Cribl LogStream can enable customers to capture an immediate return on investment merely by routing data from more expensive systems of analysis to less expensive systems of retention, but Cribl LogStream’s value doesn’t start and stop with routing.
By leveraging just one of Cribl’s dozens of pre-engineered functions, customers can enrich their data with valuable context, reduce the noise in their data with precision, and address data access challenges specific to their organizations.
The specific challenges covered here:
- How can I convert cryptic codes into plain English?
- How can I sort events from the same log file into different sourcetypes based on their content?
- How can I untangle events into different indexes, based on their CIDR range?
Note that you can walk through all three use cases in a hands-on fully functional lab environment, including:
- a full instance of Cribl LogStream
- all the sample data sources and lookup tables you’ll need
- detailed instructions using our sandbox.
Access the Cribl Sandbox Lookups Three Ways
Lookup #1: Turn Cryptic Codes into Readable Values
| Data Source |
Apache Access Logs |
| Match Mode |
Exact |
| Lookup Fields |
Match numeric status code (“404”) with description (“File Not Found”) and type (“Client Error”) |
| Benefits |
- Improves readability.
- Contextualizes status codes.
- Uses context to sample low-value events and reduce noisy data. volume
|
Ever wonder how you could make it easier for actual humans to understand the reports, alerts, and dashboards created from the cryptic codes found in logs? In this example, we’ll use standard Apache access logs and a lookup table that exactly matches the status code in a given event to its associated description and type. See table below.

After adding the CSV lookup file to your Cribl LogStream instance, you will configure the lookup to exactly match the status code field and designate “status_description” and “status_type” as the output fields.
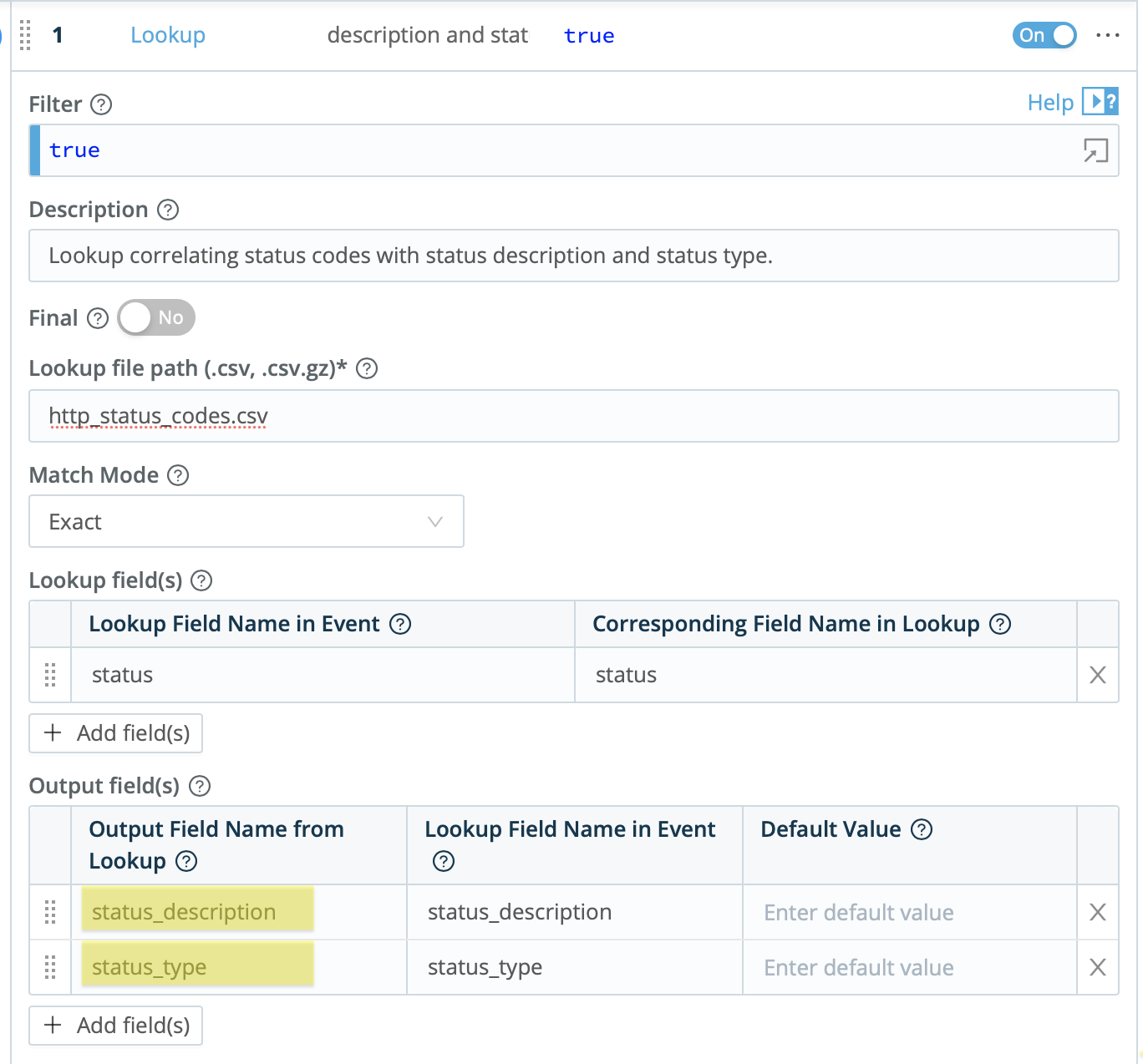
This will generate an enriched event that looks something like the below image. Note the added “status_description” and “status_type” fields. Those fields will be passed along with the rest of the event to the destination of choice, and can be used to make any reports or dashboards using these events more readable and clear.
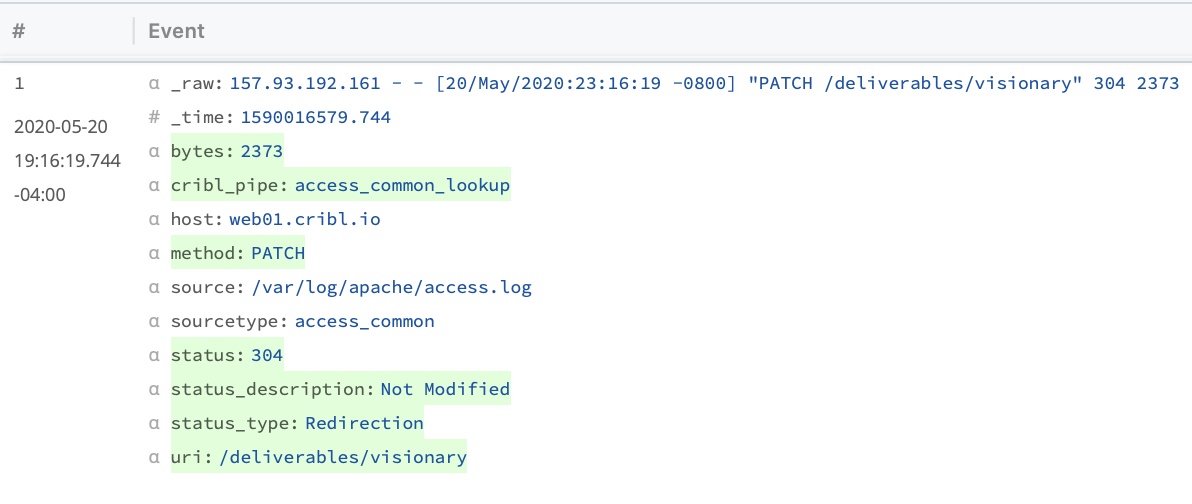
Finally, the Sample function can be used to reduce the number of (mostly redundant) successful events, and thereby reduce overall data volume. This helps you capture value both in reduced license waste and reduced infrastructure costs.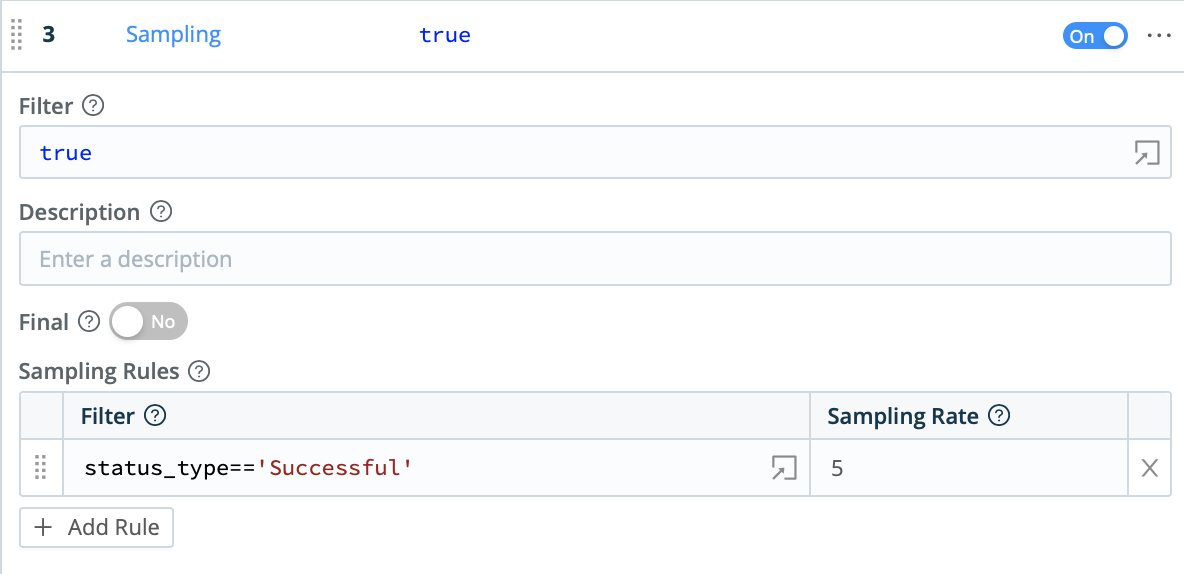
So, with just the Lookup and the Sample functions, we transformed codes into human readable values, used those values to selectively sample less-relevant data, and reduced overall data volumes.
Lookup #2: Sort Similar Events into Different Sourcetypes, Even if they have Different Structure
Now, let’s be a little more innovative in how we use the lookup function. In this scenario, we’re emulating a core function of Splunk’s Palo Alto TA to sort events in the same log into different sourcetypes.
| Data Source |
Palo Alto Firewall Logs |
| Match Mode |
Regular Expression |
| Lookup Fields |
Match a word in the log (“THREAT”) to a sourcetype (“pan:threat”). |
| Benefits |
- Accurately parses differently-structured logs
- Provides easy-to-use interface to preview and perfect modifications before events are sent to production data stores.
- Reduces bloated architectures by obviating the need for Splunk heavy forwarders.
|
With our last example, we could use an “exact match” lookup because, while each event in that source had different values, the overall structure of each event was the same. That meant that we could extract fields from every event with the same regular expression and be confident we were capturing the right fields and working with the right key value pairs.
With this example, we have no such luxury.
