

The Replay functionality in Cribl Stream fundamentally changes how organizations manage data by providing an easy way to ingest and re-ingest data into systems of analysis selectively. In addition to a little personal history about my introduction to Replay, we will walk through how to use this pioneering feature step by step.
Big Data Dreams – a Brief History of Replay
When the Cribl founders first described their plans for the feature to me in 2019, I was already sold on the incredible filtering, routing, and transformation features in Stream. Then, they started discussing how great it would be if I could stream less-vital events to an object store, bypassing my expensive Splunk storage. Or make my Splunk retention time very short, but allow easy replay of expelled events. None of that bucket-thawing spectacle. It seemed like a lofty goal. In the world of log analysis, eating your cake and having it too is just not the norm. I was skeptical.
“Yeah, sure. But what about when you need it?” I contested, “Re-ingestion is a pain in the… ” They interrupted me: “You’ll be able to selectively and easily replay data you want, back out of that object store into Splunk, any time you want, just as if it were arriving in the system fresh the first time. No custom code required. You’ll be able to specify – by host, source, time, or even raw log content – which events would be rejuvenated.”
“Not only that,” they continued, “your object store is much cheaper to dump data into than the SSDs in your Splunk cluster. You could simply dump a copy of all incoming data to an object store, and have longer retention for all your event data. Then, if data ages out of your log analysis platform, you could replay it in the same manner if it became vital to have again. And, hey, while we’re at it, you could do this via API calls, to automate event replay. Picture an event triggering an alert in your SIEM, which then makes an API call to Stream, to replay all the events related to the IP address in the trigger event for the last 30 days.”
Sure, why not. It will make me an omelet in the morning, too. I mean, it was their dream. So make it as big as you want, guys.
Fast-forward not even one year later, and they delivered the Replay feature in Stream. It’s real, and it’s fantastic.
How S3 Storage and Replay Works
For brevity, we’ll refer to the storage destination here as S3, although it could just as quickly be MinIO or many other options.
Format Considerations
You can write data out of Stream in either of two formats—JSON or raw:
JSON: The parsed event, with all metadata and modifications it contains when it reaches the Destination step, will be wrapped in a JSON object. Each event is one line. We refer to this as newline delimited JSON (aka ND JSON). For example, this is syslog data using the JSON format option:
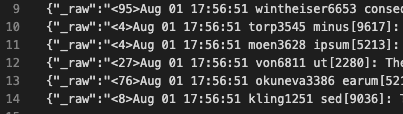
Raw: The content of the event’s _raw field, unparsed, at the time it reaches the Destination step, is written out in plain text. Each event is one line. This is the same syslog data, unmodified, and unparsed; using the raw option:
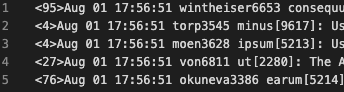
We recommend using JSON format, which is the default. Things like timestamp extractions and other vital enhancements should all have been performed already. Re-using that info makes sense and will make your Replay simpler. Notice the second screen cap above is literally just the original data. There are cases where maybe you want that; but usually having the pre-processed event is a good thing.
Writing the Data Out
The worker nodes stage files until certain limits are reached: Time open, idle time, size, or number of files. These settings are available under the Advanced tab in the Destination config. Once one of the limits is reached, the worker gzips the file and drops it into the object store. If you reach the open file limit, the oldest file will be targeted.
The settings for the S3 Destination also allow you to define how the uploaded files are partitioned. Host, time, sourcetype,… all the metadata is available to you for this purpose. When you’re replaying data from the store, these partitions will be handy to make your replay searches faster. We can map segments of the path back to variables, including time, that you can use to zero in on the exact logs you need to replay, without requiring checking _raw. In the how-to further down, I provide an example of the expressions we recommend.
Retrieving the Events
With events stored in an object store, we can now point Stream to that store to Replay selected events back through the system. We want to use data in the file path as an initial level of filtering to exclude as much data as we can from the download. Object retrieval and unpacking impose an enormous resource hit in the Replay process. Minimize your impact radius. Searching against _raw data is also possible but should be secondary to _time, sourcetype, index, host, etc.
More details: The leader picks one node to do the discovery exploration to find the potential objects that are in play. That list of targets is then doled out to the worker group to actually pull down the objects and examine them for content matches before executing final delivery. All worker nodes share the workload of retrieving and reinjecting the data.
