AI Observability
Empowering Platform Engineering and SREs
10x Investigations
Telemetry as a Shared Service
SOC Modernization
Avoid Vendor Lock-In
SIEM Migration
Cost Control
Cloud Migration
NetOps Observability
Data Strategy and Tiering
DORA Compliance
Interactive Demos
See all Integrations
Build
Route
Enrich
Investigate
Reduce
Transform
Store
Replay
Collect
Onboard
Redact
Visualize
Amazon Web Services
Microsoft
Crowdstrike
Palo Alto Networks - Nav
Deloitte Logo
Splunk
Elastic
Wiz
Exabeam
Confluent
Google
See all Integrations
Healthcare
Managed Security Services
Technology and Software
Communications & Media
State, Local Government, and Education
Retail
Federal
Manufacturing & Logistics
Financial Services
Learn more
Pricing
Support
Research Panel
Stream
Cribl.Cloud
Edge
Apps
Search
Cribl AI
Lake
Insights
Activation Services
Service Delivery Partners
Read customer stories
Register today!
Learn more
Learn more
Learn more
Learn more
Learn more
Learn more
Cribl Learning
Cribl University
Resource Library
Tech Docs
AI Readiness Hub
AI Readiness Assessment
Knowledge Base
Community Slack
Download Library
Past Releases
Support Portal
Customer Success
Blog & Podcasts
Events
Webinars
Packs
GitHub Repos
Docker Hub
Glossary
Telemetry 101
Observability 101
AI 101
ROI calculator
Learn more
Careers
News
Contact
Leadership
Cribl for Startups
Watch now
Partner Program
Become a Partner
Partner Login
Schedule a demo
Try a Sandbox
Cloud trial
Cribl.Cloud
Solutions
Products
Customers
Learning & Resources
Pricing
About
Demos
Try Cribl
Blog
Cribl Edge
Cribl Edge
Page 1 of 3 · 53 posts
07/22/2026
|
Announcements
What’s New! We heard you like AI.
Aren Gates
Read now
07/06/2026
|
Cribl Edge
Nobody should have to babysit a dashboard: How alerting works in Cribl Insights
Charles Hills
Read now
06/18/2026
