

What?
Global Keyword Search (aka CLUI) was introduced in LogStream 2.4.0. This feature enables the user to press Ctrl+K (all platforms) or Cmd+K (MacOS) and search across LogStream objects by keyword. Before CLUI was introduced our users had no way to retrieve search results from multiple resources/endpoints at the same time. This meant search results coming from multiple single-endpoints, such as, Sources, Destinations, Collectors, Routes, Pipelines, Functions, Knowledge Libraries, etc. would would force them to go into individual pages and search them one by one, creating unnecessary overhead and non-value-add processing steps just to collect all that required data. At Cribl, we value Customers first, always, hence we came up with a better and more streamlined solution featured in CLUI.
The figure below demonstrates the application of CLUI via a single query where the search results from different endpoints are returned into a single screen.
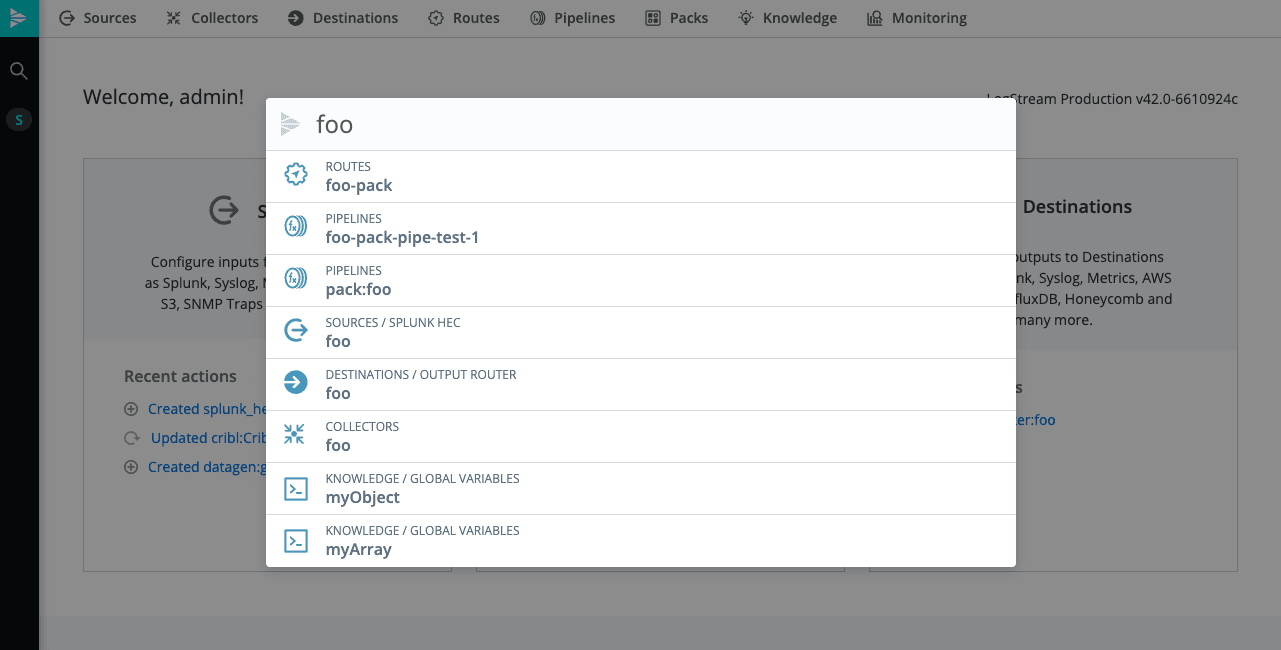
Why?
To power this search engine and provide customers with the best possible experience, we needed to come up with a way to get those results while meeting a lot of expectations:
Secure and respecting RBAC Roles
Less overhead and processing time
Optimize performance by minimizing response time and preventing unneeded serialization
Customized server instance response without direct connection to the server, which prevents unnecessary burden to the whole system
Manageable in the long run
How?
Analyzing best approach
The first thing that comes to mind is to directly access the data layer. It would work, but we also had to keep in mind security, visibility and access managed by RBAC Roles.
Choosing to send requests to multiple existing endpoints, allows us to reuse existing functionalities, validators and middlewares without implementing any additional changes to them (aka DRY). Criblianians, however, are not dry or lazy; we goats have flavor and real swag! We work hard to earn our goats (who we absolutely love by the way! Have you heard about our goat mascot Ian? Read more about Ian and our origin story here.)
The DRY Approach
The simplest, quickest and most obvious way to do it is to send standard HTTP requests to endpoints providing us with data. It matches our DRY philosophy and reuses all existing endpoints, middlewares and validators.
The diagram below explains the data flow of a single query request from a user and how it triggers multiple single-point API requests before returning search results.
