
Pleased to introduce our v1.2 release focused on expanding ingestion and delivery capabilities. It continues our promise to deliver added intelligence and control over your data in real-time by adding support for new sources and destinations, Windows deployments, new functions including machine learning powered timestamp recognition, and faster lookups.
New Sources
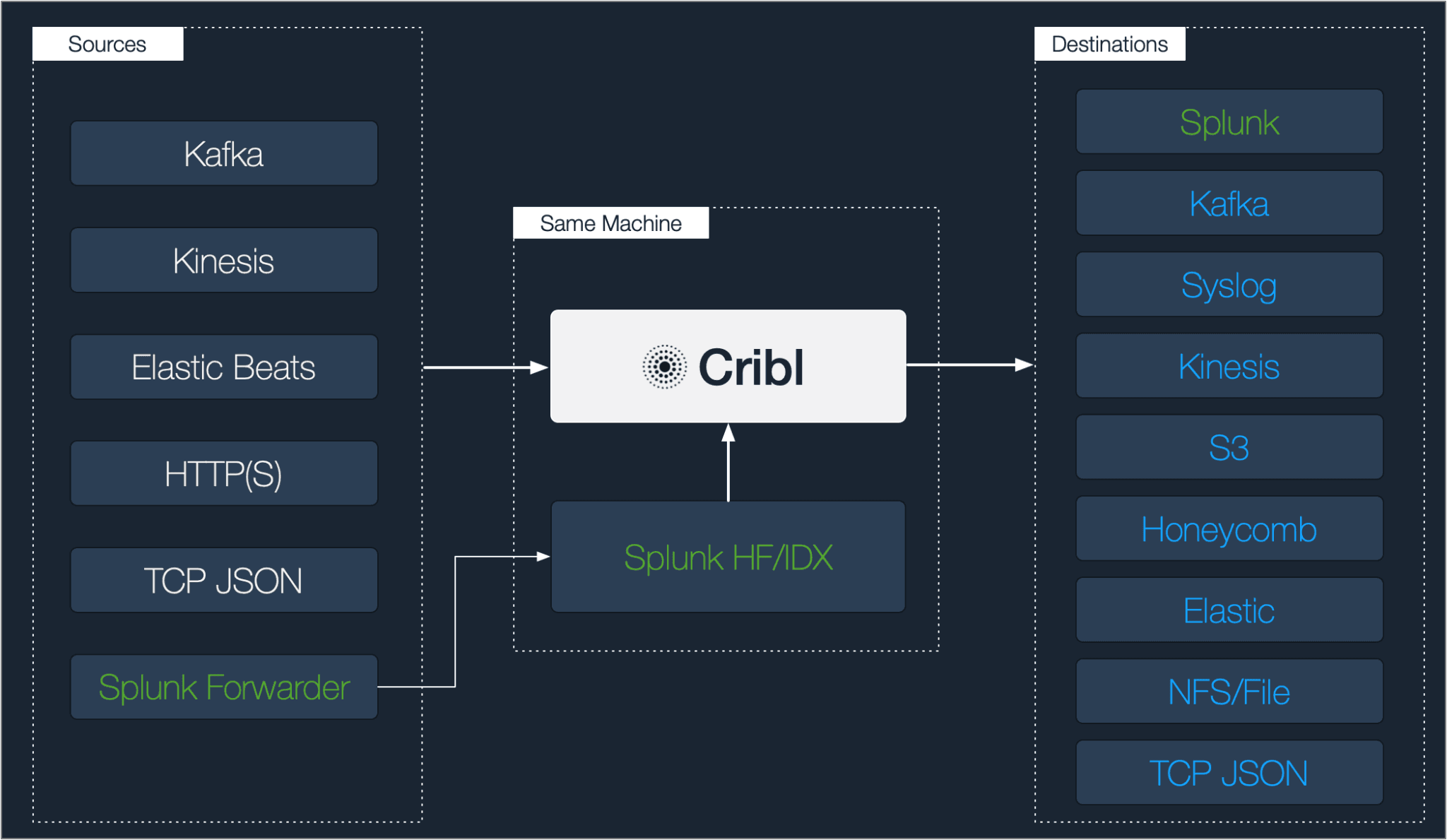
Apache Kafka
This version adds support for picking up data from Apache Kafka. Customers can now point Cribl to their Kafka brokers and start reading from multiple Topics. Authenticated and TLS connections are also supported.
Amazon Kinesis Streams
This version adds support for picking up data from Kinesis Data Streams. Both, IAM Role credentials and plaintext AWS keys methods can be used to connect to Kinesis. Gzip compression of records is automatically detected and various formats are supported; Cribl, CloudWatch Logs, Event Per Line, and New Line JSON.
New Destinations
Apache Kafka
With this version, a Cribl pipeline can send data to an Apache Kafka topic. Both JSON and Raw formatting is supported. Gzip compression is also available out of the box.
Syslog
This version also adds a highly requested destination; syslog. Syslog over TCP is supported on two formats: RFC3164 and RFC5424. Advanced settings for TLS and back-pressure behavior are also available.
TCP JSON
This version adds support for high performance receivers using our simple TCP JSON protocol. TLS and authentication tokens are also supported.
Windows Support
With this version we added support for running Cribl on Splunk forwarders on Windows. The processes that Cribl requires now is started using Python that ships with Splunk.
New Functions (beta)
Auto Timestamp
Auto Timestamp is a machine learning timestamping function that allows users to auto extract timestamp fields from event payloads. The longer the function runs on a stream, the more it learns and the faster and more accurate it gets at detecting timestamps.
Extract key=value
This function will look in an event for k=v pairs and convert them to properly structured JSON object.
Faster Lookups
Lookups using static .csv files have a significantly improved performance. With faster parsing and targeted low level optimization lookups are now scalable in the +million rows. Hot reloading and compression (.csv.gz) is also supported which helps automated distribution of tables.
If you like what we’re doing come and check us out at Cribl.io. If you’d like more details on installation or configuration, see our documentation or join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to help you!






