
Scalable data collection from Amazon S3 was introduced back in Cribl LogStream 2.0 and has been a real workhorse, providing essential capabilities to many of our AWS customers. In this post, we’ll take a look at how it works and how to configure it.
If you’re new to Cribl LogStream you may want to take our sandbox for a drive before reading further.
How does it work
Reading data from S3 buckets is usually a fairly simple task: issue an API call to Amazon S3 and read its output. However, a number of challenges need to be addressed once you need to periodically scan S3 buckets for new data. First, listing of objects/files in a S3 bucket can be rather expensive if there are thousands or millions of them therein. Second, keeping track of what is currently read and who’s reading what can become a real issue in a distributed environment. And third, resiliency is all to be figured out by the reader.
One way to address these issues is by using event notifications through Amazon SQS.
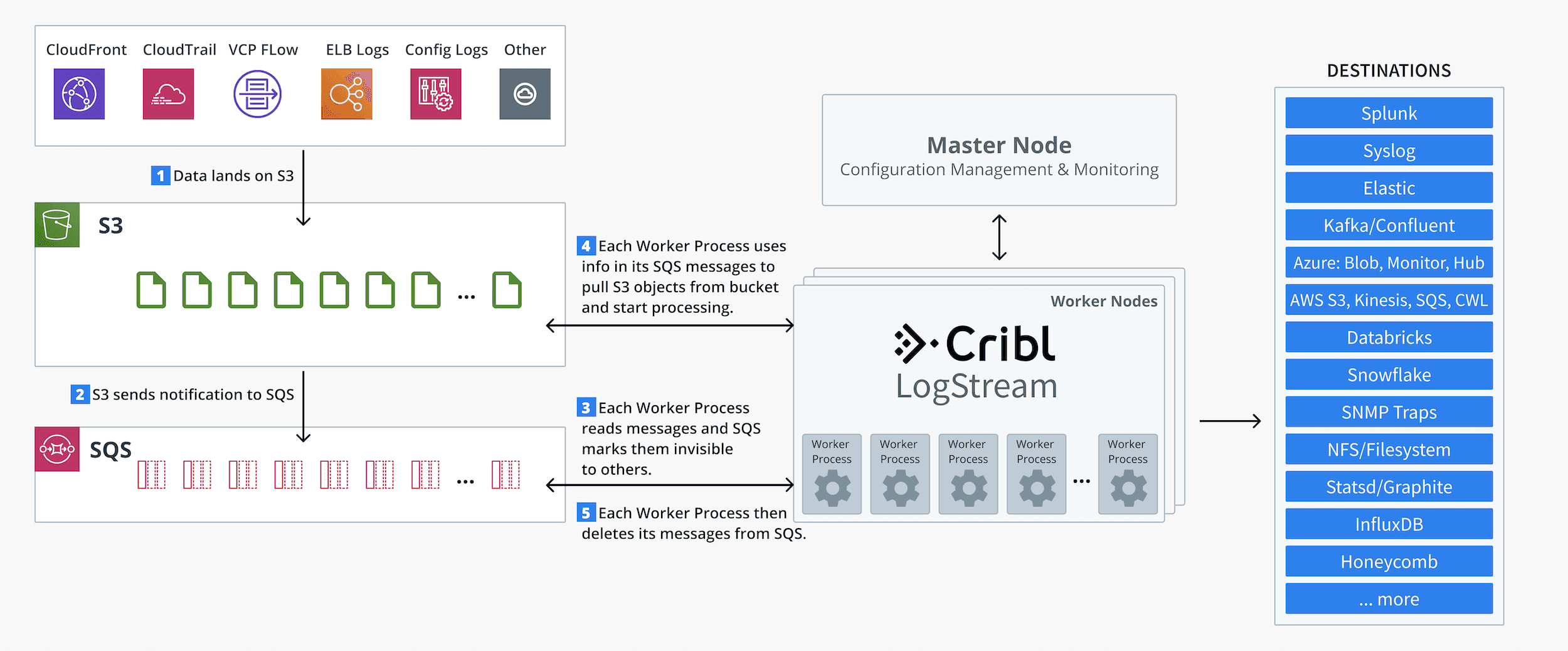
A new object (data) lands on an S3 bucket.
S3 sends a notification message on an SQS queue.
LogStream Worker Processes are configured as SQS queue consumers.Each Worker Process reads messages, while SQS marks them invisible to others. This ensures that no two Workers’ processes read the same message.Each Worker Process extracts the S3 object path from each message.