|
Cribl Search
How to build an AI telemetry architecture that serves five teams without duplicate collection
Joel Vincent
Read now
06/17/2026
|
Cribl Search
One AI stack. Five teams. Zero compromise.
Joel Vincent
Read now
06/16/2026
|
Cribl Stream
Effective AI observability is a telemetry problem, not a tool problem.
Joel Vincent
Read now
05/29/2026
|
Cribl Lake
Smarter data pipelines for modern healthcare
Chris Thom
Read now
05/15/2026
|
Cribl Lake
Operational technology challenges? Meet Cribl solutions
Chris Thom
Read now
04/17/2026
|
Cribl Edge
The easy button — Get Cribl Edge Windows Events into Elastic
Dane Engquist
Read now
03/24/2026
|
Cribl Stream
Cribl is now a CVE Numbering Authority (CNA)
Rory McEntee
Read now
03/11/2026
|
Cribl Edge
What’s New blog, pt. deux
Aren Gates
Read now
03/05/2026
|
Cribl Edge
Modern observability on Nutanix Kubernetes Platform powered by Cribl Edge
Greg Coleman
Read now
10/14/2025
|
Cribl Edge
One agent, no headache: Cribl Edge now supports macOS
Judith Silverberg-Rajna
Read now
10/14/2025
|
Announcements
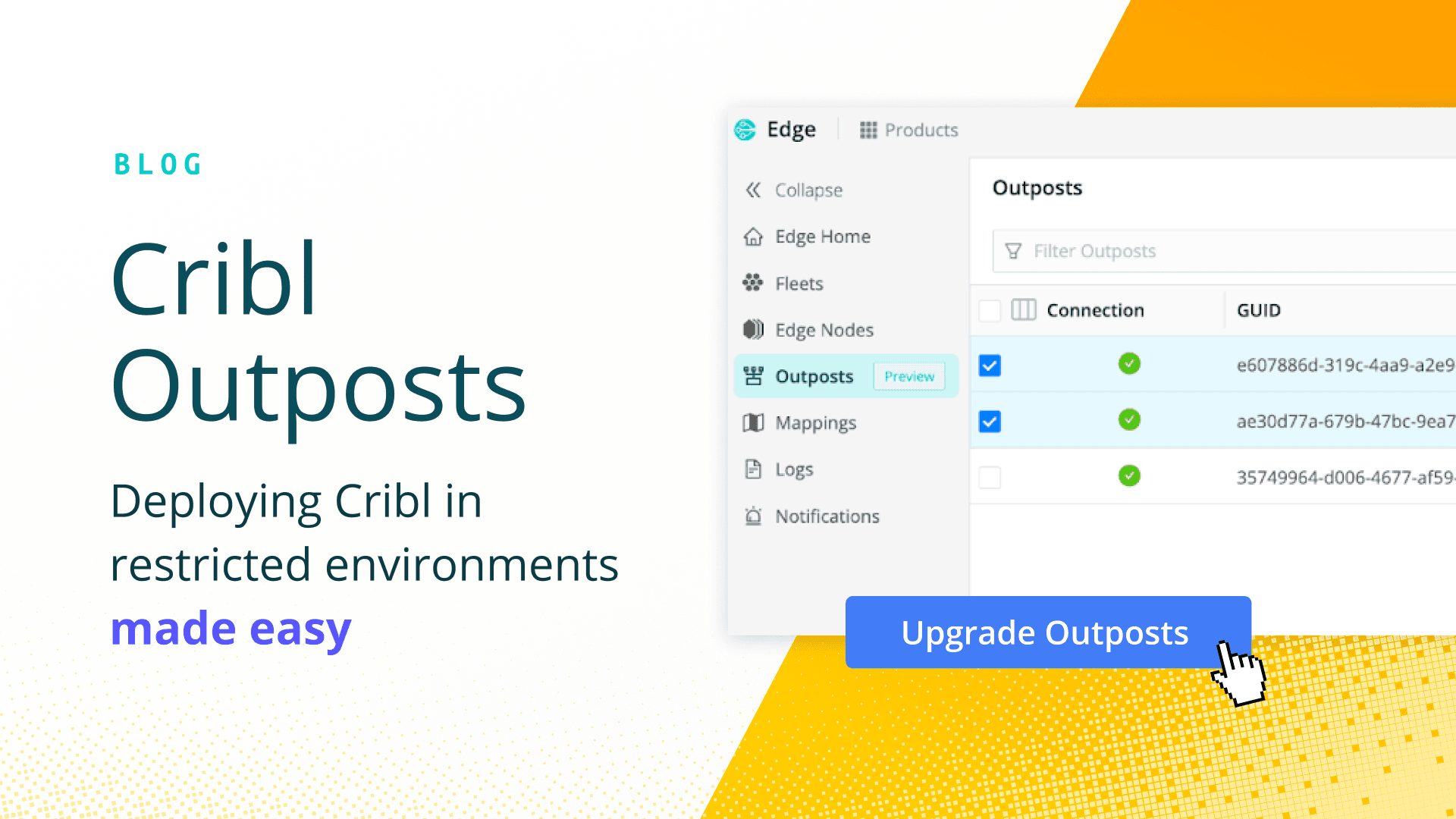
Cribl Outposts: Deploying Cribl in restricted environments made easy
Judith Silverberg-Rajna
Read now
10/09/2025
|
Cribl Stream
Manual vs. auto instrumentation OpenTelemetry: Choose what’s right
Emily Ashley and
Desi Gavis-Hughson
Read now
09/29/2025
|
Cribl Edge
Replacing Kinesis Data Streams with Cribl Stream: A real-world cost-saving strategy
Josh Rice
Read now
08/29/2025
|
Cribl Edge
Edge to insight: Unlock Windows Security in Google SecOps with Cribl
Kevin Morris
Read now
08/13/2025
|
Cribl Edge
How to Monitor NVIDIA GPU Metrics with Cribl Edge & Stream (Complete Tutorial)
Nikhil Mungel
Read now
07/01/2025
|
Cribl Edge
Cribl Edge: A Universal Forwarder Alternative
Cribl
Read now
1
2
3