
Part of what makes Cribl unique is our focus on the particulars of working with gritty old logs. Logs present challenges not addressed by most data processing systems: working easily with overly verbose data and formats which can be weirdly structured, nested, and hard to parse. Not only are logs noisy by throwing lots of worthless events at you, but each individual message often contains useless information. Since our earliest days talking to customers, the same problem came up over and over: I have this large event with dozens of fields and I’m only using a fraction of them.
The reason for this common problem is clear: the person producing the log feels it necessary to put out any information that may be useful in the future. Cisco eStreamer has more 90 fields in every event. Merely removing fields set to null or 0 can trim 50% of the data volume at many customers. In house developers tend to take the easiest path and just serialize their whole data structure to JSON, resulting in huge blobs where 80% or more of the data is not useful to the consumer. Cribl’s unique value prop is to put the log consumer in control of what’s coming to them, for the first time giving administrators a flexible control point between log producers and consumers. We help you shave off excess material from your logs, like this lathe. (I considered changing images because I’m worried people will just stop here and watch this all day, but I wanted to give you the same satisfaction I have gotten from staring at it).
Another particular unique challenge with logs is nested data structures. People say logs are unstructured, but that’s not universally true. Many logs, like firewall logs or web access logs are very structured, but they might be more esoteric formats that require a special parser.
Cribl LogStream 1.4 solves both of these challenges with a new Parser function which lets you parse common log formats, nested inside any other field anywhere in an event, and easily reserialize these formats. Reserializing allows administrators, in one step, to drop unnecessary fields while retaining the exact same structure so field extractions continue to work. Customers often can trim 50-80% off of a chatty event source while losing no functionality.
In addition to the new Parser function, Cribl LogStream 1.4, adds support for ingesting Splunk’s HTTP Event Collector format directly without requiring a heavy forwarder, the ability to run custom scripts directly from the UI, new status indicators for sources and destinations, and a new suppression function for easily controlling repeated, chatty messages.
Cribl LogStream 1.4 is available for download today. Grab the latest bits and get to work reshaping your logs in your log stream! Check out the release notes here. If you’d like to learn more about how these new capabilities work, please read on.
Parser
The new Parser function pulls double duty. The first is that it allows you to easily parse and extract structure from CSV, Common Log Format, Extended Log Format, or JSON formats. We also include a parsers library for common log formats like a number from Palo Alto, AWS or Apache HTTPd. Obviously, we have to have a parser, but the more exciting functionality is the ability to reserialize data in these formats. Reserializing extracts the structure from the event, allows you to filter fields or setting them to null, and serializes the data back while preserving the structure.
Let’s say I have a log in CSV format. In this example, I have 4 columns:
timestamp,action,action_description,item1550533388,OPEN,"An Open Action was initiated",door1550533402,CLOSE,"A Close Action was completed",doorIn my contrived example, the action_description is the most verbose portion of each message and provides no additional value above knowing what the action column provides, and in fact could be easily added via a search time lookup. With our new Parser function, you can tell Cribl to drop the action_description field, and we’ll rewrite your event to make it look this.
timestamp,action,action_description,item1550533388,OPEN,,door1550533402,CLOSE,,doorNote, we keep the header the same and we leave the column in the CSV to keep the order of fields the same while replacing it with a blank value. For many data sources, this approach can reduce data volumes considerably with no loss in functionality from the original data source. We mirror this same approach we take with CSV for all the serialization formats we support.
