
If you’ve ever worked with a log analysis system before, data on-boarding is one of the most painful parts. Every system expects the data to look a little different, and getting that right generally involves a ton of trial and error. Make a configuration change, restart the cluster, try again. Send the data to a test index, see if it looks right, delete it when it’s not. Hours of administrator time sunk in just to get a log queryable the right way.
Cribl LogStream 1.3 changes that fundamentally with our new Preview feature. Now, you can capture the data as it moves and work with it to get it in the right shape, interactively, with a easy to use user interface before sending it on to its permanent destination. And, because Cribl works great with multiple inputs and outputs, our new Input & Output Pipelines allow you to shape up that data specifically for each system, so you can build pipelines in an agnostic manner that work for all systems.
In addition, version 1.3 brings in Data Encryption, Standalone Package, and Lookups & Breakers Libraries.

Data Preview
This version adds support for a highly requested feature; Data Preview. Users can now see in real-time how pipeline and function changes affect incoming data. It helps with shaping and controlling events before they’re delivered to a destination as well as assists with troubleshooting functions.
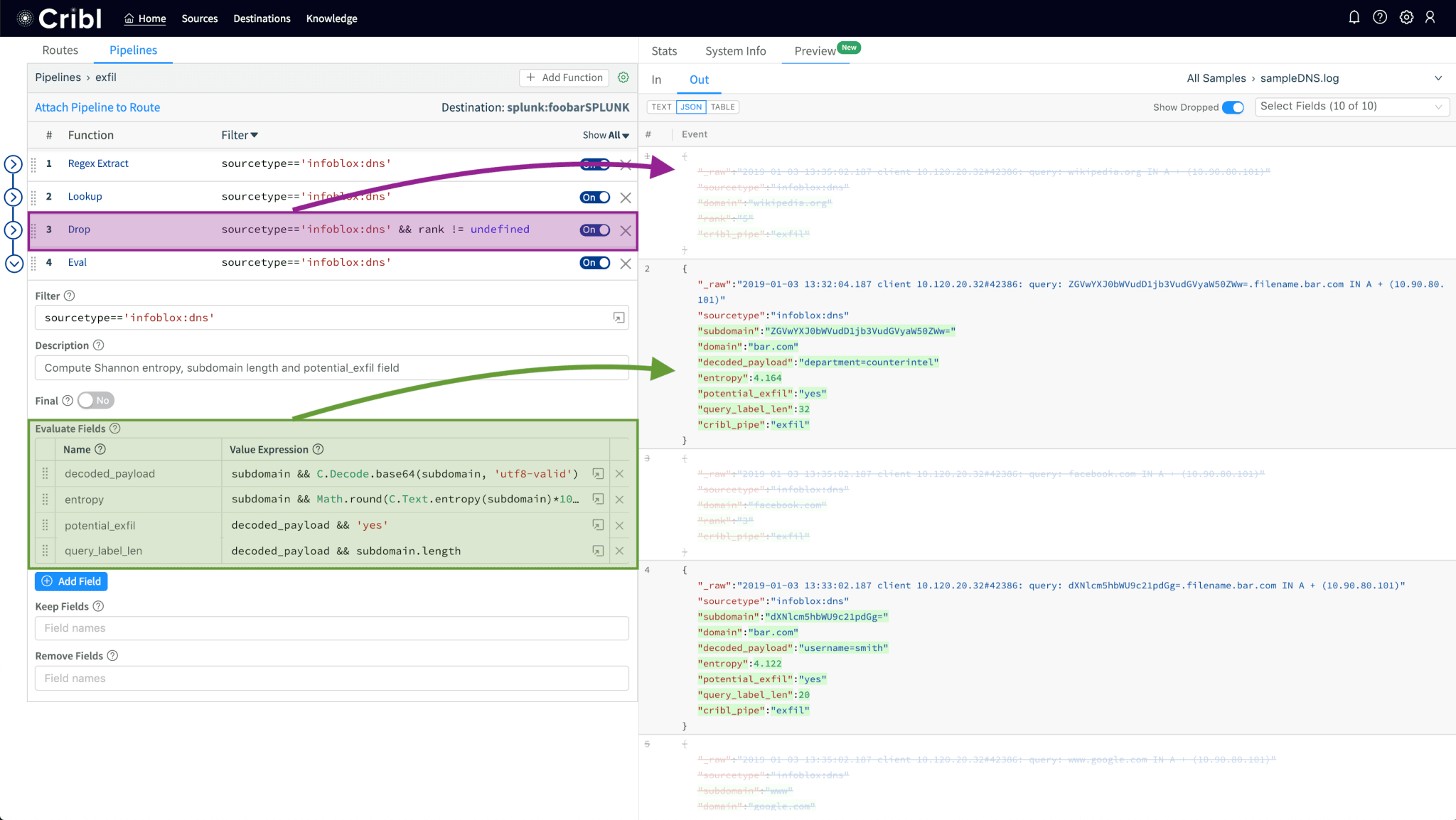
Data Preview of a sample showing dropped events and events with added fields
Samples and Captures
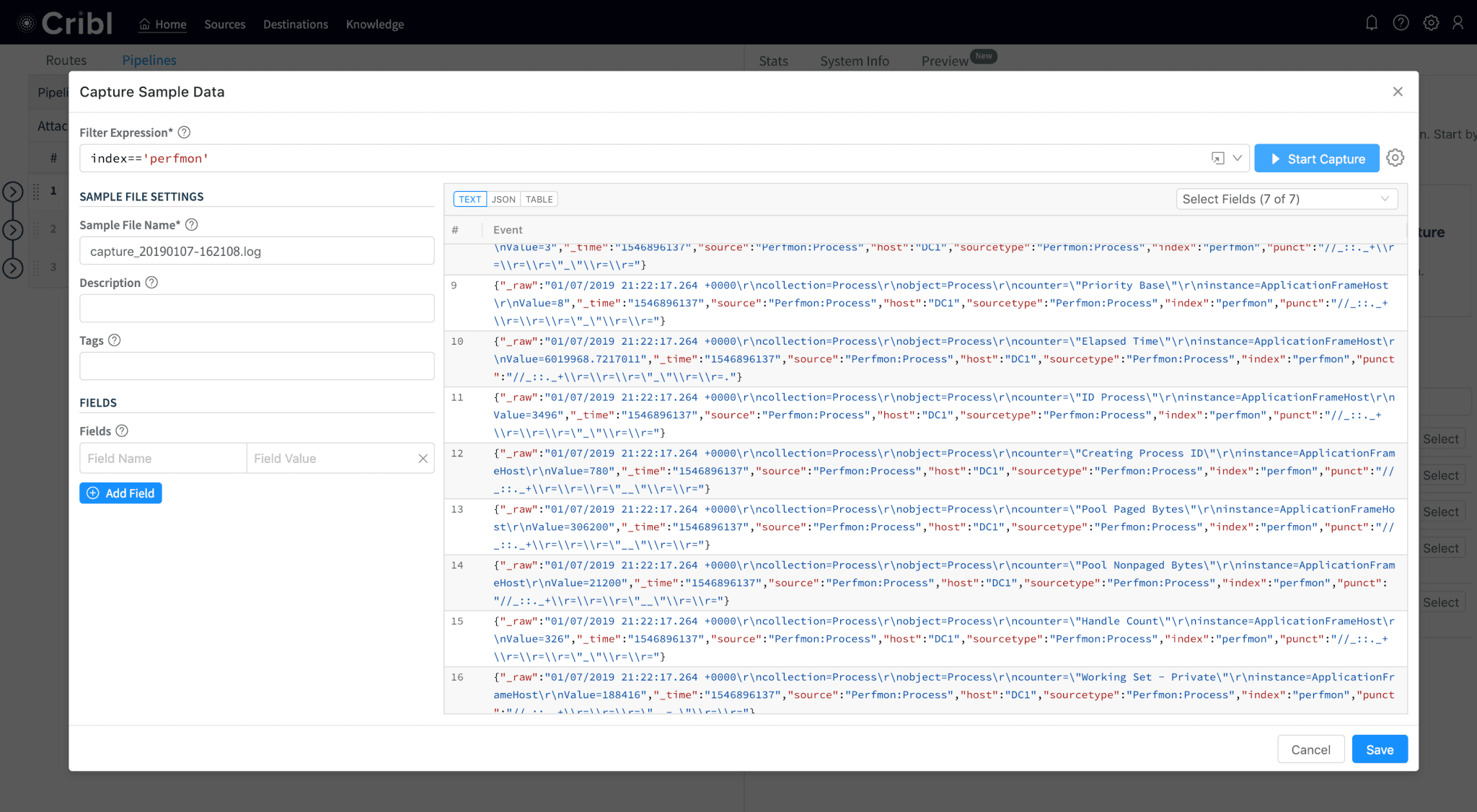
Working with data has never been easier. Users can now Paste or Upload Sample files directly into Cribl which can then be Data Preview’ed or replayed over a pipeline of functions. Sample data can also be Captured live from any input, any pipeline and any filter condition.