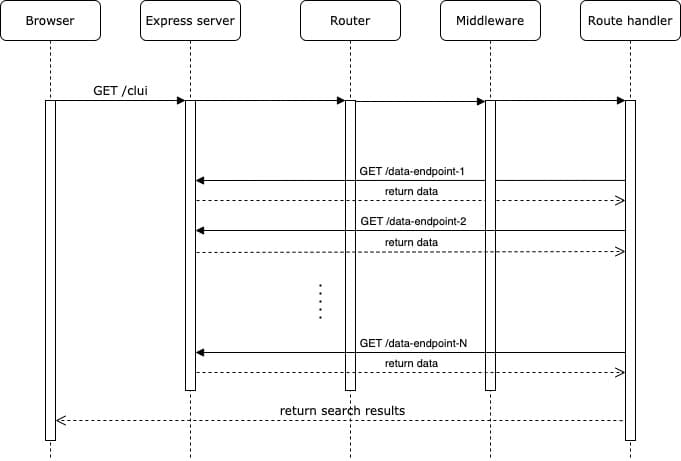
The code below shows a simplified example of how we can trigger standard HTTP requests from route handler to another endpoint on the same server.
const httpRequest = (url) => {
return new Promise(async (resolve, reject) => {
const req = http.request(
url,
{
headers: {
'Content-Type': 'application/json; charset=utf-8'
},
},
res => {
let resData = '';
res.on('data', function (chunk) {
resData += chunk;
});
res.on('end', async function () {
if (res.statusCode === 200) {
resolve(resData);
} else {
reject(res.statusMessage);
}
});
res.on('error', reject);
},
);
req.on('error', reject);
req.end();
});
};
app.get('/internal-simple', async (req, res) => {
const internalResponse = await httpRequest(`${apiUrl}/foo`);
res.json(JSON.parse(internalResponse));
});The code above allowed us to match all the requirements, but did not account for performance. When implemented, each request opened up a new connection to the server. This was manageable when we submitted queries with 1 or 2 requests. However, when tested with 20 or more requests for each search query (which is a typical load for our customers) it led us to performance issues, drastically increasing search response time and unnecessarily overburdening the entire system.
The GOAT Approach
The GOAT solution was to send internal express requests, by making requests directly to the router without creating any new connections to the server.
The diagram below explains the data flow of a single query request from a user, and how it directly communicates with the router multiple multiple times without making connections to Express server, before returning search results.
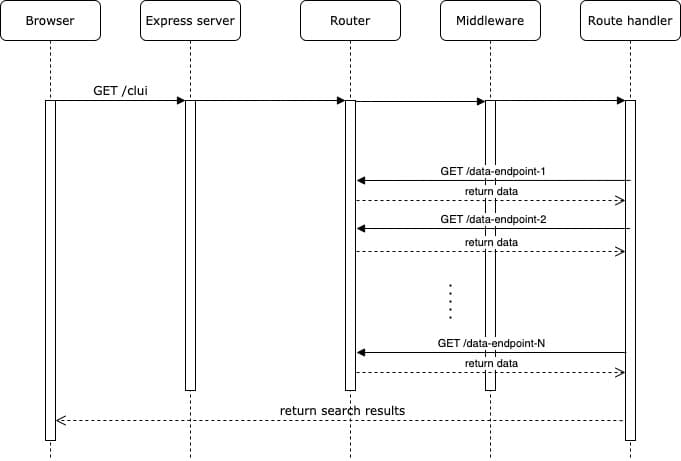
Code below shows a simplified example of how we can directly send requests to the router while not having to create a new connection to the Express server.
Crucial part of this approach is replacing standard server response with an instance of our customized response class. It’s important to catch and handle all write and end executions to follow our custom pattern instead of default behaviour. Such approach also allows us to do some additional optimizations, e.g. prevent unneeded serialization which will be done anyway when returning CLUI response.
class InternalRestResponse extends http.ServerResponse {
promise;
#resolve;
#reject;
#content;
constructor(req) {
super(req);
this.promise = new Promise((resolve, reject) => {
this.resolve = resolve;
this.reject = reject;
})
}
// override json to prevent unneeded serialization in non proxy responses
json = (result) => {
this.resolve(result);
}
// override end which will be executed in case of an error or successful RESTProxy request
end = () => {
if (this.statusCode === 200) {
try {
this.resolve(JSON.parse(this.content));
} catch (e) {
this.statusCode = 500;
this.statusMessage = e.message;
this.handleError();
}
} else {
this.handleError();
}
}
// handle chunks from RESTProxy request
write = (...attrs) => {
const cb = typeof attrs[1] === 'function' ? attrs[1] : attrs[2];
const encoding = typeof attrs[1] === 'function' ? undefined : attrs[1];
this.content += attrs[0].toString(encoding);
cb?.();
return true;
}
writeHead = (statusCode) => {
if (statusCode !== 200) {
this.handleError();
}
return this;
}
handleError = () => {
this.reject({
code: this.statusCode,
message: this.statusMessage,
});
};
}
const httpInternalRequest = async (originalReq, url, opts = {}) => {
const req = new http.IncomingMessage({});
Object.assign(req, {
url,
method: 'GET',
headers: originalReq.headers,
httpVersion: originalReq.httpVersion,
httpVersionMajor: originalReq.httpVersionMajor,
httpVersionMinor: originalReq.httpVersionMinor,
}, opts);
const res = new InternalRestResponse(req);
app.handle(req, res);
return res.promise;
};
app.get('/internal-final', async (req, res) => {
const internalResponse = await httpInternalRequest(req, `${apiUrl}/foo`);
res.json(internalResponse);
});A fully working sample app is available under https://github.com/lukaszwilk/internal-express-requests.
The fastest way to get started with Cribl LogStream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using LogStream within a few minutes.