Suppression
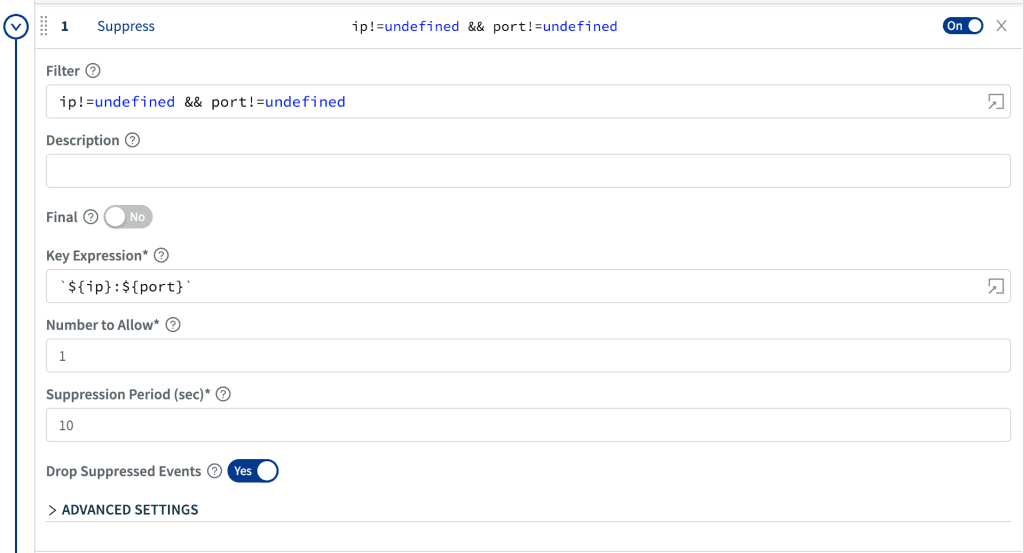
Another frequent problem we saw at customers was bursts of the same or similar messages generating a ton of data volume while really providing no incremental value after the initial message. How many times do you need to know you’re seeing a 503 on that particular endpoint? With suppression, we allow you to give us an expression, and for each unique value of that expression over a duration S seconds, keep N events
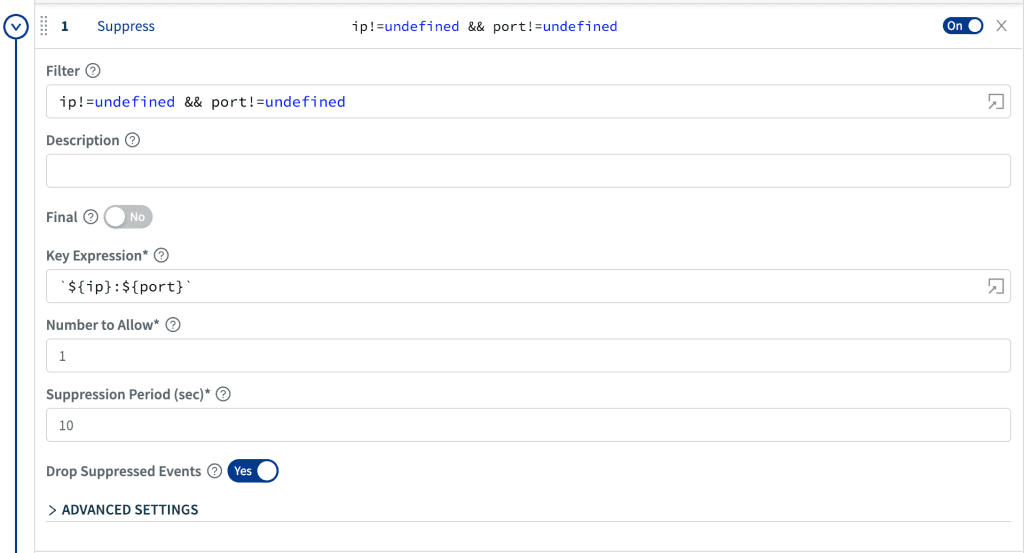
In the above example, we’ll keep 1 message every 10 seconds for each unique tuple of ip and portin the event. Given the powerful nature of JavaScript Expressions in Cribl, you can simply and easily formulate an expression to be as fine grained as you like.
HEC, Status & Script
Also included in this release is support for Splunk’s HTTP Event Collector endpoint and data shape. Now you can point anything destined for HEC directly at Cribl without needing a Splunk Heavy Forwarder. The Cribl UI now provides a status indicator and details about recent errors for every input and output, helping you quickly diagnose problems. Lastly, we’ve included the ability to call scripts from the Cribl UI, useful if you are running in a distributed environment and want to trigger a script to deploy configurations, for example.
That about wraps it up for version 1.4! Check out the release notes for more information.
The fastest way to get started with Cribl LogStream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using LogStream within a few minutes.