Encryption Support
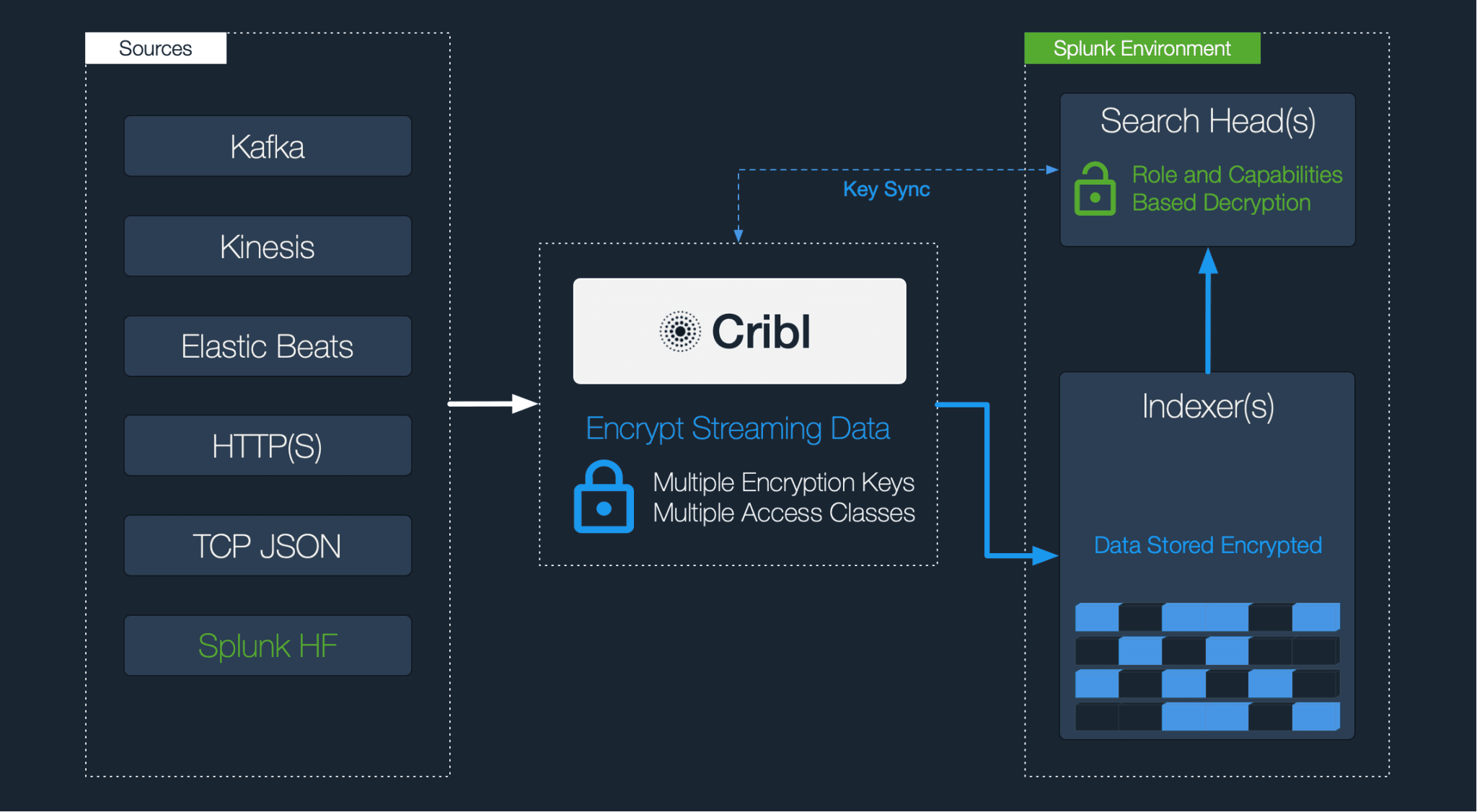
With this version we added support for encrypting sensitive data in real-time. Patterns can now be encrypted using C.Crypto.encrypt() via a Mask function. Decryption is done in Splunk with full RBAC support. In addition, users/groups with the right permissions can be associated with key classes for even more granular, pattern-level compartmentalized access.
