

If you’ve been around the observability world for the past few years, you’ve probably heard a few stats around data growth. Worldwide, data is increasing at a 23% compound annual growth rate (CAGR), per IDC. That means in five years, organizations will be dealing with nearly three times the amount of data they have today – generated by diverse and emerging sources, from data centers to cloud sources to edge computing.
At our recent Product roadshow, Samy Senthivel, Director of Observability Services for Autodesk, shared how despite starting with Cribl simply to streamline data ingest, Cribl is now a crucial component of each of their top IT and security priorities.
Like most sizable, established enterprises, Autodesk’s data infrastructure is extensive and complex. As the organization has grown, so has the volume and complexity of its logging data. Each business unit generates a vast quantity of operational data, and each unit derives market-specific context and value from the data it generates. Therein lies the challenge: With so many different types of data, multiple logging solutions, and SIEM (Security Information and Event Management) tools, Autodesk needed a better way to manage to get the right data to the right place in the right format – in a timely manner.
Enter Cribl. Before using Cribl Stream, the team used to spend all their working hours managing stakeholder requests to add new data sources or accommodate growing data volumes. Doing data mapping, managing version control for TAs (technical add-ons), and managing data models associated with those requests meant the team spent a lot of time running to stand still.
With Cribl Stream, they can be more surgical about what data goes where – without needing a PhD (or MD) to craft and manage data pipelines. Instead, Cribl’s free CCOE (Cribl Certified Observability Engineer) certification program with support from the Cribl Curious and Slack community enabled Autodesk to manage the complexity of onboarding and routing data to different locations and optimize their data ingestion process.
When ingesting data in Cribl, users have the ability to carve out repetitive or empty fields, break data streams into events, assign timestamps to events, enrich with static or dynamic events, and drop, suppress, or mask data. And all of this is possible to see in a preview mode before you commit any of your changes to the pipeline.
“The goal is to optimize the data. Our priority is to make the data more valuable, mark it up, add more,” said Sudha Kanupuru, DevOps Engineering Manager at Autodesk. “It’s not just about time savings and cost-cutting, it’s about getting more context to make better decisions.”
Now that their observability data has been unlocked (i.e., the team can effectively manage pipeline complexity and refine data ingestion), Autodesk has expanded their scope for Cribl and applied it to their top IT priorities:
General tool consolidation
Consolidating monitoring tools
Consolidation of APM tools
Consolidation of observability platforms
Backoffice transformation to replace legacy finance systems and enable observability for these systems
Multi-cloud initiatives
Log data optimization
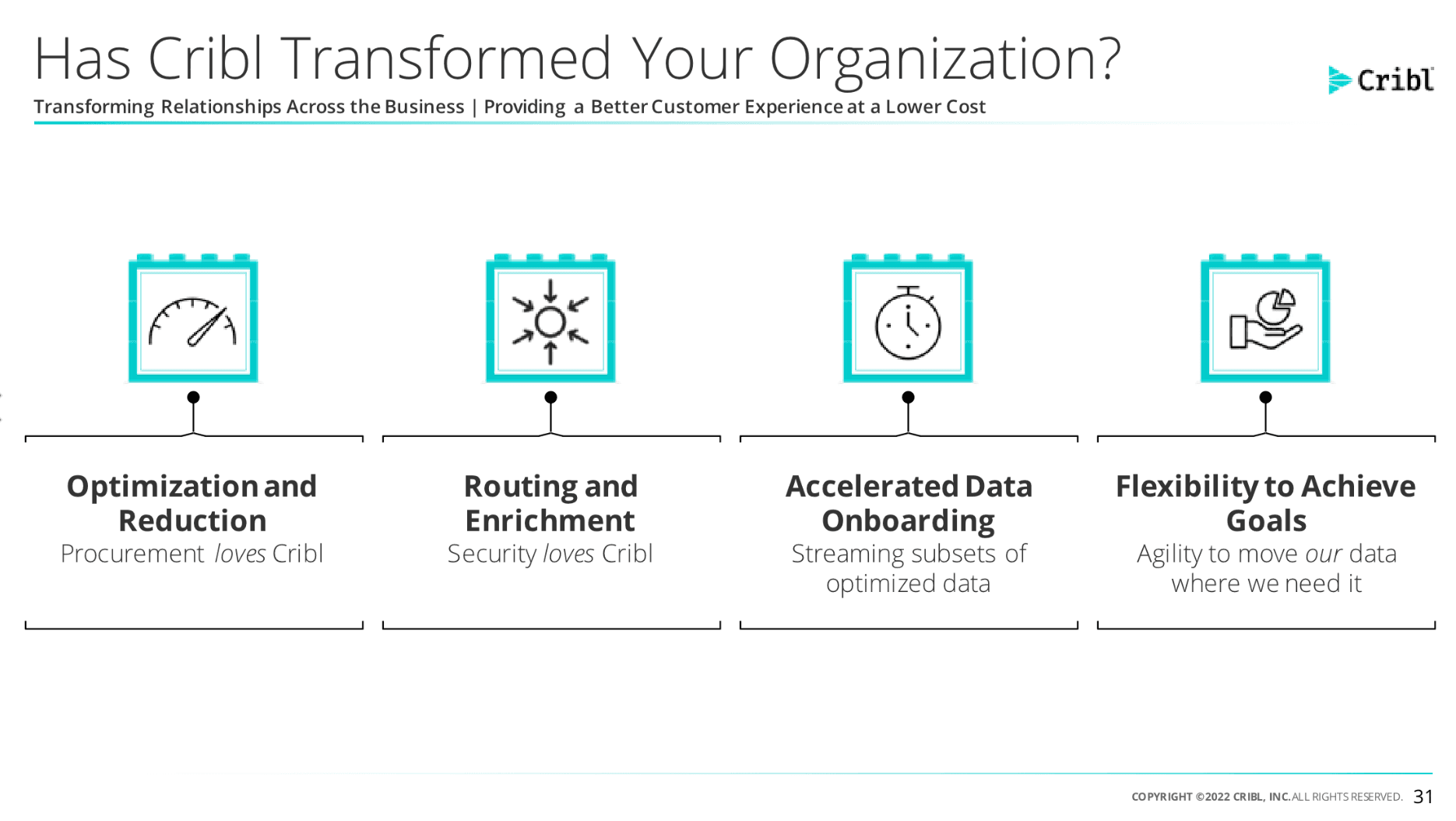
How has Cribl transformed operations at Autodesk?
Learn about other problems Autodesk solved in this customer highlight and who knows, maybe your business can implement an observability pipeline to route, optimize, and enrich data in flight while cutting costs and simplifying operations. It’s as easy as trying out this Cribl Stream 10-minute sandbox.
This blog is the first in a 13-part series of Cribl customer use cases. We’ll highlight common IT and security challenges and how Cribl has helped our customers overcome them. Have a challenge you’d like us to tackle? Have a solution you’d like to share? Hit us up in the #office-hours channel in Cribl Community Slack.