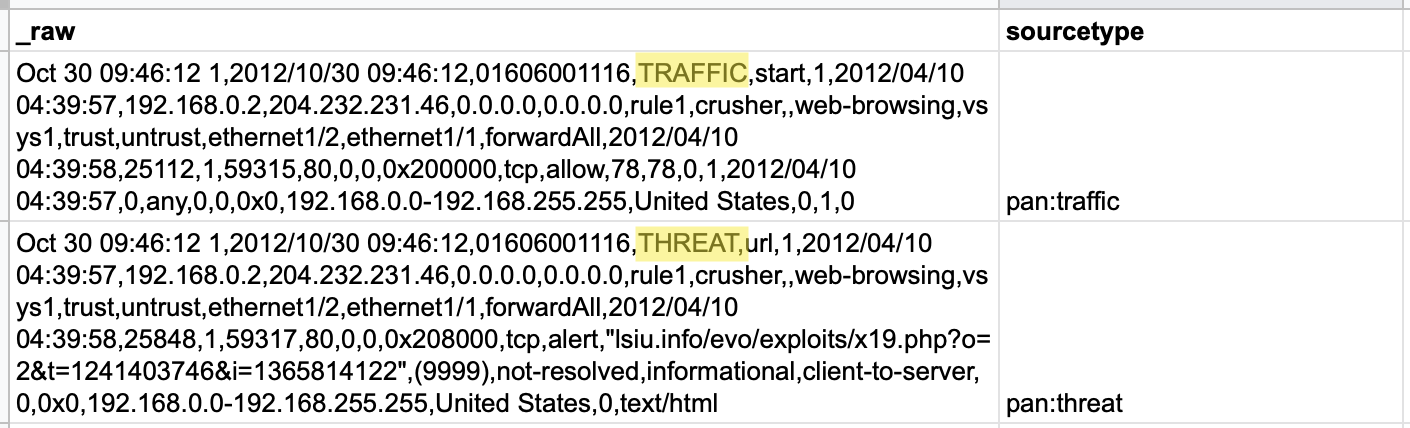
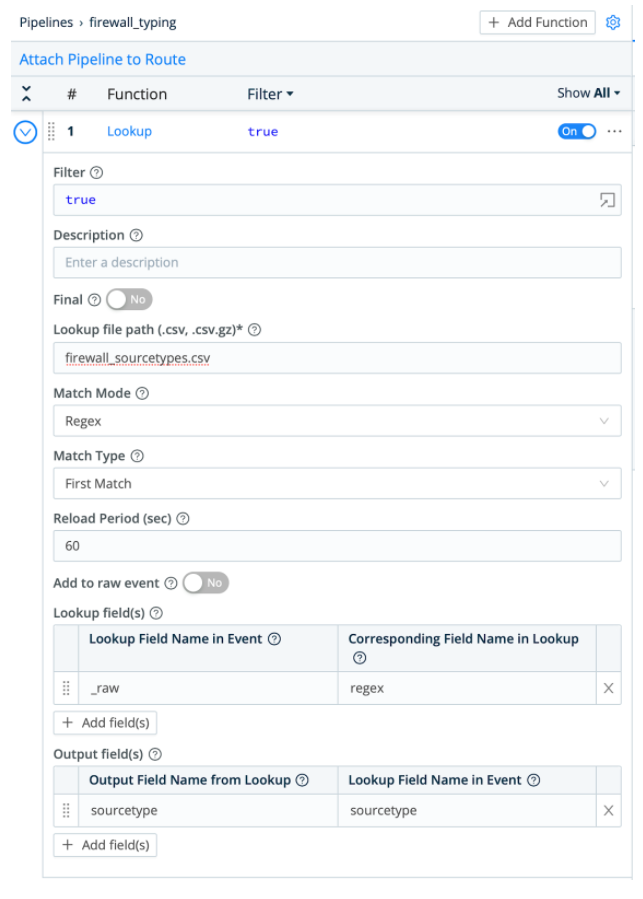
Here, our sample data comes from firewall logs, where “threat” events — comma-separated events with 41 fields — are intermingled with “traffic” events — comma-separated events with 46 fields. No single regular expression could capture the correct values from both types of events, so we’ll need to leverage the regular expression option in Cribl LogStream’s Lookup function.