Standalone Package
There are two deployment options; standalone and as a Splunk app. The exact choice will depend on your requirements but if you don’t have a Splunk environment, the Standalone package is for you. The only requirement for the standalone package is the Node runtime.
Input & Output Pipelines and New Routing Model
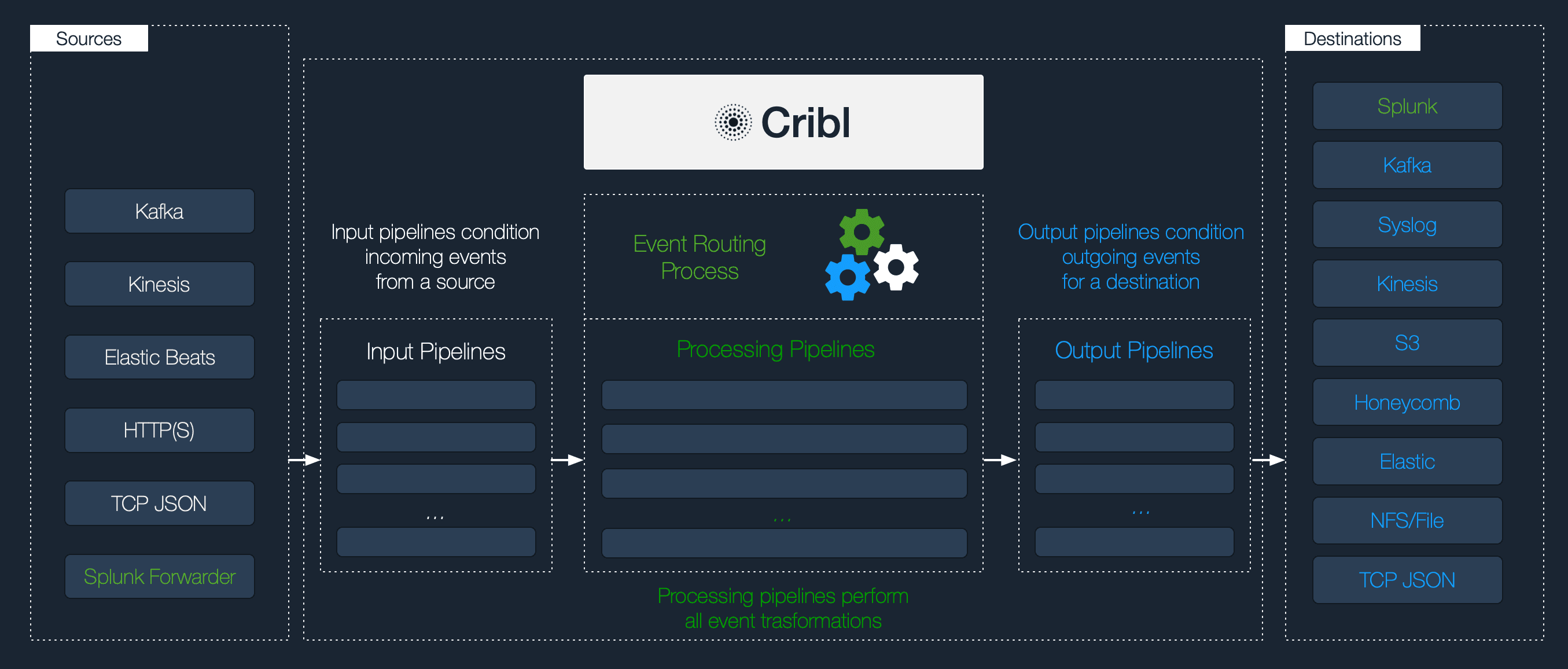
This version also adds support for a more flexible data processing and routing model. We’re introducing Input and Output Pipelines that are attached to a Source (or Input) and Destination (or Output) respectively, for the purposes of conditioning the events before and after processing. In addition, Routes can now be configured with an output directly. This model now makes the Processing Pipelines completely independent and reusable.
