

Are you drowning in data from disparate sources? Are you struggling to analyze it efficiently, sift through different formats, and catch crucial signals? You’re not alone.
Cribl Search and Cribl Stream is a powerful combo that lets you unlock insights from vast data volumes – regardless of their source or format. Say goodbye to siloed searches and hello to holistic analysis.
Why a Common Schema?
Implementing a common data schema in your environment ensures that data is consistent across different security analytics tools, making it easier to correlate and analyze information. Even if you use only a single analytics tool for your data, a common schema can save you time and make your analysis more accurate.
Creating correlation rules and alerts with a common schema helps you focus on what you are searching for or alerting on rather than understand what all those dozens and dozens of completely differently structured data sources look like.
Let’s look at a practical example. You need to find which public IP addresses successfully communicated with your critical system with IP address 50.40.30.10 over port 22 (SSH) over the past 36 months. It’s easy to figure this out with a search or two, right?
Not necessarily. Let’s say that in your environment, you have on-premises firewalls, including Palo Alto Networks, and the system in question was moved from on-prem to AWS recently (keeping the same public address). Meanwhile, other parts of your organization experiment with cloud providers and firewall vendors. Some Host-based Intrusion Detection Systems (HIDS) and Endpoint Detection and Response (EDR) solutions in your environment capture network traffic events… Sometimes? Maybe? What are those other tools exactly? You may not know, and it may be challenging to find out because there have been too many changes in the environment recently made by different teams using different network tools and cloud providers.
You typically have a couple of options here:
Search one data source at a time or
Try to craft a search query with wildcards or regex.
However, some interesting and unpleasant things may happen when using either of these approaches. To make this a bit more tangible, here are some basic examples of searches for both approaches:
Approach 1. Search one data source at a time
First, we’ll search Palo Alto Networks firewall logs to create a timechart of the source IPs that were allowed to communicate with our system in question over port 22:
dataset="Network" dataSource="pan_traffic" destination_ip="50.40.30.10" destination_port="22" action="allow"
| timestats count() by source_ip
So far, so good. Next, a similar search for AWS VPC Flow Logs:
dataset="Network" dataSource="vpcflowlogs" dstaddr="50.40.30.10" dstport="22" action="ALLOW"
| timestats count() by srcaddrIt’s probably okay to run a few searches like that if you are sure you only have two data sources with the information you are looking for. But are you sure that all of the network communication events are captured in the firewall or the AWS VPC Flow? There can easily be some network logs from other tools like CrowdStrike or Zeek that show the allowed connection to 50.40.30.10. Or maybe even some Fortigate firewalls the network team used at some point, or some traffic was going via Google Cloud.
This approach is too time-consuming and often misses valuable information.
Approach 2: Search using wildcards or regex
A broad search hoping to catch every allowed connection over port 22 to an IP may look like this:
dataset="Network" "50.40.30.10" "22" ("allow*" or "ALLOW*")
| timestats count() by srcaddrNo, that won’t work. There are multiple issues with this search. It will pick up the IP address in question as source and destination; it will miss any data sources that don’t call allowed connections allow* or ALLOW*. For example, what about accept (Fortinet uses that value) or just A (Azure NSG Logs use that)? Then, searching for 22 will bring back all kinds of irrelevant events.
But that’s not all. We cannot show results in a way that is easily consumable because we don’t know the name of the field for the source address, so we’ll have to abandon the last part | timestats count() by srcaddr, and start by staring at the raw events before figuring out whether we can create an easy-to-understand summary that tells us which IPs communicated to the system in question and when.
It’s pretty difficult to ensure that a wildcard or regex based search will return all the results you are looking for, and it may even return only the results you are looking for.
As we can see, there must be a common format and naming conventions for the fields and values we’re searching for. Otherwise, we will spend too much time answering simple questions by running many searches. And, even after that, there is a good chance that we’ll miss some significant events.
Benefits of a Common Schema
A common schema is a standardized way of organizing data that allows different data sources to be analyzed simultaneously and more efficiently. This is particularly important in security analytics, where many different data sources containing similar types of information have very different event formats.
Having a common schema can also be especially useful when dealing with large amounts of data, as it can help to identify patterns and trends that might not be immediately apparent. And, of course, threat hunting and creating alerts and correlation searches become much easier with a common schema.
Let’s return to our example, where we want to find which public IP addresses have successfully communicated with the critical system 50.40.30.10 on port 22 (SSH) over the past 36 months. With a common schema, the search will look like this:
dataset="CriblSecurity" event.category="network" event.type="connection" event.outcome="success" destination.address="50.40.30.10" destination.port="22"
| timestats count() by data_source.addressThere is no need to run multiple searches, and the chances of missing important information are much lower.
In the example above, we use data mapped to a common schema like an open source (Apache 2.0) Elastic Common Schema (ECS). But you have a choice of OCSF (another open-source schema) or proprietary vendor schemas.
When using a common schema, your data analytics, detections, threat hunting, alerts, and correlation rules become easier to create, execute, and maintain as you add and replace all vendor tools producing logs.
The dashboard below shows an example of what you can do using a common schema with Cribl Search. The dashboard gives an at-a-glance overview of network traffic in an organization regardless of what network devices, vendor solutions and cloud providers are in place. The network traffic events in this particular organization are collected from Palo Alto Networks firewalls and two public cloud providers – AWS and Azure.