In this scenario, we want to assign the correct sourcetype to each event before we send it along to Splunk. This reproduces some of the event modification Splunk customers usually perform with a Splunk heavy forwarder and a technical add-on. Using Cribl LogStream for this kind of event modification can — for many customers — enable them to retire some or all of their Splunk heavy forwarders, simplifying their Splunk architecture and reducing their overall infrastructure costs.
This time, the CSV lookup table looks a little different:
regex,sourcetype
"^[^,]+,[^,]+,[^,]+,THREAT",firewall_threat
"^[^,]+,[^,]+,[^,]+,TRAFFIC",firewall_traffic
Notice that the first “column” of each line (the part before the first comma, e.g. “^[^,]+,[^,]+,[^,]+”) is a regular expression instead of a literal phrase. Cribl LogStream’s Lookup function enables you to change the match mode from “Exact” to “Regular Expression” to leverage these regular expressions.
This results in both of these events being associated with the correct sourcetypes, even though one contains “TRAFFIC” and is 41 fields and the second contains “THREAT” and is 46 fields.
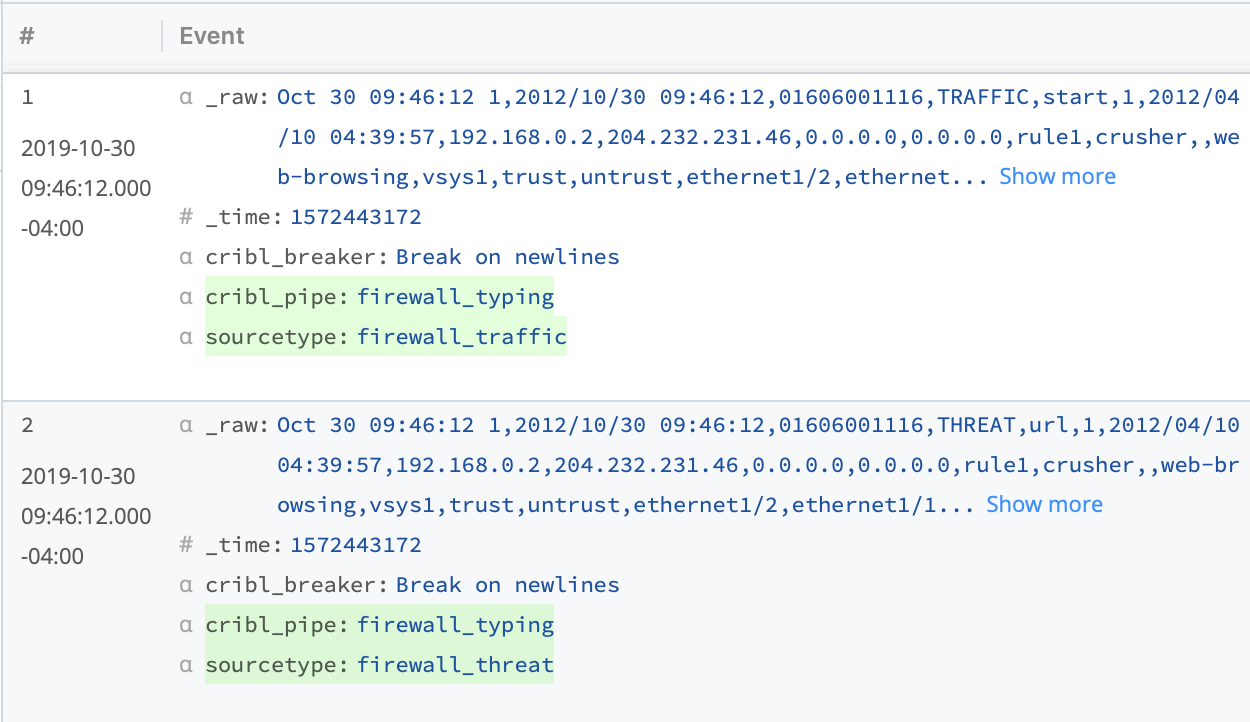
With just a single function, we untangled similarly but not identically structured events, and routed them for more efficient searching in Splunk.