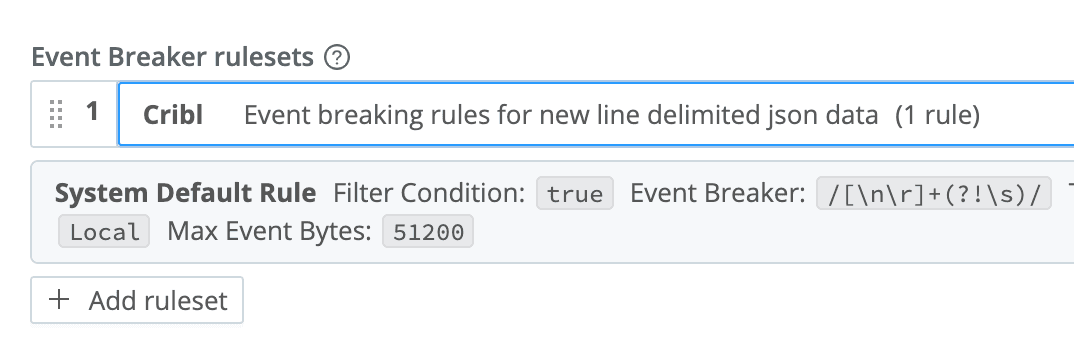
Finally, we need to process the data coming back to extract each event. As with any incoming data stream on a compatible Source, Stream can use default or custom event breaker definitions. In this case, we recommended above to use JSON as the format of the events when we write to disk, so we’ll use the Cribl event breaker ruleset on this source. This EB contains a newline-delimited JSON definition.
Putting it all together: How To Set Up and Use Replay in Stream
The Store
We usually talk about object storage, but any shared storage will work. It could be NFS or sshfs mounts (please don’t). As long as all the Stream nodes can see it, we’re ready to go. For the purposes of this post, let’s stick with an S3-compatible store.
You’ll need all the credentials, keys, secret keys, endpoints, etc., required to access the bucket you intend to use in your object store. The bucket should be able to grow to the size designed for your long-term archival needs.
S3 “deep-freeze” services like Glacier do not work with Replay.
The Destination Definition
In your Stream worker group config, create a new S3 Destination. The screenshot below is what mine looks like for this demo. Also, visit the Destination’s Advanced Settings tab to adjust the limits if needed. The defaults are fine for most situations, but we could be talking about 100+ files depending on your partitioning scheme. Make sure your staging area has enough space! Set the Max open files option appropriately. It overrides the size and time limits. We recommend that the staging area be its own volume, so you don’t fill up a more vital volume by mistake.
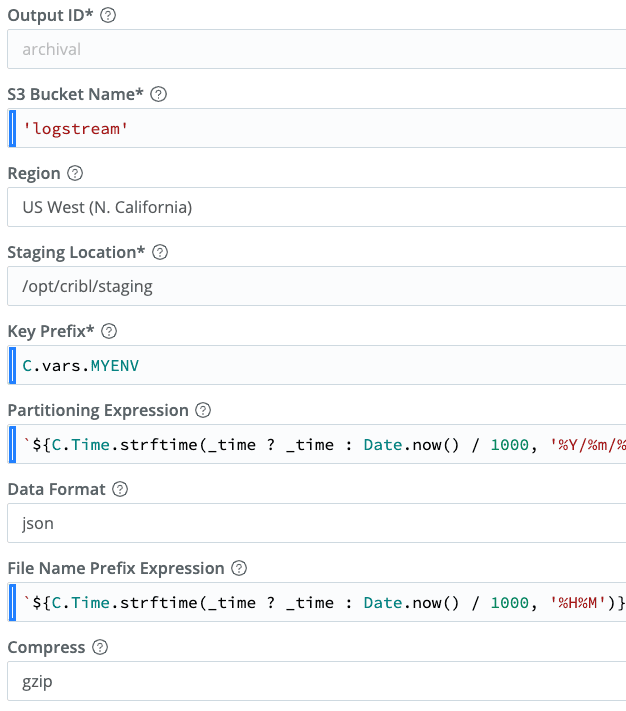
Included in this screen grab are the partitioning and file name prefix expressions. The full text of each is below. In a nutshell, we’re using time and other metadata to construct a path in the object store that will be useful to us at replay time:
Year/Month/Day/index/host/sourcetype/HHMM-foobar.gzPartitioning (1 line):
`${C.Time.strftime(_time ? _time : Date.now() / 1000, '%Y/%m/%d')}/${index ? index : 'no_index'}/${host ? host : 'no_host'}/${sourcetype ? sourcetype : 'no_sourcetype'}`
File Name:
`${C.Time.strftime(_time ? _time : Date.now() / 1000, '%H%M')}`
We’ve also included a Key Prefix from the Knowledge -> Global Variables. You could use this to partition your logs by environment or any other qualifier. Or not – it is not a required field.
