

As someone who admittedly gets bored easily, one of my favorite things about working for a company like Cribl is the huge amount of technologies in our ecosystem I get exposure to. Over time, I also get to observe trends in the market – it’s always so cool to see big upswings in adoption for various platforms and tech. One such trend I’ve observed over the last year is a noticeable uptake and presence in the market of Google SecOps. Typically when I see someone looking at or using Google SecOps, it’s for massive volumes of data.
Whether or not it’s replacing an existing SIEM, or is part of a SIEM augmentation/data tiering strategy, Cribl Stream can greatly simplify getting data in, effectively removing any friction to adopt and get huge value from Google SecOps. Cribl helps you ingest data from any source within your existing data infrastructure, (whether it be raw data, syslog, Windows events, etc… you name it!), then onboard that data into Google SecOps via a centralized control plane within minutes, without having to add new infrastructure and agents. You’re able to support massive amounts of better-quality data and streamline threat detection and response, regardless of retention level.
In this blog, I’ll run you through some key considerations on how to implement a Google SecOps destination in Stream, as there are a couple of different approaches (via a structured or unstructured endpoint). Now onto the good stuff…
Configuring a Google SecOps Destination
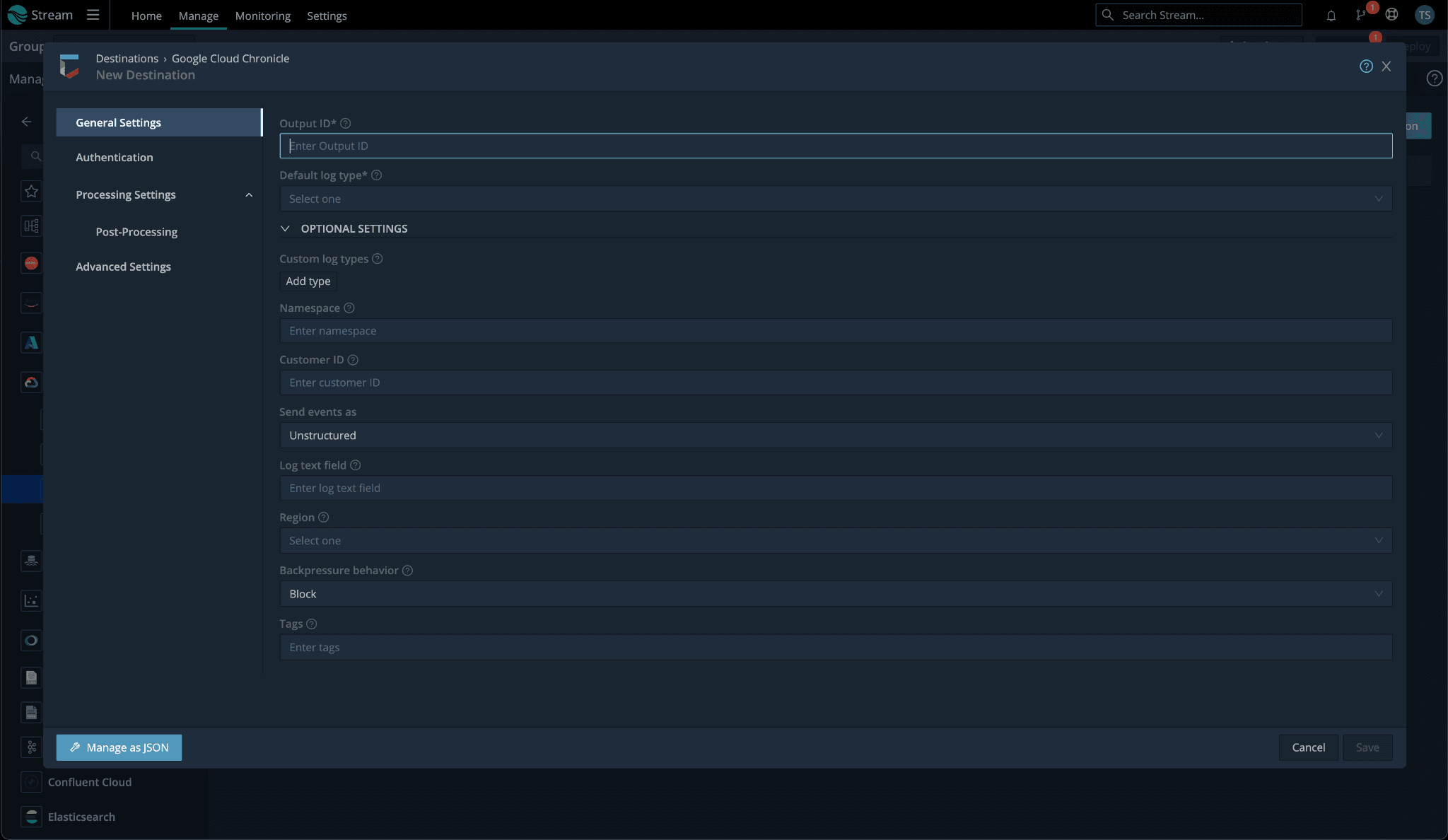
Stream aside, there are two ways to get data into Google SecOps. One, via the unstructured endpoint where Google SecOps will handle the parsing into UDM from various supported log sources, or two, via the structured endpoint, which accepts Google SecOps’ native UDM format. This blog will focus on the former, I’ll save the structured/UDM deets for a follow-up post.
With Stream and sending to the unstructured endpoint, there are two basic approaches you can use. You can use a more declarative approach, which will be less prone to routing issues, by configuring a destination per log source using the default log type field drop-down. The tradeoff is you could wind up needing to configure a large number of destinations, one for each distinct log source you have. And you’ll need to account for this every time you onboard a new source.
Alternatively, you can create a single Google SecOps destination and control the log type by creating an internal field “__logType” via an eval function, set to the correct ingestion label prior to the log hitting the destination. Please be aware the ingestion label is not the friendly product name you see in the related drop-down in our destination settings. Use the ingestion label found in this list of supported default parsers (i.e. for Palo Alto Firewall logs, you’d use a value of “PAN_FIREWALL”).
The downside to this approach is that it is more prone to routing errors given a log doesn’t match a route/pipeline filter where this internal field is being set. Having a final default route to catch these cases is key.