Customers who use Splunk’s Heavy Forwarders for the purpose of assigning different sourcetypes to interleaved events could, in some cases, replace the Heavy Forwarders in their environment with less-process-intensive instances of Cribl LogStream – and savor significant returns on their Cribl investment.
Lookup #3: Group Events by Subnet
Our final challenge was inspired by a customer request: Can Cribl LogStream help us sort incoming events by project group? In this customer’s network, each project group was associated with a given subnet, and they wanted to be able to sort the millions of intermingled events in their NetFlow logs into different indexes, so that only members of a given project group could view relevant events. They also wanted to filter out events that were not sent from any of their project groups, which could save significantly on their infrastructure and licensing costs.
| Data Source |
Netflow Events |
| Match Mode |
CIDR Match |
| Lookup Fields |
Match an IP address (“192.168.0.111”) to the correct subnet (“192.168.0.64/26”) and associated team (“Team C”). |
| Benefits |
- Elegantly group events by subnet to support business needs, security requirements, or other role-based access control requirements.
- Reduce unnecessary data volume by removing events not associated with a given subnet.
|
In order to accomplish this, we leveraged the Lookup function’s ability to key off of CIDR ranges. In the example we’ll work on here, their network is divided into four subnets, each associated with a given team.
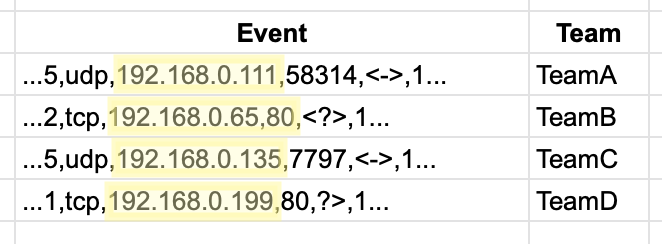
These events will be matched against a CSV lookup table that, like the previous example, looks a little peculiar. Instead of presenting as a literal match, the first part of each line (i.e. “192.168.0.0/26”) has a series of CIDR expressions.
cidr,team
192.168.0.0/2t6,TeamA
192.168.0.64/26,TeamB
192.168.0.128/26,TeamC
192.168.0.192/26,TeamD
When configuring the Lookup table, you will then choose “CIDR” for the match mode.
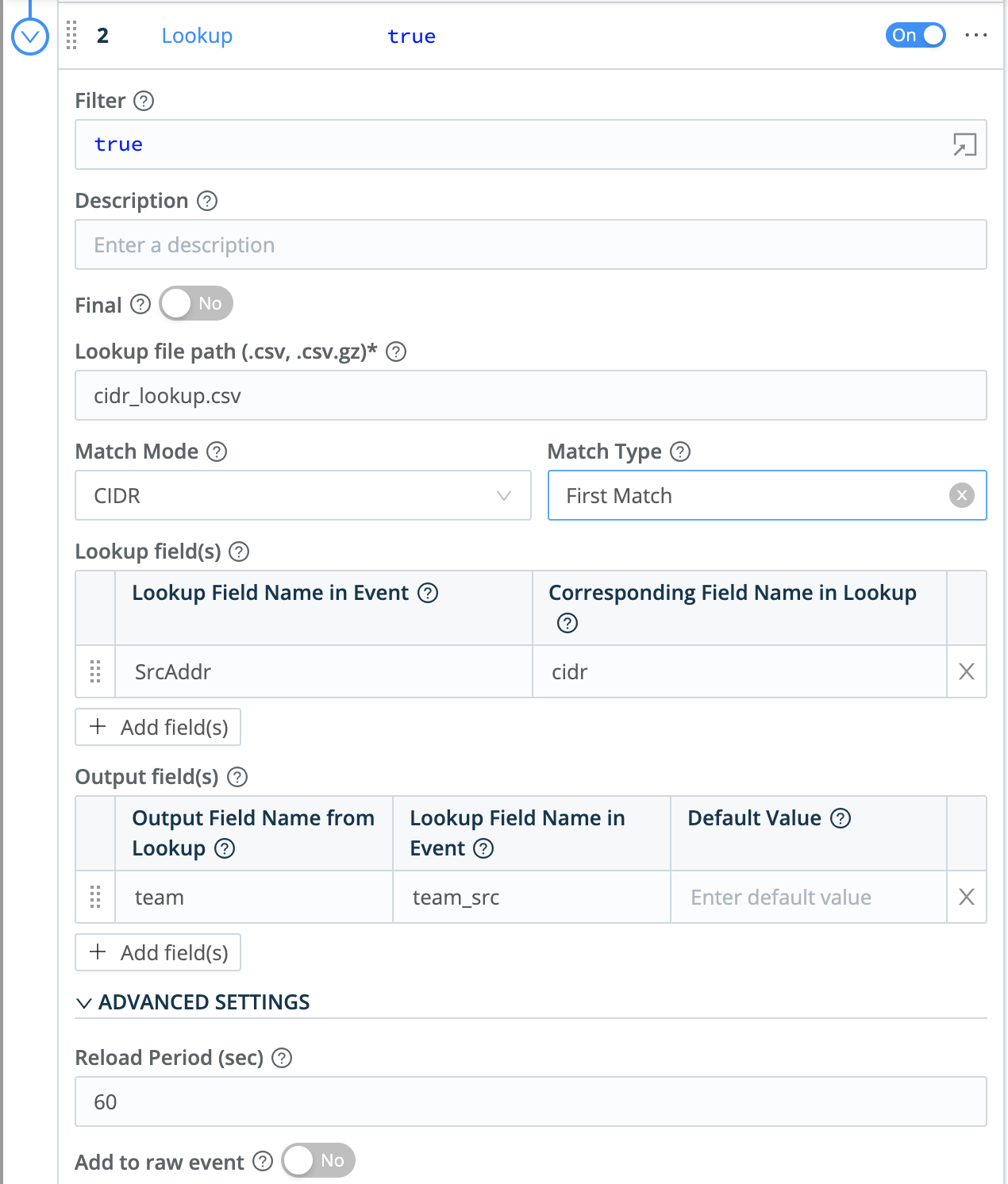
And now that each event is associated with the correct team, a simple Eval function will redirect the event to the correct index in Splunk, Elastic, or any other system of analysis that supports role-based access control based on the index.