The Archival Route
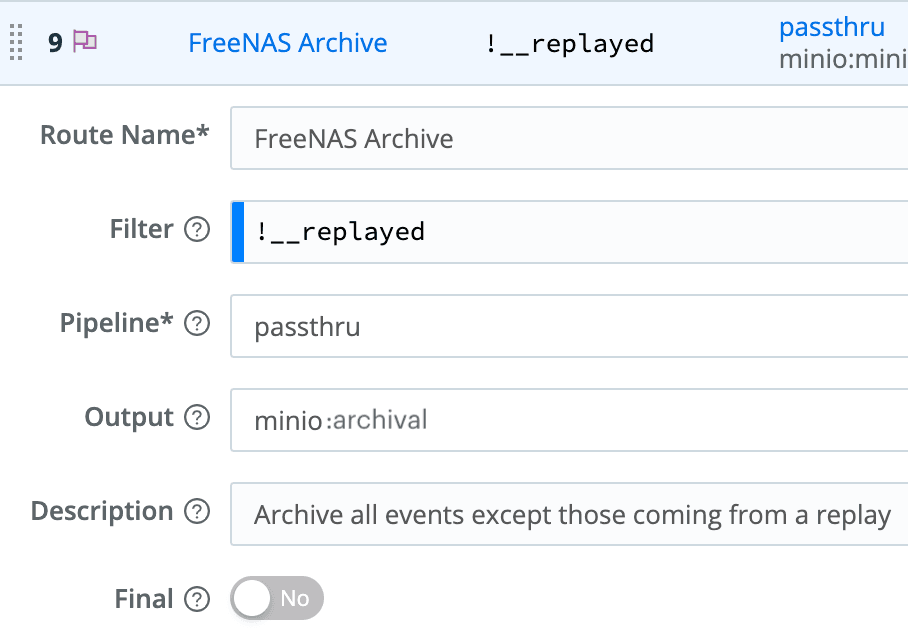
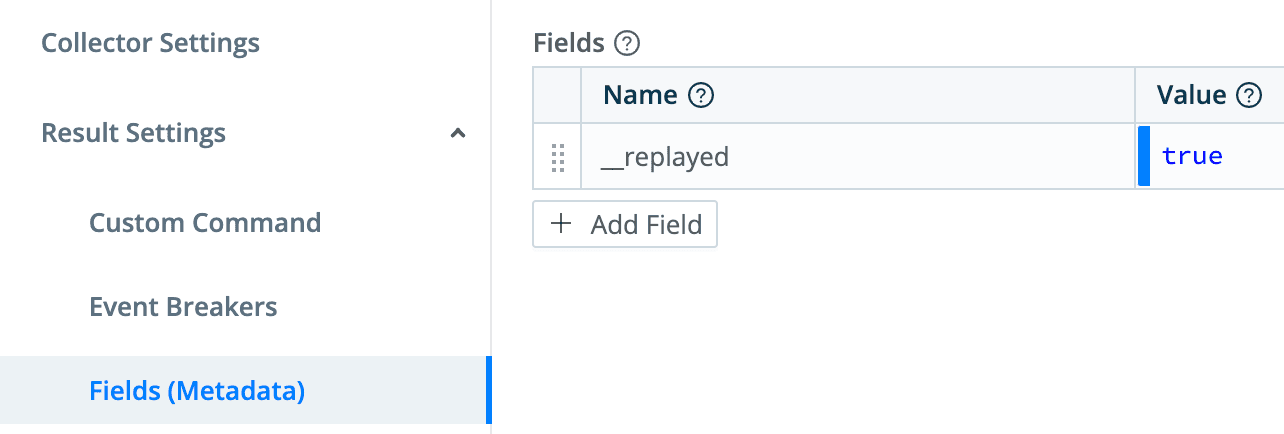
Create a new Stream route called Archival that matches everything you want to archive. In my case, I have it set to !__replayed and set this internal field in the source (see next step). Any event that is not coming from my defined Replay process will be archived. Select the passthru pipeline (or create an empty pipeline and use that). Select the S3 destination you created above. And finally, make sure Final is not set. We want data to flow through this route, not stop at it. I position the Archival route at or near the top of the route list. Save your work, commit, and deploy.