Setting __logType via Eval
The intent of this blog is not to cover all config fields in our Stream destination, I’ll save that for our official docs. Just a couple of other notables I’d like to touch on before we wrap this bad boy up.
Log Text Field: you need to pay special mind to this field. If this is not set, Stream will package up the entire log and send it as JSON. This may result in your logs not parsing correctly, as their logstash based parsers can be quite brittle. By setting this log text field, it will only forward what is in the field defined.
Namespace: if you’d like to be able to easily identify logs being sent by a particular Stream Google SecOps destination, adding a namespace may be what you’re after. This can be helpful if you need to distinguish locations where a single log source is coming from. It also functions similarly to log type in that you may set it to a static value per destination, or dynamically in your pipeline by creating an internal field named “__namespace”.
Testing Sending to Google SecOps
This test will allow you to send a sample Palo Firewall Traffic log which will parse correctly into UDM. The sample log is just a single line used to create a datagen. Once you have your datagen source configured (details on datagen sample file below), send it through a passthru pipeline to your Google SecOps destination.
In your Google SecOps destination, set your Default log type to “Palo Alto Networks Firewall” and your Log text field to “_raw” as you see below:

Sample log for datagen
From Stream’s sample data interface, you can use Import Data and paste this line in, break on the new line is ok > create a datagen file, and use the defaults for timestamp:
Nov 1 02:37:59 dc00-0000-pan.someurl.com 1,2022/11/01 02:37:59,001801026654,TRAFFIC,drop,2305,2022/11/01 02:37:36,192.168.0.111,192.168.0.255,0.0.0.0,0.0.0.0,DENYTheRest_From_Isolated,,,not-applicable,vsys1,Isolated_OldOS,LAN,ae2.88,,MFG-Log-Forward-Profile,2022/11/01 02:37:36,0,1,137,137,0,0,0x0,udp,deny,96,96,0,1,2022/11/01 02:37:36,0,any,,50382897056,0x8000000000000000,192.168.0.0-192.168.255.255,192.168.0.0-192.168.255.255,,1,0,policy-deny,22,30,0,0,,phca01-dc01-fw01-mfg-active,from-policy,,,0,,0,,N/A,0,0,0,0,69a75175-0f45-426b-b3a7-4637923f14d3,0,0,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,1969-12-31T17:00:00.000-07:00,0,0,unknown,unknown,unknown,1,,,not-applicable,no,no,0
The Results
Here is what properly parsed logs > UDM should look like when searching in Google SecOps:

Raw log search

UDM search
Get Started Today

Together, Cribl and Google SecOps provide a way for SecOps teams to support massive amounts of data for threat detection and response at scale. Now that you know how to implement a Google SecOps destination in Cribl Stream, it’s time to try it out!
Sign up for a free Cribl.Cloud account and get up to 1TB/day into Google SecOps for free.






