null,
"sourceIp": "130.253.37.97",
"accessKey": null,
"cognitoAuthenticationType": null,
"cognitoAuthenticationProvider": null,
"userArn": null,
"userAgent": "Mozilla/5.0 (Linux; U; Android 2.3.5; zh-cn; MI-ONE Plus Build/GINGERBREAD) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"user": null
},
"domainName": "jef18742ajw.execute-api.us-west-2.amazonaws.com",
"apiId": "jef18742ajw"
},
"body": "{\"done\":\"true\"}",
"isBase64Encoded": false
}This is far from the biggest JSON log message we see in the wild. In fact, I’d say this is about average. This log message was not engineered to show verbosity, it’s just a normal message you’ll find just about anywhere. If you look through the whole of the message, you’ll see a number of areas where we can optimize:
Headers are repeated as
headers, an object, andmultiValueHeaders, an object filled with arrays.There are numerous values set to
null.Some fields are mutually exclusive, like the
CloudFront-Is-*headers of which only one can be true.
All of these above can easily be solved with Splunk’s fillnull command or the equivalent in other systems. If the value is present in any event, you can fill null values back with null or false or other values. Let’s see how to to configure Cribl to drop these unnecessary keys.
Reserializing FTW
In 1.4, we added a new Parser function which has a mode called Reserialize. What Reserialize does is to take structured information like CSV, JSON, or other structured formations and allow us to modify the contents of that data while keeping the structure. For example, in CSV, if we wanted to drop a field, we would keep the header row and the positions the same while setting the value to be empty. For JSON, we can drop key and value pairs.
For this use case, let’s use Parser to drop the duplicate header field and drop fields which are set to null or false. Here’s an example of the Parser function fully configured. We’ll walk through the configuration in detail:
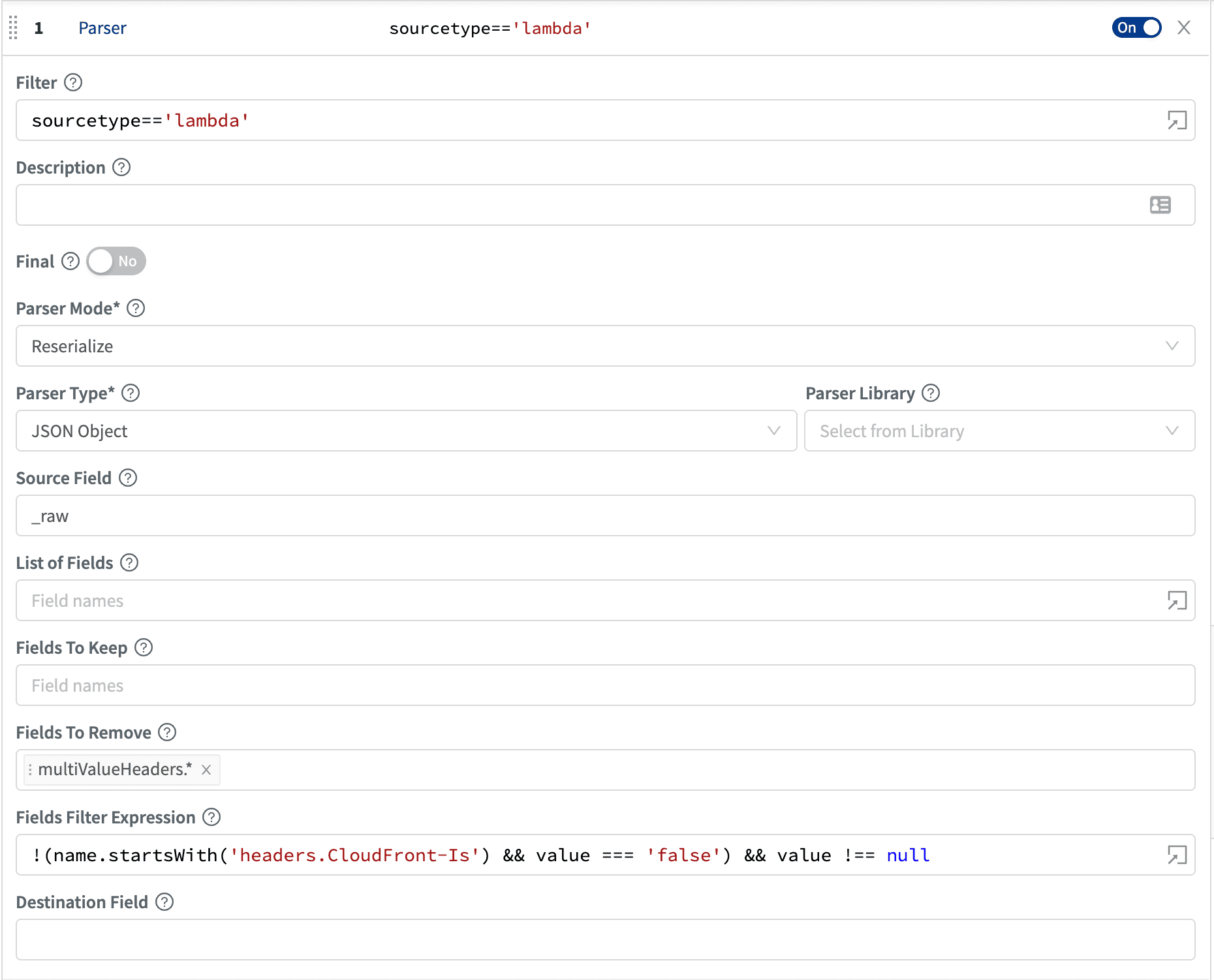
For the Filter, we’re filtering to just records with sourcetype=='lambda'. For Parser Mode, we’ve set it to Reserialize. For Fields To Remove, we’ve set it to multiValueHeaders.*. Note, we support a dotted notation for nested fields, and .* drops everything under the multiValueHeaders object.
