Git and Get Going
In this conversation, Sanjay Shrestha, Principal Detection Engineer at Bayer, and Raanan Dagan, Principal Sales Engineer from Cribl, talk about the integration of Git in Cribl Stream. They discuss how to manage configuration files and pipelines as code, simplifying their deployment. They also share a demo and give best practices for optimizing your GitOps workflow.
In the 10+ years that Bayer has worked with Splunk, they’ve gone from processing just 80 GB/day to more than 13 TB/day. An increased data ingestion workload after moving to Splunk Cloud has also caused a considerable surge in operational costs and DDAA (Dynamic Data Active Archive) costs.
Since introducing Cribl Stream one year ago, Bayer has reduced those operational costs by 30% and DDAA costs by 70%. They leverage Cribl-to-Cribl integration to avoid double licensing costs, and take advantage of the vendor-agnostic nature of Cribl Stream to avoid SIEM vendor lock-in — routing logs to both Splunk and Exabeam. Bayer is also leveraging the integration of Git in Cribl to manage the configurations and data pipelines in their architecture.
Cribl Architecture at Bayer
Bayer’s architecture consists of two distinct worker groups deployed across several AWS regions — one for the US and the other for the EMEA region. They are further categorized into distinct public and private groups. The private worker group ingests logs from their internal network, and the public worker group is open to third-party vendor’s audit logs.
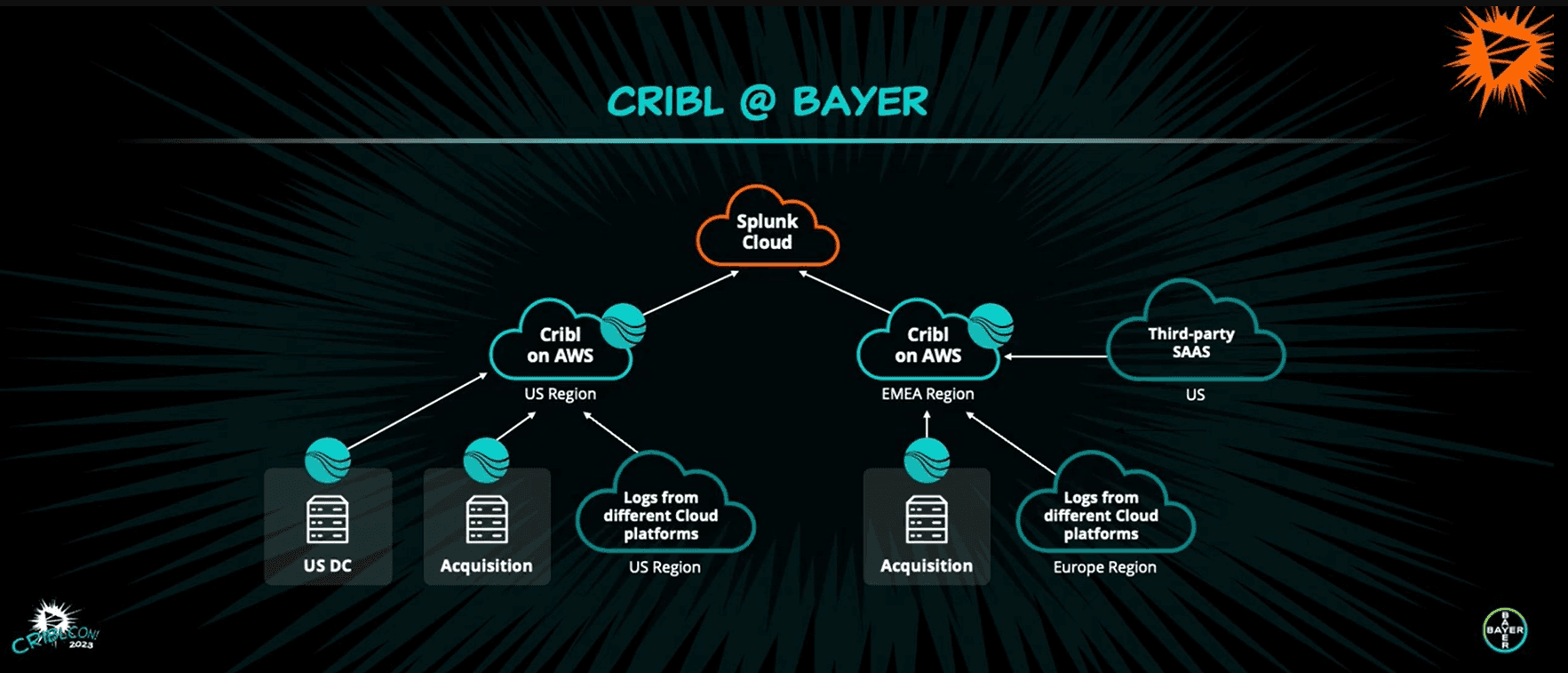
The diagram above also shows a third-party vendor in the US sending logs to Bayer’s Cribl instance, and illustrates the Cribl-to-Cribl integration. Logs are sent to Bayer via the data center’s Cribl Stream instance and then from Bayer’s Cribl instance on AWS to Splunk Cloud.
Cribl and GitOps Integration at Bayer
The continuous, efficient flow of Bayer’s data is made possible by the integration between Cribl and Git. The GitOps operational model encompasses methodologies like version control, CI/CD, monitoring, and infrastructure automation — Git capabilities in Cribl Stream allow for the continuous addition of pipelines, Cribl Packs, sources, and destinations.
The integration provides an environment where you can continuously evolve the development-to-production cycle of your data pipelines and leverage a remote Git repository. Adjusting the Git settings in Cribl Stream will simplify and synchronize the dev → prod cycle, and create an environment where only approved changes make it into production.
Switch the GitOps workflow for your prod environment to push, and it will become read-only — meaning that changes will only be permitted in the dev environment. They’ll get committed to a dev branch of your repository, and then changes approved by production move to a prod branch to be merged and deployed.
You can also incorporate the Git methodology into specific sources, destinations, and routes. An option in Cribl Stream allows you to designate environments as dev or prod, so everything in those environments behaves accordingly. If a source, destination, or route within an environment doesn’t match the dev or prod bucket it’s supposed to, Cribl will automatically make it inactive. You can reactivate them by simply switching the designation.
Best Practices for Cribl Stream and Git
Here are some of the strategies and techniques Bayer has used to make the most of the Git Ops methodology within Cribl Stream.
Create a private repository. There will be some proprietary information that you won’t want to be public.
Grant access to users as per-need basis. You want to keep full control over who can approve pipelines and packs to move from dev to prod.
Examine the git.ignore file carefully. Know which default values are considered worthy of ignoring versus adding when Cribl pushes configurations from a local to remote Git repository.
Use Git as a backup to restore an environment. Store critical configurations so you can revert back to a previous environment if you run into any issues.
Use declarative comments. Details will help with understanding configuration changes and troubleshooting problems effectively.
Choose branches over repositories. This provides a more efficient and cohesive development environment and enables a pull request feature.
Worker/Global Commit and Deploy. When you make changes and commit on a global scope, you should push changes across multiple Cribl workers.
Continuous Push and Commit. This contributes to a more agile and efficient development process by giving rapid feedback and improving collaboration.
Be sure to watch the whole presentation for a demo of Cribl Stream and Git in action, and to learn more about how they can be used together to simplify the deployment and management of data pipelines.