

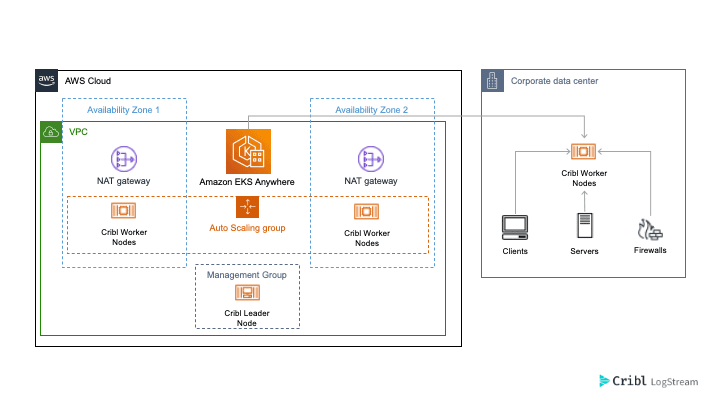
We are very excited to be able to work with the AWS EKS Anywhere program which helps customers mitigate the complexity of managing, deploying and operating an on-premises Kubernetes cluster. Cribl Stream can simplify collecting, shaping, routing and enriching logs and metrics and send them to any destination. Customers can take advantage of this service to help deploy and run Cribl Stream Worker Nodes in an on-premises Kubernetes cluster. A Cribl Leader Node can then manage the configurations of the Worker Nodes while the AWS EKS Anywhere service manages the underlying control plane.
We love Kubernetes, and it’s pretty much our default approach running anything internally at Cribl these days. We also know that our customers would like to run Cribl Worker Nodes in their on-premises Kubernetes cluster. With a simple YAML deploy file, you can get a single Cribl Stream instance running or deploy a fleet of worker nodes on your Kubernetes cluster. We have also made available helm charts that can be used to deploy either a Worker Group or a Leader Node on a Kubernetes cluster.
What is Kubernetes?
If you’re not familiar with Kubernetes (often referred to as K8s), it’s a container orchestration system that makes it relatively easy to deploy container-based applications in a scalable, manageable way. It uses a declarative approach that promises to let you tell the system how you want it to end up, and let it figure out how to get there. As is often the case, that simple goal becomes incredibly challenging when it hits the real world, so K8s ends up being a very complex system.
At Cribl, our K8s clusters are running on AWS EKS and AWS EKS Anywhere. For our EKS Anywhere cluster running on VMWare, we want to run some worker nodes and have them available to process data from our on-premises lab. We used a deploy YAML file to setup 3 worker nodes running locally:
apiVersion: apps/v1
kind: Deployment
metadata:
name: cribl-logstream
labels:
app: cribl
spec:
replicas: 3
selector:
matchLabels:
app: cribl
template:
metadata:
labels:
app: cribl
spec:
containers:
- name: cribl
image: cribl/cribl:latest
ports:
- containerPort: 9000
- containerPort: 4200
Since we have a ‘shared-nothing’ architecture, it allows us to scale the Cribl Worker Nodes to grow as the amount of data that needs to be processed increases. Once the surge of data collection has completed, we can reduce the number of worker nodes without impacting our deployment.
Leverage Cribl Stream to finally migrate your on-premises data to the cloud. You can also use Stream to send properly formatted data (e.g., CIM, ECS) to your SIEM while sending a raw copy to an AWS S3 bucket for long term storage. The possibilities for your data are endless – and with Cribl Stream and AWS EKS-Anywhere, you can now Unlock the Value from all Observability Data.
For more information on how Cribl Stream works with Amazon Web Services, check out the Solution Brief entitled Future-proof your Business with Cribl Stream + AWS Web Services. For more information on AWS EKS Anywhere, check out this blog post from AWS.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.