Lookups & Event Breaker Libraries
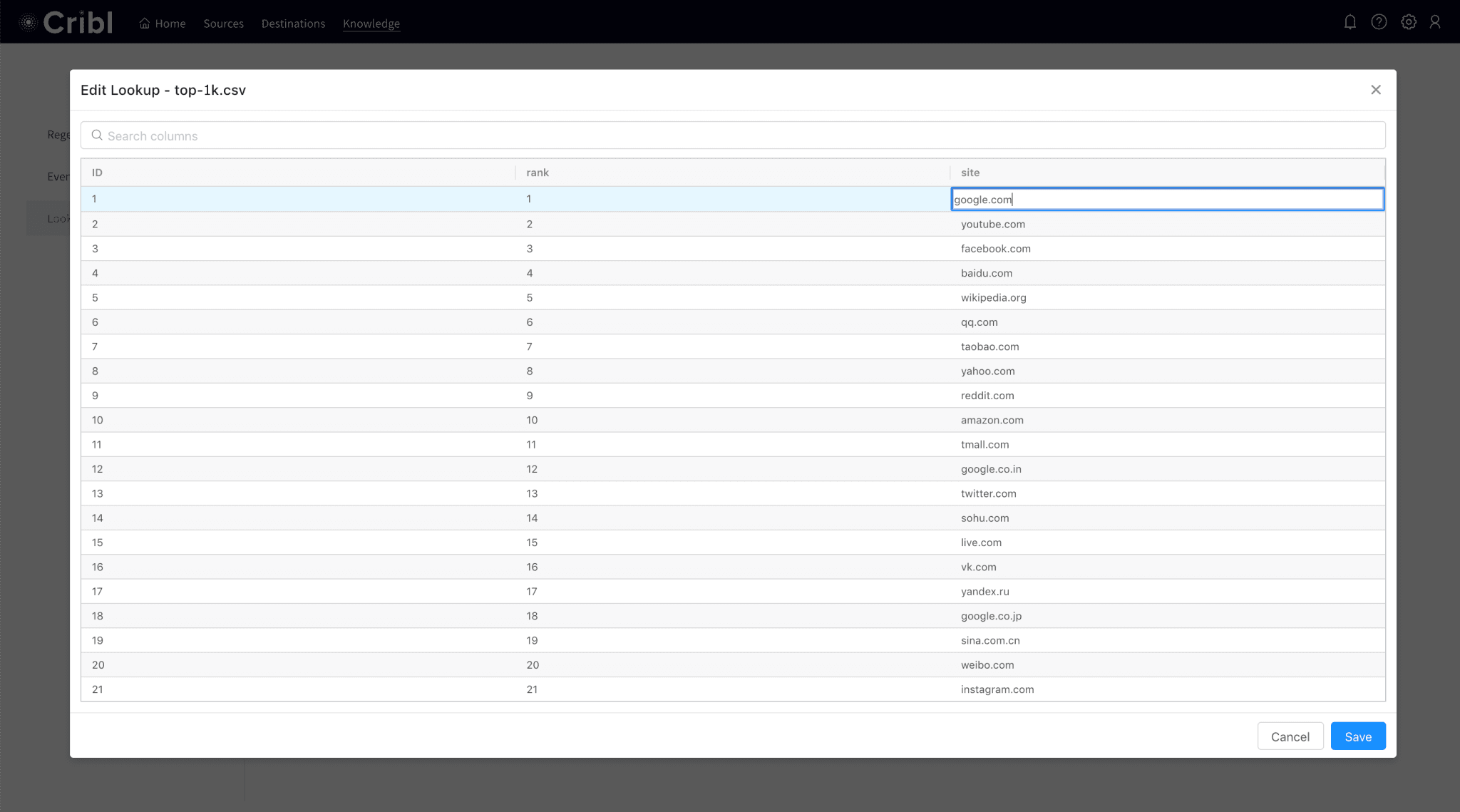
There is now full management UI for Lookups files. The interface allows for lookups to be added, deleted and edited. All files handled by the UI are stored in $CRIBL_HOME/data/lookups.