The next configuration, Fields Filter Expression is a bit more complex. From the docs:
Fields Filter Expression: Expression evaluated against {index, name, value} context of each field. Return truthy to keep, falsy to remove field. Index is zero based.
What we want our expression to do is to drop every field where the value is null or false if the field name is starts with CloudFront-Is. For the expression, we want to return truthy for all fields we want to keep, so we want to return value only for those conditions mentioned above. For the full expression we’ve written:
!(name.startsWith('headers.CloudFront-Is') && value === 'false') && value !== nullThis will return truthy when the value is not null and when the value is not false and the name starts with CloudFront-Is. With Cribl’s interactive preview, it’s easy to see if we got this right:

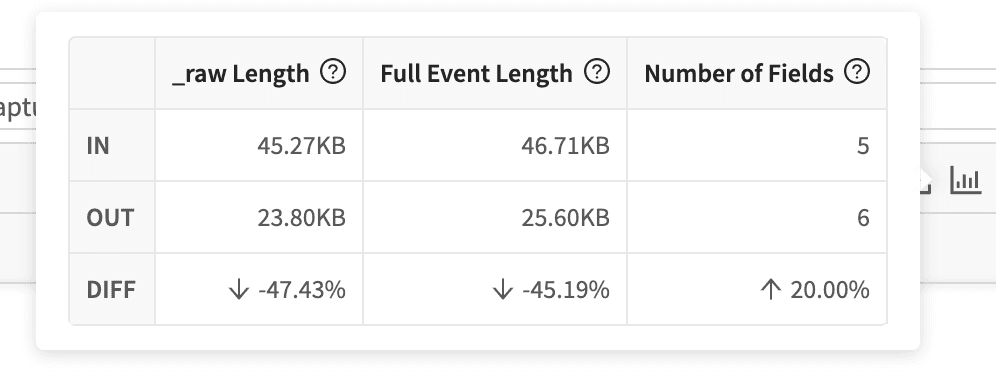
In addition to seeing the specific fields you’re dropping, Cribl’s Preview UI also gives you some statistics on the difference in Data Volume:
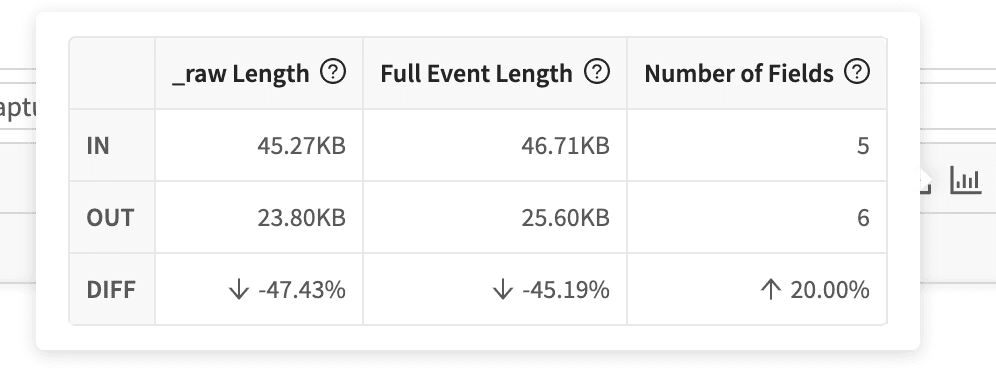
With very minimal effort, we’ve easily trimmed 47% from the raw event.
Just Scratching the Surface
This is just a simple example. There are other techniques, like suppressing duplicate values or lookups, that we could use to eliminate verbose fields like User Agent. Trimming high cardinality fields like session or trace IDs if they’re not being used can have dramatic impacts on the size of data on disk.
If you want to see a live example of this pipeline, check out our demo environment in GitHub. Instructions there make it easy for you to see this live and work with it yourself on your laptop or wherever you’d like.