Once saved and deployed, data should be flowing to your object store. Check your work! Go to the Monitoring dashboard and select Destinations at the top. We want to see a green checkmark on the right side for your S3 destination. If it’s not green, find out why. You can also use an S3-capable browser, like Cyberduck, to check the files more manually. (Troubleshooting this is outside the scope of this doc.)

The Replay Collector
Go to the Collectors tab (pre v3.1) or Sources tab -> Collectors (v3.1+). Create a new S3 collector called Replay. Use the Auto-populate option to pull the configs in from your S3 destination.
We’ll need to establish the tokens to extract from the path on the S3 store. Below is our recommendation if you used the recommended partitioning scheme in the Destination definition above. If you chose to leave out C.Vars.MYENV, exclude the first segment below. It is vital this scheme match your partitioning scheme in the Destination definition. In the Path field:
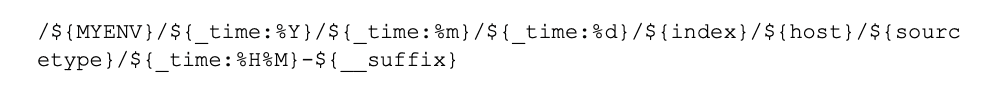
With these tokens defined, you can define filters that exclude/include relevant files before Stream is required to download and open them. This cuts down on the work required by orders of magnitude.
This is a core concept! We want to avoid having to open files to check for matches, by instead relying on key data in the path. Stream can immediately exclude, without downloading, the files that have no chance of matching our target events. Using _time, sourcetype, host and index, it can accurately zero in on the target files. Stream will download and interrogate the contents of what’s left after this high level filtering, and send the matches along to the routing table.
Finally, under Result Settings -> Event Breakers, select the Cribl ruleset. This ruleset understands how to parse the JSON packaged events stored by the Archive Destination.
To make it easier to identify events that have been replayed, create a field (Result Settings -> Fields) and set __replayed to true. You could use this to filter in routes and pipelines later, but since it’s a double underscore field, it’s internal only. It won’t be passed on to your final destinations. In a previous step we use it to prevent replayed events from being re-archived.
Save it. Commit and Deploy.
Testing a Replay
After you’ve accumulated some data in your S3 store, head over to Pipelines and start a capture. For the filter, use __replayed and run it for 300 seconds, 10 max events. Once it’s running, in a new browser window, navigate back to Collectors and run your Replay collector. Filter on true, and set Earliest time to -1h and Latest to now. You can run it in Preview mode to make sure you get results, then come back and do a full run; or just do a full run right off the bat if you’re confident. With a running job, you can click on the job ID to follow its progress. You can also pop back over to the Capture browser window or tab, and you should see events showing there.
In a full run, the events will proceed through your routes as normal, and land wherever your original routes and pipelines dictate. In my case, they landed in Splunk, and I could easily see duplicate events, EXACT duplicate events, in the timeframe defined in the collector job (the last 1 hour).
Once defined, the collector can be controlled via scheduling, manual runs, or API calls. And in actual use, you’d want to fill out the collector’s Filter expression to meet your needs.
Conclusion
The Replay feature in Stream is a true game changer for anyone managing digital exhaust data at scale. By separating your system of retention from systems of analysis, you can optimize your budget in ways not possible before. And since the archived data is stored in an open format, you’re free to use it however you like.
We offer free training with live Stream instances, a free-to-use cloud instance of your very own, free downloads, and a free tier of ongoing usage.
True story: I was so excited at all the Stream features, and at Cribl’s demonstrated excellence, that I quit my job in spring of 2021 to join this amazing team. If you’d like to work with super-sharp people in an exciting young company, we’re hiring.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.







