The Future of Search Is Here. Experience Faster, Simpler, AI-Powered Investigations.
The Future of Search Is Here. Experience Faster, Simpler, AI-Powered Investigations.
< > Products Overview
Cribl: The AI Platform for Telemetry
Humans and AI agents need clean, reliable data. From ingest to insight, the Cribl platform sets the foundation for AI-ready telemetry so IT and security teams can trust, use, and act on data at scale. Try Cribl today.

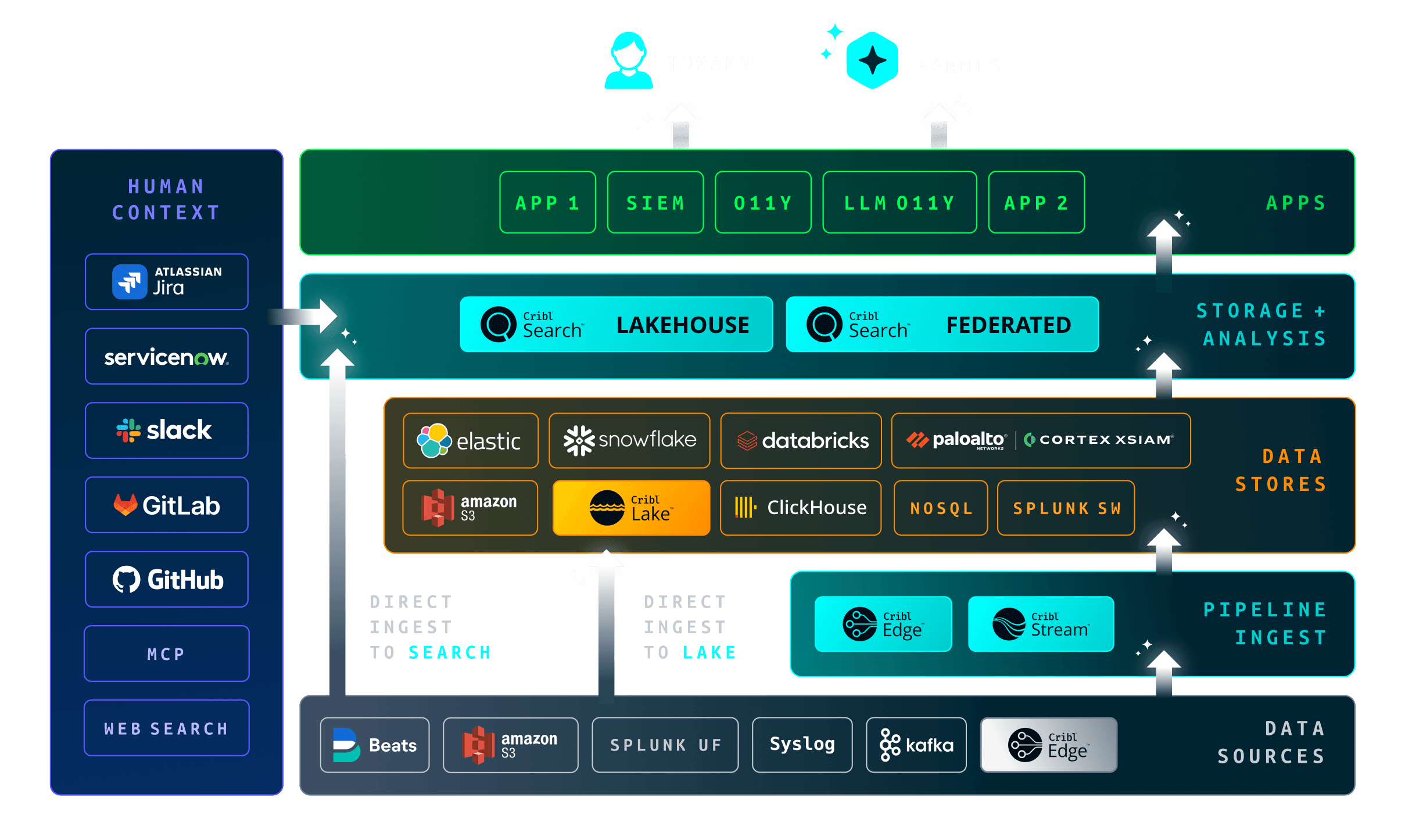
APPS
Every industry works differently. Every team has unique workflows. Build custom apps on Cribl’s AI Platform for Telemetry to get the exact fit for your needs. Backed by a connected telemetry foundation with federated search, RBAC, and governance built in—no training agents to navigate your entire environment.

UNIQUE CHALLENGES OF IT & SECURITY DATA
Telemetry data is growing at 30% CAGR while budgets stay flat, and compliance mandates force you to retain massive volumes of increasingly granular data—turning storage into a constant strain.
The rise of AI makes it worse, introducing a surge of high-frequency, machine-driven queries that traditional platforms—built for human searches—can’t handle.
Resolving the tension between growth, retention, and AI-driven access requires a fundamental leap in productivity.

Unlike business intelligence data, IT and Security telemetry—logs, metrics, traces, configs, etc.—varies widely, making it complex to parse and structure data neatly into rows and columns before landing in analytics systems' storage. Those systems weren't designed for your data. Solutions must natively handle diverse data types that you work with in IT and Security without extensive preprocessing.

The reality is a majority of data isn’t valuable until a critical event occurs, and then it’s suddenly the most important dataset in the enterprise.
Flexible, cost-effective retention and fast, easy retrieval are essential to ensure both humans and AI agents can access the right data at the moment it matters most.
You can’t ask questions of bad data, or data you don’t have.

All Your Data. Any Workflow.
Gain the choice, control, and flexibility you deserve — and the intelligence you need.
Problems Solved
Composable architecture for AI and whatever comes next.
Stop sacrificing speed for cost. Cribl Search lets you investigate anything, anywhere — without moving or rehydrating your data. Ask questions across all your telemetry and get answers fast, with an intuitive, AI-powered experience that cuts through complexity and puts you back in control.

Cribl Edge is a powerful and intelligent agent designed to manage telemetry data collection at massive scale. Built with centralized fleet management as a core tenet, Edge provides a simple way to automatically detect both OS and application telemetry, determine which portions are valuable or require additional processing, and then forward the data to any chosen destination.

Cribl Stream, the industry’s leading observability pipeline, is a robust stream processing engine focused on parsing and processing telemetry data. Use Stream to route, reduce, reformat, or enrich data from any event source to any destination. Simultaneously multicast data streams to multiple destinations for teams that need access to the same data, and replay any data (for any time period) to enhance investigations.

Cribl Lake is a turnkey storage solution that keeps data in its original format, eliminating preprocessing overhead while giving you the flexibility to securely retain and instantly retrieve any data, no matter how diverse or unpredictable, at a fraction of the cost.

Cribl.Cloud gets you up and running fast. We handle the infrastructure, security, and scaling, so you don’t have to. Use any Cribl product, no friction, no B.S. With consumption pricing across every product you only pay for what you use. Simple, transparent pricing. No compromises. Just pure data power.

Cribl now offers app-building capabilities that lets you build apps around the way your teams actually work, on top of the shared, vendor-agnostic telemetry foundation that already handles collection, routing, shaping, storage, and analysis. Your teams can work the way they want instead of being forced to adapt to vendor-defined apps.

Software that goes to 11
Cribl understands your complex log, metric, and trace data problems and is built to meet your evolving needs.
Testimonials
Resources

Test drive
Want to take the Cribl suite of products for a spin? Jump into our sandboxes to get up close and personal with Stream, Edge, Search, and Lake.