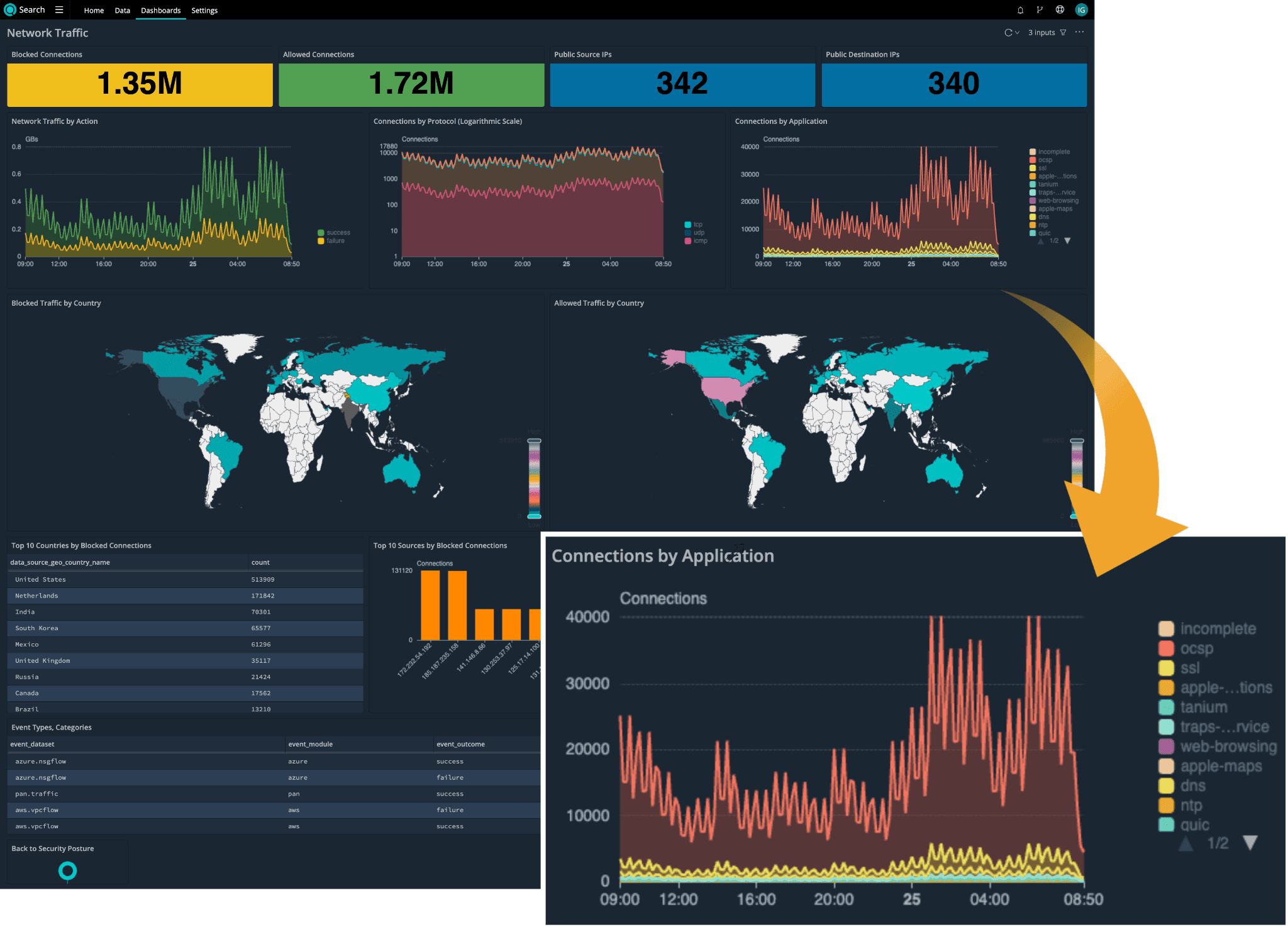
Diving deeper into one of the dashboard panels we zoomed in on above, the chart can be created using the following simple search string that will query all of the network data sources mapped to a common schema:
dataset="CriblSecurity" event.category="network" event.type="connection"
| timestats count() by network.applicationGetting Started With a Common Schema
Suppose you have more than a handful of data sources you want to analyze with Cribl Search. In that case, you should consider using a common schema to find what you are looking for faster and avoid missing essential signals in your threat hunts, correlation searches, or alerts.
Cribl provides a practical way to map your data sources to a common schema. Packs for Cribl Stream, like AWS VPC Flow Pack for Security Teams and other published and upcoming Cribl Packs map data sources to a common schema.
Let your voice be heard in the Cribl Community Slack so we know which data sources are important for you to be mapped to a common schema.
Wrap up
Cribl Stream helps you normalize data and map it to a common schema. Normalized data is easier and faster to analyze with Cribl Search. By mapping to a schema, you can also focus on analyzing data and spend less time figuring out all the different and ever-changing data formats coming from different devices, solutions, and applications. You can also use vendor-agnostic searches, correlation, and alert rules.
If you haven’t done so yet, sign up for a free Cribl.Cloud account now and start standardizing your data with Cribl Stream and analyzing the data with Cribl Search!