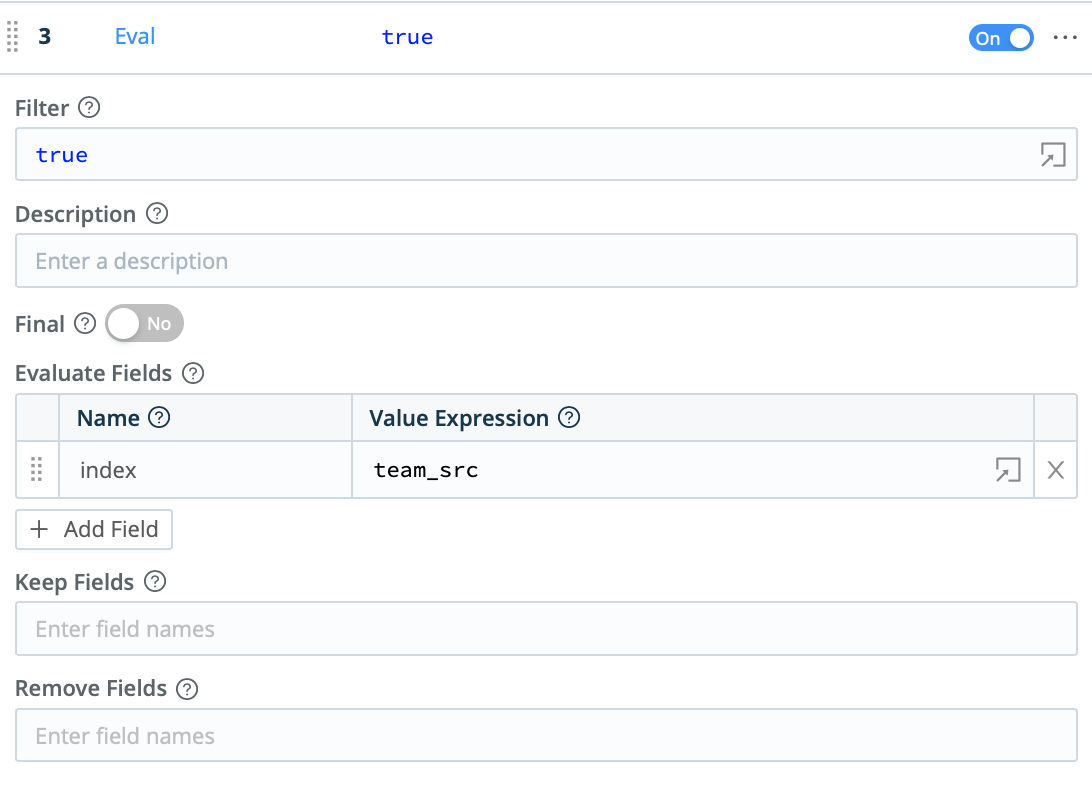
Finally, the Drop function can be used to filter out events associated with subnets that are not part of the scope of analysis. Those events can be cloned into a different route in Cribl LogStream, and preserved in less expensive storage like S3 or AWS Glacier.
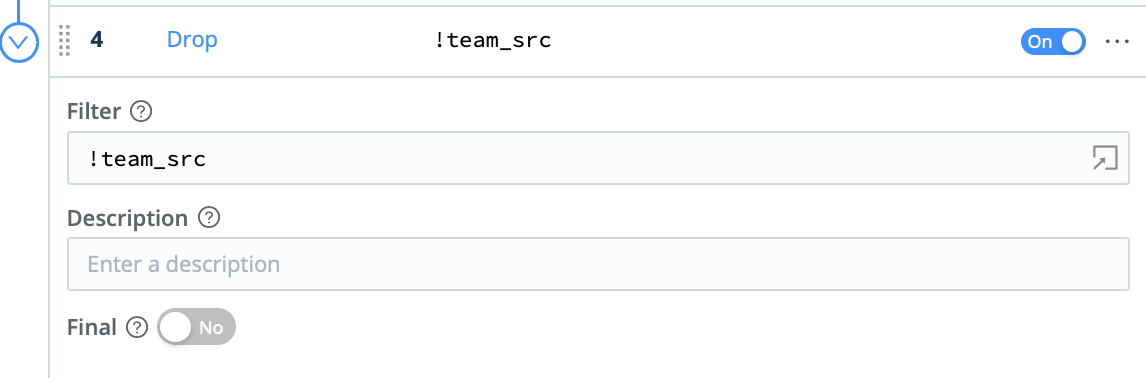
With these three functions, we sorted interleaved events into groups that make sense for our customers’ business needs. We also provided customers a return on their Cribl LogStream investment by helping them filter out events they don’t need – reducing downstream licensing and infrastructure costs.
Conclusion
Cribl LogStream comes with over two dozen pre-engineered functions, each of which provide as much potential as the Lookup function we examined today.
We again invite you to explore these use cases in our Sandbox. We look forward to hearing from you about the creative and functional ways you have used Cribl LogStream to reduce the noise and improve the quality of your data.





