Each Worker Process then goes into S3 and fetches the object.
Each Worker Process then deletes its messages from SQS.
Benefits
Fast delivery – there is no need for periodic scanning/listing of buckets. All data is read as soon as notifications make it to SQS, in near real-time.
Improved resiliency – if one Worker Process stops processing, or becomes unavailable, SQS will make its messages visible to others.
Better scalability – higher (read) throughput can be achieved simply through adding more Worker Processes.
Learn How to Lower Your Splunk Costs With Cribl Stream
Configuration on AWS side
In this example we’re assuming a simple setup where we only have one S3 bucket and one SQS queue. While you may have multiple buckets sending notifications to one or more queues, the configurations are nearly identical in principle.
Create an SQS queue that will receive direct S3 notifications. Note its ARN.
Set up an Amazon S3 bucket that collects logs/events.
Examples: CloudTrail, VPC Flowlogs, CloudFront, etc.
Configure the SQS queue with a Policy to accept S3 notification events.
In its Permissions tab, click Edit Policy Document (Advanced) and replace the (current) access policy with the one below.
Replace SQS-Queue-ARN-Goes-Here and Bucket-Name-Goes-Here as necessary.
[
{
"Sid": "example-statement-ID",
"Effect": "Allow",
"Principal": {
"AWS":"*"
},
"Action": [
"SQS:SendMessage"
],
"Resource": "SQS-Queue-ARN-Goes-Here",
"Condition": {
"ArnLike": {
"aws:SourceArn": "arn:aws:s3:*:*:Bucket-Name-Goes-Here"
}
}
}
]
}Next, configure the S3 bucket to send notifications for all
s3:ObjectCreated:*events to the SQS queue above.While in the S3 bucket, go to Properties > Events.
Add a notification by selecting All object create events.
Under Send to, choose SQS Queue, and select the queue from above.
Notifications can be additionally configured for subsets of object prefixes (i.e., notify only on creates on certain “folders”) or suffixes (i.e., notify only on creates of certain “file” extensions).
To confirm that notification events are set up correctly, add/upload a sample file to S3 and check the SQS console for new messages.
Configuration on LogStream side
Before we start configuring LogStream, let’s make sure we have all the correct permissions in place. LogStream can use an instance’s IAM roles (if running on AWS), or AWS Key ID/Secret Access Key credentials, to reach out to SQS and S3. In either case, the user or the role must have enough permissions in place to read objects from S3, and to list/read/delete messages from SQS:
## S3
s3:GetObject
s3:ListBucket
## SQS
sqs:ReceiveMessage
sqs:DeleteMessage
sqs:ChangeMessageVisibility
sqs:GetQueueAttributes
sqs:GetQueueUrlNavigate to Sources > Amazon > S3 and click + Add New.
Enter the SQS queue name from above
Optionally, use a Filename Filter that properly describes your objects of interest.
Enter the API Key and Secret Key, unless using an IAM role.
Select a Region where the SQS queue and S3 bucket are located.
Under Event Breakers, add Rulesets as necessary.
Under Advanced Settings, change the following only if really necessary:
Num Receivers: This is the number of SQS pollers to run per Worker Process.
Max Messages: This is the number of messages each receiver (below) can get on each poll.
Visibility Timeout Seconds: This is the duration over which received messages, after being retrieved by a Worker Process, are hidden from subsequent retrieve requests. The default value is 600s. Practically speaking, this is the time each Worker Process is given to fetch and process an S3 object.
Best practices
When LogStream instances are deployed on AWS, use IAM Roles whenever possible.
Not only is it safer, but the configuration is also simpler to maintain.
Although optional, we highly recommend that you use a Filename Filter.
This will ensure that only files of interest are ingested by LogStream.
Ingesting only what’s strictly needed improves latency, processing power, and data quality.
If higher throughput is needed, increase Number of Receivers under Advanced Settings. However, do note:
This is set at 3 by default. Which means, each Worker Process in each LogStream Worker Node will run 3 receivers!
Increased throughput comes with additional CPU utilization.
When ingesting large files, tune up the Visibility Timeout, or consider using smaller objects.
The default value of 600s works well in most cases, and while you certainly can increase it, we also suggest you consider using smaller S3 objects.
—
New to Cribl LogStream? Take our Sandbox for a drive!
If you have any questions or feedback join our community Slack– we’d love to help you out. If you’re looking to join a fast-paced, innovative team drop us a line at hello@cribl.io– we’re hiring!