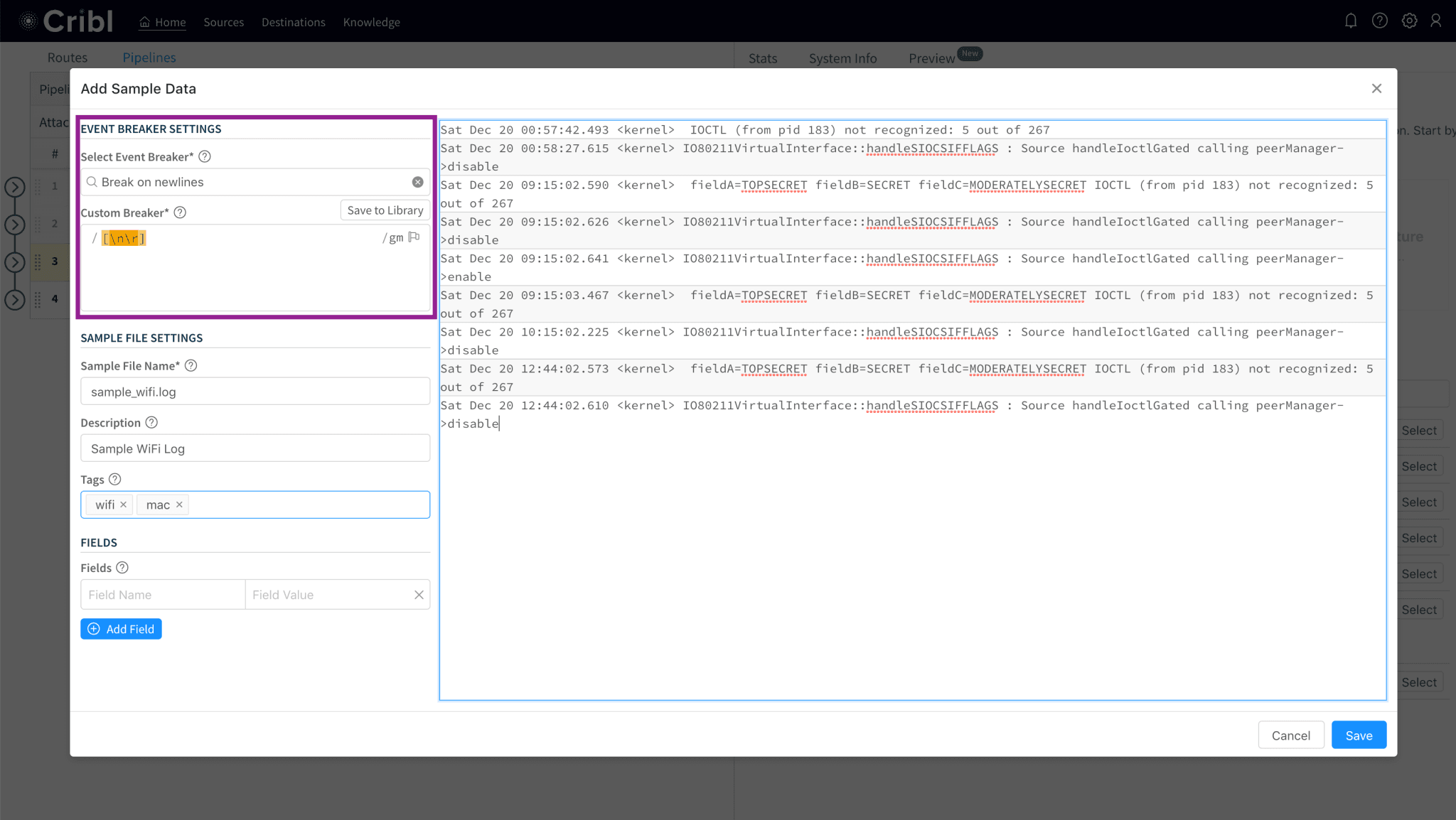
This version also adds Event Breakers. They are regex patterns that assist in breaking a sample file or paste into events for the purposes of Data Preview. The Event Breakers management interface can be found under Knowledge > Event Breakers. Breakers can be edited, added, deleted, searched and tagged as necessary.
—
If you like what we’re doing, come and check us out at Cribl.io. If you’d like more details on installation or configuration, see our documentation or join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to help you!






